1 Inception-V3模型简介
本例使用预训练好的深度神经网络Inception-v3模型来进行图像分类。Inception-v3模型在一台配有 8 Tesla K40 GPUs,大概价值$30,000的野兽级计算机上训练了几个星期,因此不可能在一台普通的PC上训练。我们将会下载预训练好的Inception模型,然后用它来做图像分类。
Inception-v3模型大约有2500万个参数,分类一张图像就用了50亿的乘加指令。在一台没有GPU的现代PC上,分类一张图像转眼就能完成。
2 ImageNet数据集简介
ImageNet数据集包含1500万张图片,22000个类别。其子集对应的是目前最权威的图片分类竞赛LSVRC,包含100万张图片和1000个类别。
谷歌在大型图像数据库ImageNet上训练好了一个Inception-v3模型,这个模型可以直接用来进行图像分类。
输入:一张图片;
输出:与输入图相匹配的库内图片名及匹配分数。
3 工程文件


文件:就是训练好的Inception-v3模型;

文件:为类别文件,共包含2万多种类别,内容如下:


为进行分类的代码;

为分类的输入图;
为镜像文件;
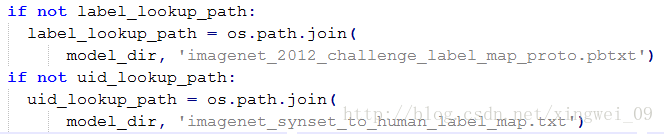
4 运行


5 结果

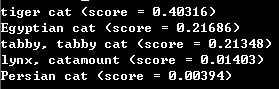
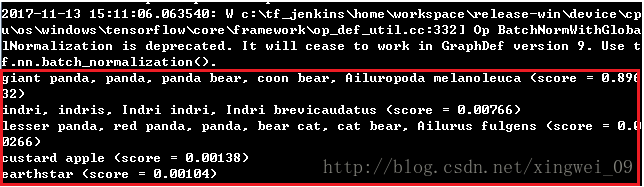
运行,获得库内分数最高的前5个(即获得输入图的类别),结果如下:
修改目标图为熊猫
- 如果将目标图改为熊猫,例图为:

打开Classify.py文件,代码做如下修改:
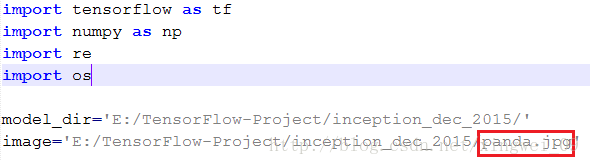
运行结果如下:
2. 在 文件内,查找panda,即可找到所有panda:

