文章目录
1 简介
SegNet是Cambridge提出旨在解决自动驾驶或者智能机器人的图像语义分割深度网络,开放源码,基于caffe框架。SegNet基于FCN,修改VGG-16网络得到的语义分割网络,有两种版本的SegNet,分别为SegNet与Bayesian SegNet,同时SegNet作者根据网络的深度提供了一个basic版(浅网络)。
2 网络框架

SegNet和FCN思路十分相似,只是Encoder,Decoder(Upsampling)使用的技术不一致。此外SegNet的编码器部分使用的是VGG16的前13层卷积网络,每个编码器层都对应一个解码器层,最终解码器的输出被送入soft-max分类器以独立的为每个像素产生类概率。
左边是卷积提取特征,通过pooling增大感受野,同时图片变小,该过程称为Encoder,右边是反卷积(在这里反卷积与卷积没有区别)与upsampling,通过反卷积使得图像分类后特征得以重现,upsampling还原到图像原始尺寸,该过程称为Decoder,最后通过Softmax,输出不同分类的最大值,得到最终分割图。
3 Encoder
Encoder过程中,通过卷积提取特征,SegNet使用的卷积为same卷积,即卷积后保持图像原始尺寸;在Decoder过程中,同样使用same卷积,不过卷积的作用是为upsampling变大的图像丰富信息,使得在Pooling过程丢失的信息可以通过学习在Decoder得到。SegNet中的卷积与传统CNN的卷积并没有区别。

4 Pooling&Upsampling(decoder):
pooling在CNN中是使得图片缩小一半的手段,通常有max与mean两种Pooling方式,下图所示的是max Pooling。max Pooling是使用一个2x2的filter,取出这4个权重最大的一个,原图大小为4x4,Pooling之后大小为2x2,原图左上角粉色的四个数,最后只剩最大的6,这就是max的意思。
在SegNet中的Pooling与其他Pooling多了一个index功能(该文章亮点之一),也就是每次Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置,对于上图的6来说,6在粉色2x2 filter中的位置为(1,1)(index从0开始),黄色的3的index为(0,0)。同时,从网络框架图可以看到绿色的pooling与红色的upsampling通过pool indices相连,实际上是pooling后的indices输出到对应的upsampling(因为网络是对称的,所以第1次的pooling对应最后1次的upsamping,如此类推)。
Upsamping就是Pooling的逆过程(index在Upsampling过程中发挥作用),Upsamping使得图片变大2倍。我们清楚的知道Pooling之后,每个filter会丢失了3个权重,这些权重是无法复原的,但是在Upsamping层中可以得到在Pooling中相对Pooling filter的位置。所以Upsampling中先对输入的特征图放大两倍,然后把输入特征图的数据根据Pooling indices放入,下图所示,Unpooling对应上述的Upsampling,switch variables对应Pooling indices。
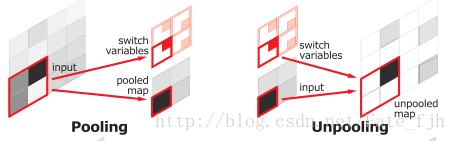
比FCN可以发现SegNet在Unpooling时用index信息,直接将数据放回对应位置,后面再接Conv训练学习。这个上采样不需要训练学习(只是占用了一些存储空间)。反观FCN则是用transposed convolution策略,即将feature 反卷积后得到upsampling,这一过程需要学习,同时将encoder阶段对应的feature做通道降维,使得通道维度和upsampling相同,这样就能做像素相加得到最终的decoder输出.

5 Batch Normlization
在SegNet的每个卷积层后加上一个Batch Normlization层,Batch Normlization层后面为ReLU激活层。 文中指出,加入Batch Normlization层明显改善了语义分割效果。
6 Loss Function
使用Softmax 损失函数。
7 Segnet网络代码
基于Tensorflow :
#####################
# Downsampling path #
#####################
net = conv_block(inputs, 64)
net = conv_block(net, 64)
net = slim.pool(net, [2, 2], stride=[2, 2], pooling_type='MAX')
skip_1 = net
net = conv_block(net, 128)
net = conv_block(net, 128)
net = slim.pool(net, [2, 2], stride=[2, 2], pooling_type='MAX')
skip_2 = net
net = conv_block(net, 256)
net = conv_block(net, 256)
net = conv_block(net, 256)
net = slim.pool(net, [2, 2], stride=[2, 2], pooling_type='MAX')
skip_3 = net
net = conv_block(net, 512)
net = conv_block(net, 512)
net = conv_block(net, 512)
net = slim.pool(net, [2, 2], stride=[2, 2], pooling_type='MAX')
skip_4 = net
net = conv_block(net, 512)
net = conv_block(net, 512)
net = conv_block(net, 512)
net = slim.pool(net, [2, 2], stride=[2, 2], pooling_type='MAX')
#####################
# Upsampling path #
#####################
net = conv_transpose_block(net, 512)
net = conv_block(net, 512)
net = conv_block(net, 512)
net = conv_block(net, 512)
if has_skip:
net = tf.add(net, skip_4)
net = conv_transpose_block(net, 512)
net = conv_block(net, 512)
net = conv_block(net, 512)
net = conv_block(net, 256)
if has_skip:
net = tf.add(net, skip_3)
net = conv_transpose_block(net, 256)
net = conv_block(net, 256)
net = conv_block(net, 256)
net = conv_block(net, 128)
if has_skip:
net = tf.add(net, skip_2)
net = conv_transpose_block(net, 128)
net = conv_block(net, 128)
net = conv_block(net, 64)
if has_skip:
net = tf.add(net, skip_1)
net = conv_transpose_block(net, 64)
net = conv_block(net, 64)
net = conv_block(net, 64)
8 分割效果

数据集:SegNet (3.5K dataset training - 140K)
精确度结果:

