一、概述
1、介绍
WebMagic的底层用到了HttpClient和Jsoup 能够更方便地开发爬虫
WebMagic项目代码分为核心和扩展两部分
其中:
- ★核心部分(webmagic-core)是一个精简的 模块化的爬虫实现
而扩展部分则包括一些便利的 实用性的功能 - ★扩展部分(webmagic-extension)提供了一些便捷的功能 例如用注解模式编写爬虫等
同时内置了一些常用的组件 便于爬虫开发
WebMagic的设计目标是尽量的模块化 并体现爬虫的功能特点
提供了非常简单 灵活的API 可以在基本不改变开发模式的情况下编写一个爬虫
2、结构:
WebMagic的结构分为【Downloader】 【PageProcessor】 【Scheduler】 【Pipeline】四大组件
并由【Spider】将它们彼此组织起来
这四大组件对应了爬虫生命周期中的下载 处理 管理和持久化等功能
- Downloader
负责从互联网上下载页面以便后续处理
(默认使用HttpClient作为下载工具) - PageProcessor
负责解析页面 抽取有用的信息 以及发现新的链接
(使用Jsoup作为HTML解析工具 并基于其开发了解析XPath的工具Xsoup) - Scheduler
负责管理待抓取的URL 以及一些去重的工作
默认提供了JDK的内存队列来管理URL 并用集合进行去重
支持使用Redis进行分布式管理 - Pipeline
负责抽取结果的处理 包括计算 持久化到文件和数据库等
(默认提供了输出到控制台和保存到文件两种结果处理方案)
示意图:

是Spider将这几个组件组织起来 让它们可以互相交互 流程化的执行
可以认为Spider是一个大的容器 它也是WebMagic逻辑的核心
3、用于数据流转的对象:
★ Request
Request是对URL地址的一层封装
一个Request对应一个URL地址
是PageProcessor与Downloader交互的载体 也是PageProcessor控制Downloader的唯一方式
其有一个额外字段extra
可用于保存一些特殊的属性 然后在其它地方读取 以完成不同的功能 例如附加上页面信息
格式为key-value 键值对
★ Page
Page代表了从Downloader下载到的一个页面(可能是HTML也可能是Json或者其它文本格式的内容)
是WebMagic抽取过程的核心对象 提供了一些方法可供抽取 结果保存等操作
★ ResultItems
ResultItems相当于一个Map 保存了PageProcessor处理的结果 供Pipeline使用
其API与Map很类似
有一个额外字段skip 若设为true的话 则代表不被Pipeline处理
二、使用
1、简单使用
首先 是引入依赖:
<!--Webmagic核心包-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<!--Webmagic扩展包-->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
注:0.7.3版本对SSL的支持并不完全 若直接从Maven中央仓库下载依赖
在爬取只支持SSL v1.2的网站会有SSL的异常抛出
解决方案:使用0.7.4版本 或 直接从github上下载最新代码安装到本地仓库
然后将github下载的webmagic-core放于本地一个目录下
选择从本地导入:
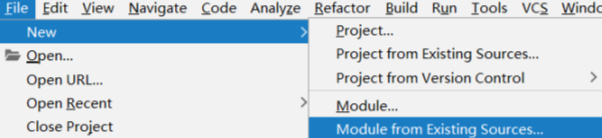
选择Maven:

点击该按钮:
安装:

然后是添加log4j.properties日志配置文件
(因为WebMagic的内部已整合了slf4j的依赖)
log4j.rootLogger=DEBUG,A1
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
接下来 就可以很方便地使用了:
// 实现PageProcessor类 复写方法
public class JobProcessor implements PageProcessor {
// 解析页面
public void process(Page page)
{
将结果以键值对的形式放入ResultItems中
page.putField("ul",page.getHtml().css("div.right-1 ul").all());
}
private Site site=Site.me();
public Site getSite()
{
return site;
}
// 主函数 执行爬虫
public static void main(String[] args)
{
// Spider容器创建解析器 添加url地址 run执行爬虫
Spider.create(new JobProcessor()).addUrl("http://www.zjitc.net/xwzx/tztg.htm").run();
}
}
2、抽取元素
(返回的都是Selectable 因此可用链式方式编写)
①、抽取
XPath抽取
XPath是一门在XML文档中查找信息的语言
用来在XML文档中对元素和属性进行遍历

例1:
page.putField("ul",page.getHtml().xpath("//div[@class='right-1']/ul").all());
例2:
获取属性class=mt的div标签里面的h1标签的内容
page.getHtml().xpath("//div[@class=mt]/h1/text()")

正则表达式抽取
正则表达式是一种通用的文本抽取语言
在爬虫中通常用于获取url地址

例:
page.putField("ul",page.getHtml().css("div.right-1 ul h3").regex(".*关于.*").all());
CSS选择器抽取
例:
page.putField("ul",page.getHtml().css("div.right-1 ul").all());
或
page.putField("ul",page.getHtml().$("div.right-1 ul").all());
css()等价于$()
②、获取元素
一条抽取规则 无论是XPath CSS选择器或是正则表达式 有可能抽取到多条元素
WebMagic可以通过不同的API获取到一个或多个元素
返回一条String类型的结果:
(默认返回第一条)
get()
例:String link=html.links().get()
toString()
例:String link=html.links().toString()
返回所有抽取结果:
all()
例:List links=html.links().all()
3、获取链接
获取列表的超链接地址并通过该地址访问里面的网页
public void process(Page page)
{
// 将class为right-1的div中的ul中的所有a标签作为目标链接
page.addTargetRequests(page.getHtml().css("div.right-1 ul a").links().all());
// 将目标链接中的class为zz的div的内容作为value放入键值对中
page.putField("zz",page.getHtml().css("div.zz"));
}
4、保存数据
可指定结果输出位置
WebMagic用于保存结果的组件是Pipeline
默认是通过控制台输出结果 也是通过Pipeline完成的 该Pipeline称作ConsolePipeline
若想将结果保存到文件中 只需将Pipeline的实现换成FilePipeline即可
可使用addPipeline()来手动设置数据输出位置
public static void main(String[] args)
{
Spider.create(new JobProcessor())
.addUrl("http://www.zjitc.net/xwzx/tztg.htm")
.addPipeline(new FilePipeline("C:/Users/ABC/Desktop/Crawler"))//设置文件输出位置
.run();
}
保存的是Html格式 用ConsolePipeline时控制台打印的是什么 那么用FilePipeline输出到本地时里面的数据就是什么
多线程
使用.thread()来设置线程数
public static void main(String[] args)
{
Spider.create(new JobProcessor())
.addUrl("http://www.zjitc.net/xwzx/tztg.htm")
.addPipeline(new FilePipeline("C:/Users/A/Desktop/Crawler"))
.thread(5) 多线程
.run();
}
5、爬虫(Spider)的配置 启动和终止
Spider是爬虫启动的入口
在启动爬虫之前 需要使用一个PageProcessor来创建一个Spider对象 然后使用run()进行启动
还可设置Spider的其它组件(Downloader Scheduler Pipeline)


Site爬虫配置
Site.me()可对爬虫进行一些配置 包括编码字符 抓取间隔 超时时间 重试次数等
private Site site=Site.me()
.setCharset("utf8") //设置编码
.setTimeOut(10000) //设置超时时间(单位:毫秒)
.setRetryTimes(3000) //设置重试的时间间隔(单位:毫秒)
.setSleepTime(3); //设置重试次数
public Site getSite() {
return site;
}
其它设置:
setUserAgent(String):设置代理
addCookie(String):添加Cookie
setDomain(String):设置域名
addHeader(String,String):添加请求头
setHttpProxy(HttpHost):设置Http代理
三、定时任务
使用Spring内置的Spring Task来实现
这是Spring3.0加入的定时任务功能
使用@Scheduled注解的方式定时启动爬虫进行数据爬取
属性:
cron:cron表达式 指定任务在特定时间执行
fixedDelay:上一次任务执行完后多久再执行 参数类型为long 单位毫秒
fixedDelayString:上一次任务执行完后多久再执行 参数类型为String 单位毫秒
fixedRate:按一定的频率执行任务 参数类型为long 单位毫秒
fixedRateString:按一定的频率执行任务 参数类型为String 单位毫秒
initialDelay:延迟多久后第一次执行任务 参数类型为long 单位毫秒
initialDelayString:延迟多久后第一次执行任务 参数类型为String 单位毫秒
zone:时区 默认为当前时区
cron表达式
某些业务要求较高 并不是定时定期处理 而是在特定的时间进行处理
此时需要使用cron表达式
cron表达式实际上是由七个子表达式描述个别细节的时间表
这些子表达式用空格进行分隔 每位分别代表:
- 1、Seconds 0-59
- 2、Minutes 0-59
- 3、Hours 0-23
- 4、Day-of-Month 1-31
- 5、Month 0-11或字符串JAN FEB…
- 6、Day-of-Week 1-7或字符串SUN MON…
- 7、Year(可省略)
其中:
/代表"每" 例如0/15代表每隔15分钟 从第0分钟开始执行
?代表每月的某一天或每周某一天
*代表整个时间段
L代表每月或每周的最后一天或每个月的最后一个星期几
例:6L代表每月的最后一个星期五
因此 0 0 12 ? * WED 就是代表在每星期三下午12:00执行
@Component
public class TaskTest {
@Scheduled(cron = "0/8 * * * * *")
public void test()
{
System.out.println("定时任务start");
}
}
8秒执行一次
四、代理
部分网站不允许爬虫进行数据爬取 因为会加大服务器的压力
其中一种最有效的方式是通过ip+时间进行鉴别 因为常人不可能短时间开启太多页面发起太多请求
WebMagic可设置爬取数据的时间 但会大大降低爬取数据的效率
若ip被禁了则无法爬取数据 此时 有必要使用代理服务器爬取数据
代理(Proxy) 也称网络代理 是一种特殊的网络服务
允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接
提供代理服务的电脑系统或其他类型的网络终端称为代理服务器(Proxy Server)
一个完整的代理请求过程为:客户端首先与代理服务器创建连接
接着根据代理服务器所使用的代理协议 请求对目标服务器创建连接 或获得目标服务器的指定资源

需要知道代理服务器的ip和端口号才可使用
网上有很多代理服务器的提供商 但大多是免费的 不好用 付费的会较好用
免费代理服务器:
米扑代理 https://proxy.mimvp.com/free.php
西刺代理 http://www.xicidaili.com
APIProxyProvider
WebMagic使用的是APIProxyProvider
相对于Site的配置 ProxyProvider的定位更多是一个组件
代理不再从Site设置 而是由HttpClientDownloader设置
ProxyProvider有一个默认实现类:SimpleProxyProvider
是一个基于简单Round-Robin的 没有失败检查的ProxyProvider
可配置任意数量候选代理 每次会按顺序挑选一个代理使用
若要自己根据实际使用对代理服务器进行管理 还可自己实现APIProxyProvider
使用
作为一个爬虫类 首先该类必须实现PageProcessor接口
@Component
public class ProxyTest implements PageProcessor {
...
}
创建爬虫:
@Scheduled(fixedDelay = 1000)
public void Process()
{
// 创建下载器Downloader
HttpClientDownloader httpClientDownloader=new HttpClientDownloader();
// 给下载器设置代理服务器信息
httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("183.91.33.41",89)));
Spider.create(new ProxyTest())
.addUrl("http://ip.chinaz.com/")
// 设置下载器
.setDownloader(httpClientDownloader)
.run();
}
解析页面:
@Override
public void process(Page page) {
System.out.println(page.getHtml().css("dl.IpMRig-tit dd.fz24","text").toString());
}
返回Site:
private Site site=Site.me();
@Override
public Site getSite() {
return site;
}
