import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;import java.io.File;import java.util.List;publicclassTest{publicstaticvoidmain(String[] args)throws DocumentException {//1.创建核心对象
SAXReader reader =newSAXReader();//2.读取xml文件
Document document = reader.read(newFile("Practice1/books.xml"));//相对路径是相对于工程而言的,所以要指定模块//3.获取根标签
Element rootElement = document.getRootElement();
System.out.println("根标签是:"+rootElement.getName());//4.获取book标签
List<Element> bookElements = rootElement.elements();//5.遍历集合for(Element bookElement : bookElements){//6.获取标签名
String bookElementName = bookElement.getName();
System.out.println("子标签:"+bookElementName);//7.获取id属性值
String idValue = bookElement.attributeValue("id");
System.out.println("属性id:"+idValue);//8.继续获取子标签
List<Element> elements = bookElement.elements();//9.遍历for(Element element : elements){//10.获取标签名
System.out.println(element.getName());//11.获取文本
System.out.println(element.getText());}}}}/*
输出
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.dom4j.io.SAXContentHandler (file:/C:/Users/80626/idea-workspace/Practice1/lib/dom4j-1.6.jar) to method com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser$LocatorProxy.getEncoding()
WARNING: Please consider reporting this to the maintainers of org.dom4j.io.SAXContentHandler
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
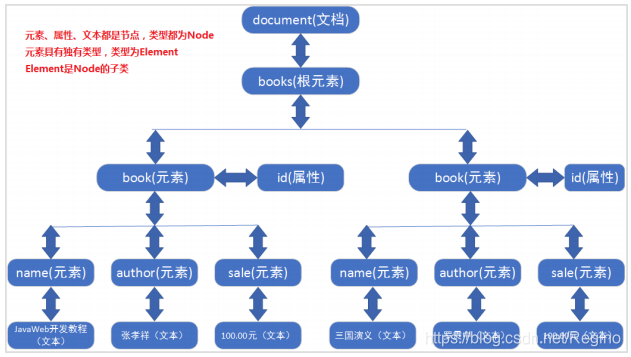
根标签是:books
子标签:book
属性id:0001
name
JavaWeb开发教程
author
张孝祥
sale
100.00元
子标签:book
属性id:0002
name
三国演义
author
罗贯中
sale
100.00元
*/
出现的 warning 是 jar 包版本和 JDK 的兼容性问题。
4. Dom4J 结合 XPath 解析 XML
a. 介绍
XPath 使用路径表达式来选取 HTML 文档中的元素节点或属性节点。节点是通过沿着路径(path)来选取的。XPath 在解析 HTML 文档方面提供了一独树一帜的路径思想。
b. XPath 使用步骤
步骤 1:导入 jar 包(dom4j 和 jaxen-1.1-beta-6.jar 执行 “set as Library”);
步骤 2:通过 dom4j 的 SaxReader 获取 Document 对象;
步骤 3:利用 Xpath 提供的 API,结合 XPath 的语法完成选取 XML 文档元素节点进行解析操作。
c. Document 常用的 API
方法
作用
List selectNodes(“表达式”)
获取符合表达式的元素集合
Element selectSingleNode(“表达式”)
获取符合表达式的唯一元素
d. XPath 语法
XPath 表达式,就是用于选取 HTML 文档中节点的表达式字符串。
获取 XML 文档节点元素一共有如下 4 种 XPath 语法方式:
绝对路径表达式方式,例如: /元素/子元素/子子元素…;
相对路径表达式方式,例如: 子元素/子子元素… 或者 ./子元素/子子元素…;
全文搜索路径表达式方式,例如: //子元素//子子元素;
谓语(条件筛选)方式,例如: //元素[@attr1=value]。
获取不同节点语法:
获取类型
语法代码
获取元素节点
元素名称
获取属性节点
@属性名称
i. 绝对路径表达式
格式: String xpath = “/元素/子元素/子子元素…”;
绝对路径是以 “/” 开头,一级一级描述标签的层级路径就是绝对路径,这里注意不可以跨层级;
绝对路径是从根元素开始写路径的,这里开头的 “/” 代表 HTML 文档根元素,所以在绝对路径中不可以写根元素路径;
import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;import java.io.File;import java.util.List;publicclassTest{publicstaticvoidmain(String[] args)throws DocumentException {//1.创建核心对象
SAXReader reader =newSAXReader();//2.读取xml文件
Document document = reader.read(newFile("Practice1/books.xml"));//3.使用Xpath//全文搜索路径表达式
List<Element> list = document.selectNodes("//sale");for(Element element : list){
System.out.println(element.getText());}//谓语表达式
Element ele =(Element) document.selectSingleNode("//book[@id='0001']/sale");
System.out.println(ele.getText());}}/*
输出
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.dom4j.io.SAXContentHandler (file:/C:/Users/80626/idea-workspace/Practice1/lib/dom4j-1.6.jar) to method com.sun.org.apache.xerces.internal.parsers.AbstractSAXParser$LocatorProxy.getEncoding()
WARNING: Please consider reporting this to the maintainers of org.dom4j.io.SAXContentHandler
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
100.00元
100.00元
100.00元
*/