最近又收到个任务,要去抓取别人小程序的内容,通过fiddler抓包,请求和响应数据看的我是一脸懵逼,自己造数据是不可能的,小程序看不到js,根本猜不到怎么解密和加密的。网上也有文章说小程序的源码可以通过反编译下载下来,我反正是没成功。那怎么办呢? 想到我们之前用的网页端的自动化测试工具selenium,就不难解决了。数据我解不出来就模拟呗。
移动端自动化测试工具选取 Appium 和 网易的airtest
相比之下我还是选了airtest,因为我们现在测试用的就是airtest,不懂的还能问,嘿嘿。
http://airtest.netease.com/ 下载地址
具体的配置去看他的官方文档,写的很详细,如果还连不上去提issue。我之前折腾了半天,才弄好了,如果出现下面的界面表示连好了
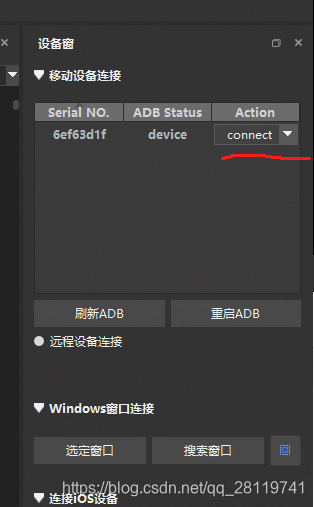
然后我们点connect就会出现手机的同步窗口了
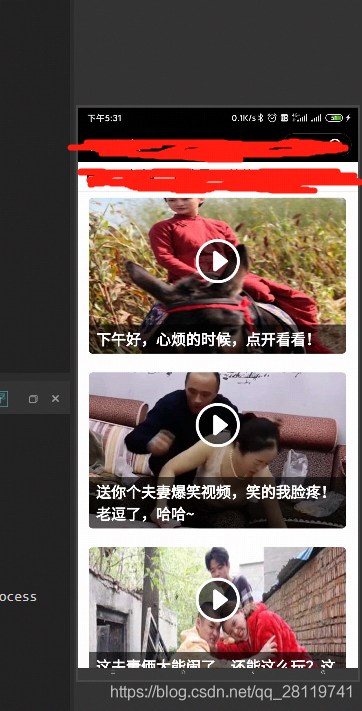
我在这里点开了某个小程序,所以显示这样,需要下载这些视频
分析小程序的细节就不说了,反正数据都是加密的,点开播放页才会出现视频的url。这里前面的动作我就不模拟了,每次都是直接打开这个小程序。有兴趣的自己研究下。所以自动化的动作我们也就清楚了,点进去播放页,点击返回,拉列表。。。循环起来。
airtest用2种方式,一种是图像识别,另一种是poco。
这里我用的是poco,本来想定位ui,然后发现这个ui不准,也不知道怎么回事。然后就使用坐标了。
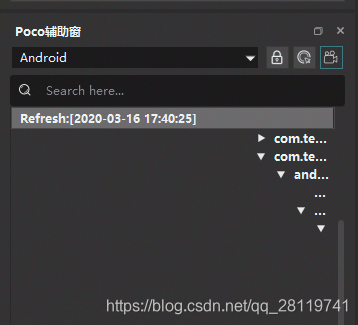
那里调成Android,我是安卓手机,其它自己选,然后点这个摄像机
放到这个图标上面
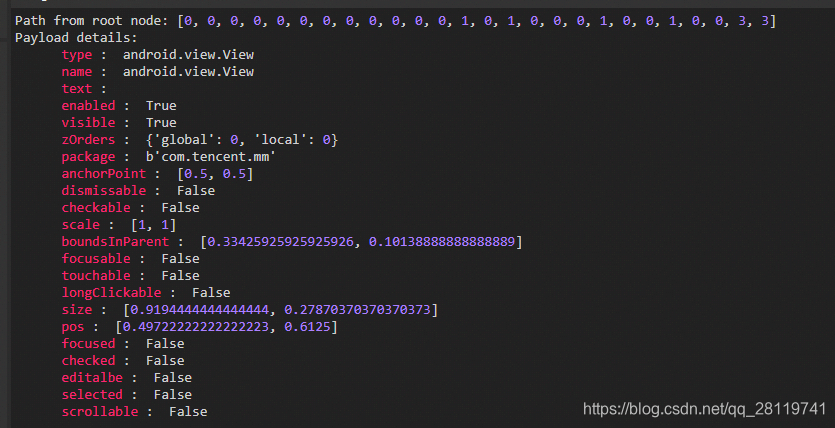
然后再控制台就会显示这些信息。这些都什么意思,可以查官方文档。不过通过观察我们可以发现 pos这个应该是全局的位置信息。
点这个我们就可以进播放页了,那么怎么执行点击动作呢?
poco.click([0.49722222222222223, 0.24537037037037038])
上面的就是点击对应的位置信息
依次类推,找到返回位置,点击返回。也可以使用安卓的返回按键事件。
![]()
然后如果点击下一个视频的播放页呢
这里,我想的是把下一个移到当前位置就可以了,这样播放按钮的也不需要动了。想到了就干,我们用上面的方法拿到下一个播放的pos
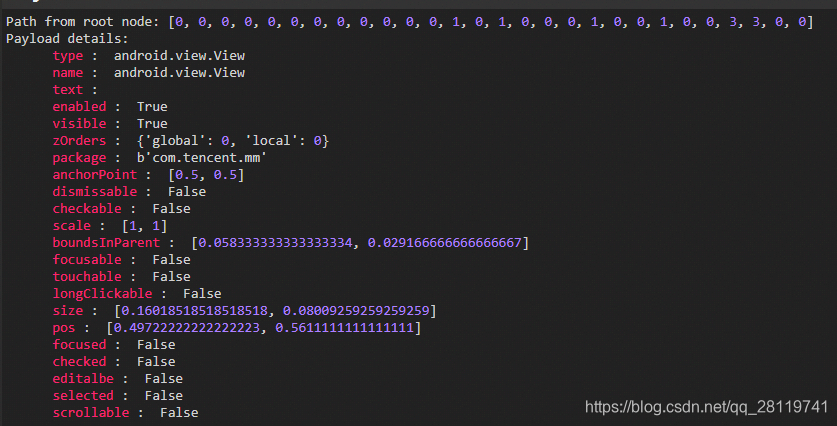
这时候我们只需要把下一个移到上一个的位置就好了。
怎么移?
poco.swipe([0.49722222222222223, 0.5574074074074075], [0.49722222222222223, 0.24537037037037038] )
完整的代码
i = 0
while True:
if i>=50:
break
poco.click([0.49722222222222223, 0.24537037037037038])
time.sleep(110)
poco.click([0.05, 0.06])
time.sleep(5)
poco.swipe([0.49722222222222223, 0.5574074074074075], [0.49722222222222223, 0.24537037037037038] )
i+=1
不过在跑的过程中,坐标总是差点,后续再优化。这个效果就是点击播放页,睡一会等加载,然后点击返回,再把下一个视频移到第一个的位置上,然后再点击,循环。
自动化我们做完了,那怎么拿到数据呢?
这里还要用到一个工具mitmproxy,这个工具是监听所有请求和响应,还可以使用python api获取到这些请求和响应。
https://www.mitmproxy.org/直接官网下载,这里我是windows电脑,直接下载exe安装了。
安装完成后

运行mitmdump,
就会在
生成一个文件夹,里面是证书,如果要监听https的请求,必须安装这个

里面是这些,然后双击第四个安装就可以了,一路选是,受信任的根证书。 具体的自己查,网上很多。
然后手机点开WLAN设置手动代理,ip填运行mitmproxy的电脑ip,端口默认8080。
再在手机上安装证书,手机浏览器输入mitm.it,这里推荐使用chrome,我用的uc根本找不到证书,然后又换成了系统默认的,能点击下载,但是根本下不下来,换成谷歌一下就好了。 注意需要开着mitmdump,或者mitmweb,一个是控制台一个是网页端。
下载下来安装就可以了。
然后环境这时候我们都配好了,想要打开小程序,这时候发现一片白,根本什么都不显示,而其他app都是可以的。这个问题我也查了很久,最终发现降低微信版本就可以。高版本不知道做了什么措施 具体可以看这个
https://xingzx.org/blog/crawl-wechatapp-on-android
然后怎么拿到监听的数据呢?
先下载mitmproxy的包
pip3 install mitmproxy
注意python需要用py3.6及以上。
然后测一下代码
from mitmproxy import ctx
# # 所有发出的请求数据包都会被这个方法所处理 # # 所谓的处理,我们这里只是打印一下一些项;当然可以修改这些项的值直接给这些项赋值即可 # def request(flow): # # 获取请求对象 # request = flow.request # # 实例化输出类 # info = ctx.log.info # # 打印请求的url # info(request.url) # # 打印请求方法 # info(request.method) # # 打印host头 # info(request.host) # # 打印请求端口 # info(str(request.port)) # # 打印所有请求头部 # info(str(request.headers)) # # 打印cookie头 # info(str(request.cookies)) # # # # 所有服务器响应的数据包都会被这个方法处理 # # 所谓的处理,我们这里只是打印一下一些项 # def response(flow): # # 获取响应对象 # response = flow.response # # 实例化输出类 # info = ctx.log.info # # 打印响应码 # info(str(response.status_code)) # # 打印所有头部 # info(str(response.headers)) # # 打印cookie头部 # info(str(response.cookies)) # # 打印响应报文内容 # info(str(response.text))
在控制台输入mitmdump -s xxx.py。 我运行的时候报了缺了好多个包,然后一个个用pip3下载下来了。
最后遇到一个比较棘手的还得需要vs工具,这里给你们个连接,可以自己下
https://blog.csdn.net/antizheng/article/details/88633912
然后运行就可以了,注意把之前开的mitmdump关掉。
这时候在控制台就能看到这些请求和响应了
然后写我们的下载代码,直接贴出来了
url_map = dict()
def request(flow):
if flow.request.url.startswith("http://xxx"):
r = requests.get(flow.request.url)
if flow.request.url in url_map:
return
url_map[flow.request.url] = 1
rand = random.randint(0, len(titles) - 1)
t = time.time()
title = str(titles[rand] + "{0}.mp4").format(int(t))
with open(title, "wb") as mp4:
for chunk in r.iter_content(chunk_size=1024 * 512):
if chunk:
mp4.write(chunk)
然后大功告成了就,好累。。。


