一、xml的jsoup解析
1 操作xml文档,将文档中的数据读取到内存中
1.1、 操作xml文档
- 解析(读取) : 将文档中的数据读取到内存中 写入:
- 将内存中的数据保存到xml文档中。持久化的存储
1.2、解析xml的方式:
DOM: 将标记语言文档-次性加载进内存,在内存中形成一颗dom树
优点:操作方便,可以对文档进行CRUD的所有操作*缺点:占内存
SAX: 逐行读取,基于事件驱动的。
优点:不占内存。
缺点:只能读取,不能增删改|
1.3、xml常见的解析器:
- JAXP : sun公司提供的解析器,支持dom和sax两种思想
- DOM4J :一款非常 优秀的解析器
- PULL : Android操作系统内置的解析器,sax方式的。
- Jsoup: jsoup是一款Java的HTML 解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API, 可通过DOM, CSs以及类似于jQuery的操作方法来取出和操作数据。
1.4、Jsoup解析实践
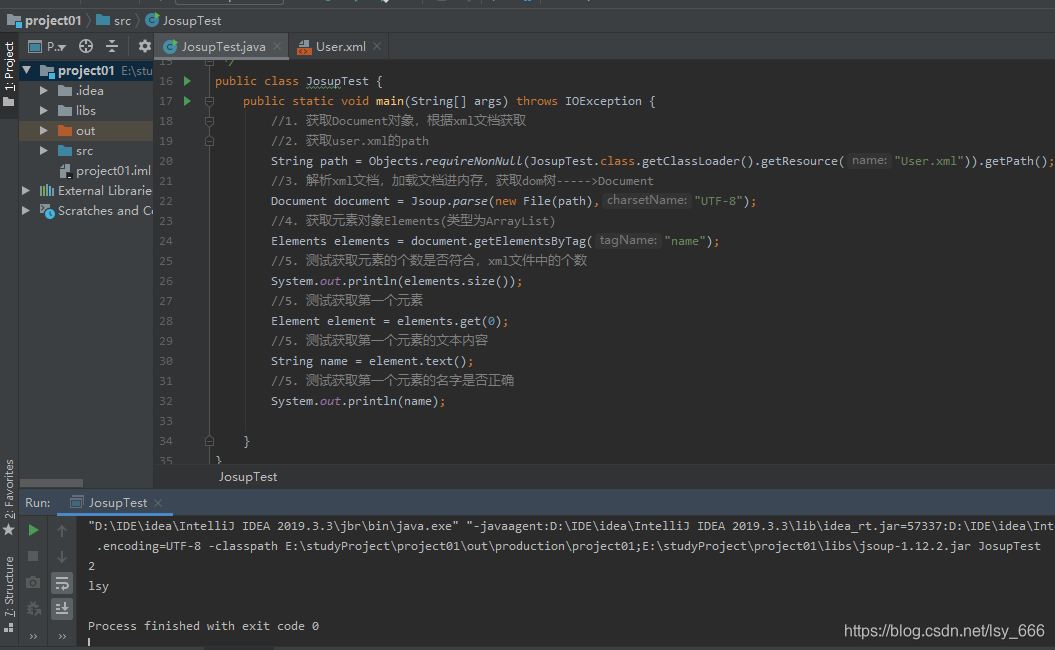
下面我们通过一个案例来进行实践一下,首先建一个名为 User.xml 的文件,在建一个JosupTest .java文件,下面是文件中的代码。
JosupTest .java文件
public class JosupTest {
public static void main(String[] args) throws IOException {
//1. 获取Document对象,根据xml文档获取
//2. 获取user.xml的path
String path = Objects.requireNonNull(JosupTest.class.getClassLoader().getResource("User.xml")).getPath();
//3. 解析xml文档,加载文档进内存,获取dom树----->Document
Document document = Jsoup.parse(new File(path),"UTF-8");
//4. 获取元素对象Elements(类型为ArrayList)
Elements elements = document.getElementsByTag("name");
//5. 测试获取元素的个数是否符合,xml文件中的个数
System.out.println(elements.size());
//5. 测试获取第一个元素
Element element = elements.get(0);
//5. 测试获取第一个元素的文本内容
String name = element.text();
//5. 测试获取第一个元素的名字是否正确
System.out.println(name);
}
}
User.xml文件
<?xml version="1.0" encoding="UTF-8" ?>
<users>
<user number="user01">
<name>lsy</name>
<age>20</age>
<sex>w</sex>
<phone>123654987</phone>
</user>
<user number="user02">
<name>tao</name>
<age>20</age>
<sex>m</sex>
<phone>125469873</phone>
</user>
</users>
我们运行上面的JosupTest .java文件,出现下面的打印,说明jsoup解析成功。
PS:在下一篇博客中,将详细讲解,Jsoup解析中使用到的对象的使用。