java字符串底层在jvm中的具体执行与优化过程
在这之前必须附上两张图进行参考
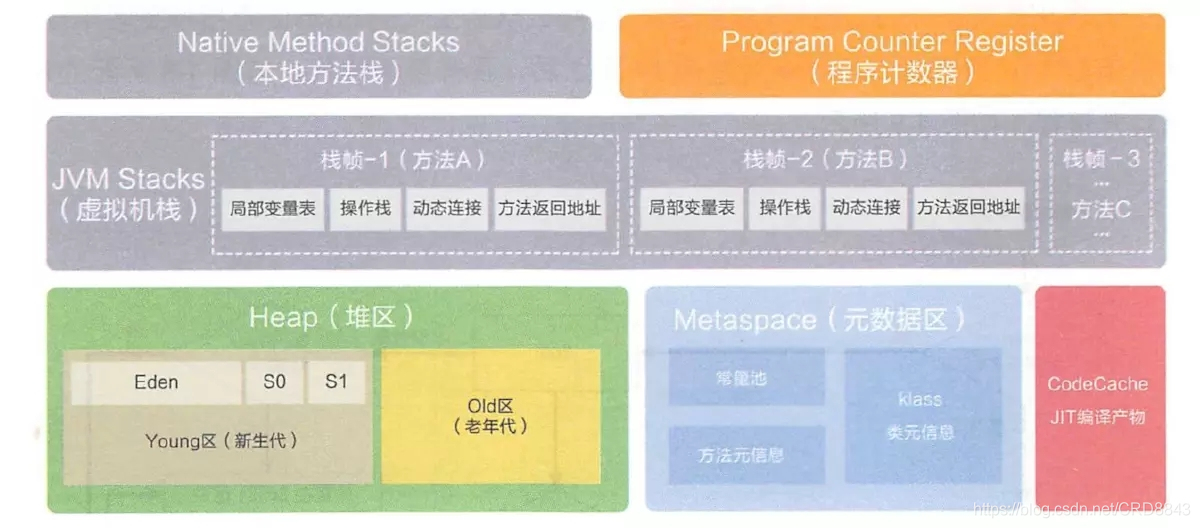
说明:栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢
字符串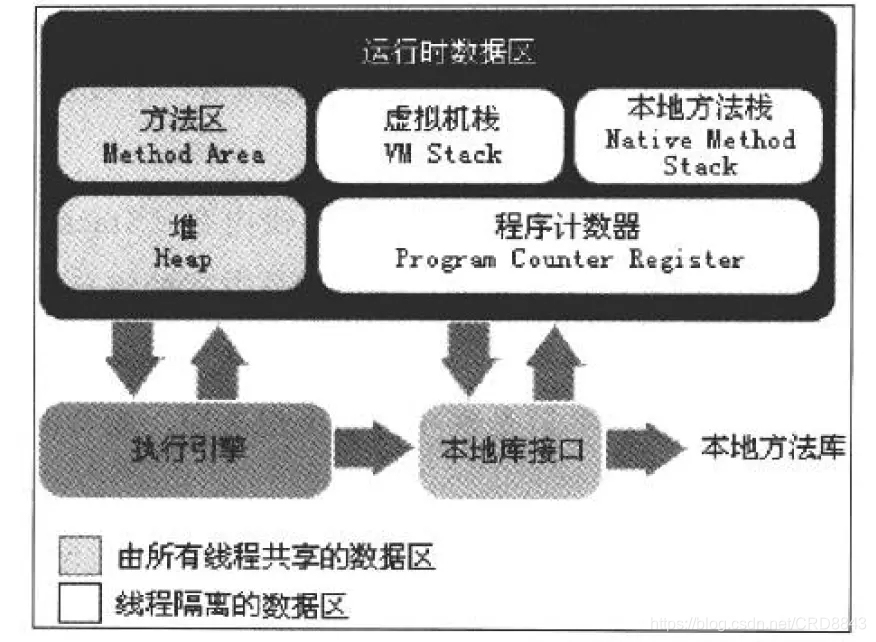
- Unicode编码的字符序列
- java没有内置的字符串类型,而是在java类库中预定义了一个类
- 每个双引号引起来的就是一个实列
- 可以通过直接赋值或者new创建字符串
- 从JDK1.7开始,我们可以使用string作为switch的条件
- String没有用于修改字符串的方法,被称作不可变字符串(不可变字符序列),定义声明为final class ,但是我们可以修改字符串变量,让它指向改变
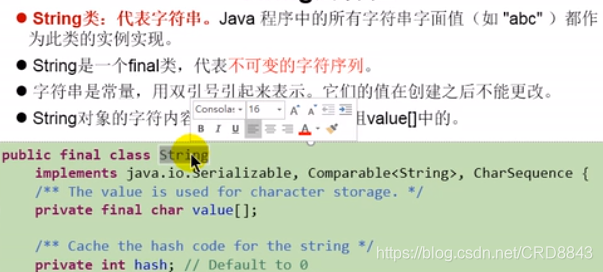
serializable接口:表示字符串支持序列化的
comparable接口:表示String可以比较大小
内部定义的value数组用于存储字符串数据
列如:
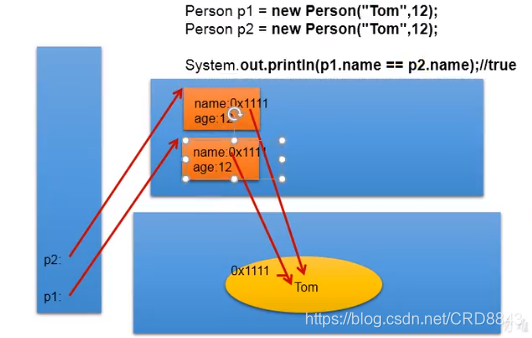
String s1 = "abc";
String s2 = "abc";
//下面这条语句过后s1和s2指向不同的内存区域
s1 = "hello";
s1 == hello;
s2 == abc
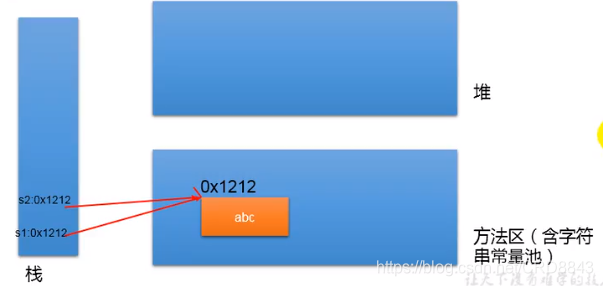
1.8之后常量池在方法区,具体在方法区的元空间
- 为提高内存利用率jvm提供了字符串常量池,java会先查找里面是否存在,存在则直接对象的引用,不存在则创建并返回他的引用
- 使用new和一般的直接赋值不同,String类提供了intern()方法,调用该方法时候会首先去常量池查看是否有该字符串存在则直接返回引用不存在,则在常量池中添加并返回引用
String s5 = "hel"; String s4 = s5.intern(); System.out.println(s4);//hel - java8中将字符串常量池放在堆中,而且默认缓存大小也在不断扩大,java8中的PermGen被MateSpace替代
String 对象的创建
String s8 = "hellohelloworldworld";
String s9 = new String("hellohelloworldworld");
System.out.println(s8 == s9);//false
System.out.println(s8.equals(s9));//true
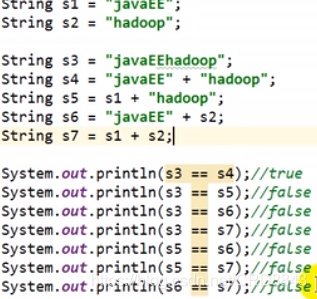
String s1 = "LittleMagic";
String s2 = "LittleMagic";//在常量池中
String s3 = new String("LittleMagic");//没在常量池中
String s4 = s3.intern();//返回值也是常量池
String s5 = "Little" + "Magic";
String s6 = "LittleMagic2";
String s7 = s2 + 2;
System.out.println(s1 == s2); // true
System.out.println(s2 == s3); // false
System.out.println(s2 == s4); // true
System.out.println(s2 == s5); // true
System.out.println(s6 == s7); // false
System.out.println(s5 == s6);//true
实验分析:
s1 == s2 明显地址相等,前面有叙述
s3是new出来的字符串对象,它会在堆内存中分配一个新的地址。它的地址与字符串常量池中s2的引用地址自然是不同的
s3这条语句一共创建了几个对象?
答案是2个,即堆上的对象,以及JVM栈中对它的reference。但是,如果前面没有创建过相同的字面量的话,那么还得加上字面量本身,也就是3个。
意思就是,如果字符串常量池中已经存在一个字面量上相等(用String.equals()方法判定)的字符串,就返回常量池中的字符串。否则,就将这个字符串加入常量池,并返回它的引用。这样理解,s2与s4相等就是自然的了
s6 != s7
仍然从字节码中可以看出,s7 = s2 + 2这条语句,实际上是new出了一个StringBuilder(和StringBuffer一样都是基层abstracted StringBuilder抽象类,java9之前底层是char数组,之后是byte数组),然后调用其append()方法来做连接。StringBuffer内部使用的所有方法synchronized修饰的,执行速度较慢,相对于适合用于线程并发的状况,如果“+”运算中存在字符串引用的话,就会创建新的对象了,因为引用对应的值在编译期是无法确定的。循环中字符串拼接 直接使用StringBuilder的方式是效率最高的。因为StringBuilder天生就是设计来定义可变字符串和字符串的变化操作的。
1、如果不是在循环体中进行字符串拼接的话,直接使用+就好了。
2、如果在并发场景中进行字符串拼接的话,要使用StringBuffer来代替StringBuilder。
在StringBuffer和StringBuilder中,默认容量是16,扩容是两倍+2
| 类名 | 增长率 | 初始值 |
|---|---|---|
| ArrayList | 1.5x + 1 | 10 |
| Vector | 2x | 10 |
| HashMap | 2x | 16 |
| HashTable | 2x+1 | 11 |
| StringBuffer | 2x+ 2 | 16 |
| StringBuilder | 2x+2 | 16 |

大于0该扩容了

扩容方式:
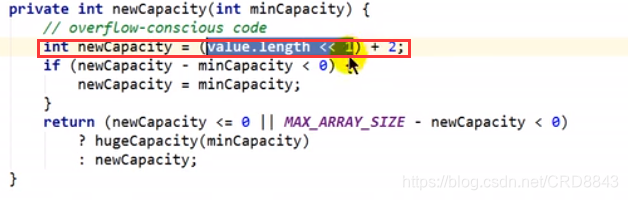
也可以自己评估扩容:
扩展:HashTable和HashMap区别
第一,继承不同。
public class Hashtable extends Dictionary implements Map
public class HashMap extends AbstractMap implements Map
第二:
Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用
Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
第三,Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,
即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中
是否存在某个键, 而应该用containsKey()方法来判断。

第四,两个遍历方式的内部实现上不同。
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
第五,哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
第六,
Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方
式是 old2+1。HashMap中hash数组的默认大小是16, 增加的方式是 old2。
由此也可以得知,不要在循环中使用类似s7 = s2 + 2(也就是String+)这种调用方法,因为每次循环都要创建StringBuilder对象,拖累运行效率。
String s = "java";
//这里替换是双引号
String ss = s.replace("j","j");
//第一个是元数据区的引用,第二个是堆中的引用
//(replace方法:return new String(buf, true);),自然不相等
System.out.println(s == ss);//false
//但是如果是单引号
String sss = s.replace('j','j');
//String 中的replace方法两个char相同会return this
System.out.println(sss == s);//true
/*
列:剑指offer中的左移字符串
*/
public class Solution {
public String LeftRotateString(String str,int n) {
if(str.length()==0||n<0 || str == null){
return "";
}
StringBuffer sb=new StringBuffer(str.substring(0,n));
StringBuffer sb1=new StringBuffer(str.substring(n,str.length()));
sb1.append(sb);
return sb1.toString();
}
}
说明:String的new String
public String(String original) {
//确实会产生新的对象,而且新的value和hash值都和原String对象一致
this.value = original.value;
this.hash = original.hash;
}
字符串的空串和null
- String s = “”;//空串
- String ss = null;//null值
- 空串是已经实列化对象,占有内存空间,只是里面的的存储值为空,当使用length()方法显示为0
- null表示没有实例化对象,不占有内存空间,当使用length()方法会空指针异常报错
- 如果调用isEmpty()方法,s会发生false,ss会空指针异常,以上两种情况说明说明ss没有指向任何内存空间
字符串中有些存在自动的优化
String name5="jack";
String name6="j"+"a"+"c"+"k";
System.out.println(name5==name6); //true
System.out.println(name5.equals(name6)); //true
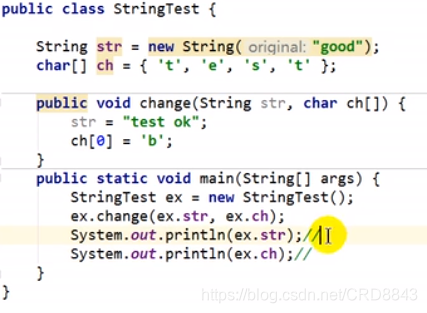
答案:
good
best
String 常用方法
String s1 = "Hello";
s1.length();
s1.charAt(int index);
s1.isEmpty();//return value.length == 0
String s2 = s1.toLowerCase();//hello,常量池中多了一个
String s3 = " he ";
String s4 = s3.trim();//he
s1.equalsIgnoreCase(s2);
s3.concat("def");
s1.compareTo(s2);//返回字符串相减的值s2 - s1
s1.substring(0,1);//H
boolean b = s1.endWith("o");
boolean b1 = s1.startWith("H");
s1.contains(s2);
s1.indexOf("llo"); //没找到返回-1
.。。。。。
String和其他包装类,基本数据类型的转换
(1)String ->int
String s1 = “abc”;
int n = Integer,parseInt(s1);
(2)int ->String
String s2 = String.valueOf(n);
(3)字符数组->String
char ch[] = s1.toCharArray();
(4)String ->字符数组
String s2 = new String(ch);
(5)String ->字节数组
byte[] bytes = s1.getByte();
(6)字节数组 - >String
String s3 = new String(bytes);
