一、须知
1.手语与手势的区别
手势:
手的姿势 ,通常称作手势。它指的是人在运用手臂时,所出现的具体动作与体位。

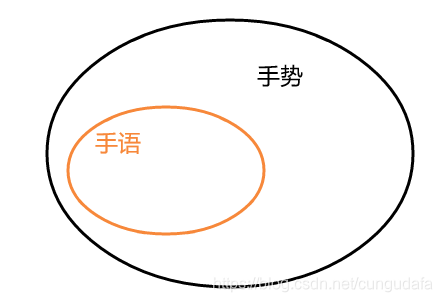
手语:
手语是用手势比量动作,根据手势的变化模拟形象或者音节以构成的一定意思或词语,它是听力障碍或者无法言语的人互相交际和交流思想的一种手的语言,它是“有声语言的重要辅助工具”,而对于听力障碍的人来说,它则是主要的交际工具。
2018年7月1日,中国实施《国家通用手语常用词表》和《国家通用盲文方案》作为语言文字规范发布。
很多人把手语和手势的区别弄混淆了,记住一点:手势包含手语。
2.手语图像分类
手语分为单手和双手手语:
图一:单手(study学习)图二:双手(middle中)

图片和视频均采自:手语词典
手语分为静态和动态手语:
图一:静态(house家的手语表达)图二:动态(movehouse搬家)


目前基于静态手势图像的识别有很多参考学习内容:
-
根据opencv轮廓处理可以简单的识别1-5手势(案例很多,这里就不放链接了)
其中多是提取 轮廓、直方图 等方法。
其中动态手势图像识别,有个关键模块为:“孤立词” 识别:
-
孤立词手语是指时间和空间的序列,与连续手语不同的是,它不包含连续手语的过渡帧(连接相邻不同手语词间没有实际含义的手势动作)。
它与动态手势的定义类似,孤立词手语包括 准备动作(Prestoke)、有效动作(Stocke)和结束动作(Poststoke) 三个部分。
手语孤立词“搬家”,双手抬起为准备动作阶段,双手呈人字状并从左向右移动为有效移动阶段,手落下的过程为结束动作阶段。
-
连续手语识别
需要利用深度学习和机器学习分类算法处理。
二、开源数据集
1.国外数据集
-
著名的连续手语数据集是RWTH- PHOENIX-Weather
包含由 9 个人提供的45 760 个视频样本,其中包含 5 356 个与天气预报相关的句子、1200个德国手语词汇,大约占 52 GB的存储空间。 -
SIGNUM数据集
它包含由 25 个人提供的 33 210 个视频样本,其中包含 780 个句子、450 个德国手语词汇,每个句子包含 2 个至 11 个手语词汇不等。数据集大约占920 GB的存储空间。 -
波士顿大学的 ASLLVD
它包含由6 名手语者根据超过 3 300 个美国手语词汇提供的 9 800 个视频样本。 -
ASL-LEX美国手语数据集
它包含由将近 1 000 个手语的各种特征。多数美国手语数据集可在kaggle网站下载
2.国内数据集
-
中国手语 DEVISIGN 数据集
它是在微软亚洲研究院的赞助下建立的,旨在为世界范围内的研究者提供一个大型的词汇级的中国手语数据集,用于训练和评估他们的识别算法。目前,该数据集包含 4 414 个中国手语词汇,共包含 331 050 个 RGB-D 视频及对应的骨骼信息,由13名男性和17名女性提供。国内手语数据集太少了,另外还有手语字母表数据集、手势形状数据集、基于数据手套的手语数据集及使用其他特定可穿戴设备制作的数据集。
三、自采集数据集
当然对于图像研究,开源数据集图像是无价的,珍惜并感谢每一位付出者,在使用时,必须遵守对方制定的开源规则。
在我们日常研究中,除了寻找开源数据集以外,自采集图像作为训练样本也是非常重要的。
1.要求
- 图像采集设备要求:
单目摄像机、双目摄像机、红外摄像机、深度摄像机(kinetic等) - 图像的丰富性:
同一种手势,不同背景、不同光照、不同角度、不同人多方面全面考虑;
不同手势尽可能全的手语特征手型类种。
2.有效样本
采集样本不是越多越好,样本的复杂性会在我们进行图像分类识别时造成过拟合的情况;因此在图像预分类阶段,筛选样本是关键一步,不然前期做的大量功夫都徒劳了。
挑选特征样本阶段:
- 被挑选的样本可以表征特定手语词的特征手形;(基本要求)
- 被挑选的样本彼此之间尽可能的不同;(样本不重复性)
- 被挑选的样本需要包含不同角度看过去的情况;(减少设备外界影响因素)
- 被挑选的样本的集合可以表征特定手形的一个运动状态;(保证设计模型有效运行)
- 对于一个单手的特征手形,被挑选的样本需要包含左右手的不同情况
- 手臂自然垂下的手形也是特征手形的一种。(起始状态)
参考:在之前的文章中,我们根据距离和角度对手形进行特征提取,目前针对提取的手型数据库挑选时,
同一种手势:保证剩余的手形样本则使用如下的余弦距离阈值计算式在手形库中自动挑选:(保证样本不重复性!)
式中ai,b分别表示示例样本和待选手形的特征值,distancei表示示例样本与待选手形的预选距离,用以表示两者的相似度。(阈值0.88设置参考于《基于神经网络的中小词汇量中国手语识别研究_李晓旭》)

