《MySQL实战45讲》
Rows_examined:https://blog.csdn.net/weixin_34332905/article/details/90683568
恢复数据库:https://blog.51cto.com/laobaiv1/1960846
性能优化:https://www.cnblogs.com/angelica-duhurica/p/11303281.html
1 MySQL有哪些“饮鸩止渴”提高性能的方法
1.1 短连接风暴
解决:
方法1 先处理掉那些占着连接但是不工作的线程。
建议是处理掉查询任务之类的连接,插入的就不处理,避免数据库状态有损
方法2 减少连接过程的消耗。
让数据库跳过权限验证阶段
1.2 慢查询性能问题
在MySQL中,会引发性能问题的慢查询,有以下三种可能:
- 索引没有设计好;
- SQL语句没写好;
- MySQL选错了索引。
1.2.1 索引没有设计好
⼀般通过紧急创建索引来解决
MySQL 5.6版本以后,创建索引都支持Online DDL了,对于那种高峰期数据库已经被这个语句打挂了的情况,最高效的做法就是直接执行alter table 语句。
比较理想的是能够在备库先执行;
假设现在的服务是⼀主⼀备:主库A、备库B,这个方案的大致流程是这样的:
- 在备库B上执行
set sql_log_bin=off,也就是不写binlog,然后执行alter table语句加上索引; - 执行主备切换;
- 这时候主库是B,备库是A。在A上执行
set sql_log_bin=off,然后执⾏alter table 语句加上索引。
1.2.2 语句没写好
MySQL 5.7提供了query_rewrite功能,可以把输入的⼀种语句改写成另外⼀种模式。
1.2.3 MySQL选错了索引
应急方案就是给这个语句加上force index。
使用查询重写功能,给原来的语句加上force index,也可以解决这个问题。
1.2.4 总结
出现最多的是前两种,即:索引没设计好和语句没写好。
这两种情况,是完全可以避免的。
比如,通过下面这个过程就可以预先发现问题:
- 上线前,在测试环境,把慢查询日志(slow log)打开,并且把long_query_time设置成0,确保每个语句都会被记录入慢查询日志;
- 在测试表里插入模拟线上的数据,做⼀遍回归测试;
- 观察慢查询日志里每类语句的输出,特别留意Rows_examined字段是否与预期⼀致。
如果新增的SQL语句不多,⼿动跑⼀下就可以;
如果是新项目的话,或者是修改了原有项目的表结构设计,全量回归测试都是必要的,这时候需要工具来帮助检查所有的SQL语句的返回结果,比如开源工具pt-querydigest
1.3 QPS突增问题
有时候由于业务突然出现高峰,或者应用程序bug,导致某个语句的QPS突然暴涨,也可能导致MySQL压力过⼤,影响服务。
最理想的情况是让业务把这个功能下掉,服务自然就会恢复
下掉⼀个功能,如果从数据库端处理的话,对应于不同的背景,有不同的方法可用:
- 由全新业务的bug导致的:
假设DB运维是比较规范的,也就是说白名单是⼀个个加的,这种情况下,如果能够确定业务方会下掉这个功能,只是时间上没那么快,那么就可以从数据库端直接把白名单去掉。 - 如果这个新功能使用的是单独的数据库用户,可以用管理员账号把这个用户删掉,然后断开现有连接;
这样,这个新功能的连接不成功,由它引发的QPS就会变成0。 - 如果这个新增的功能跟主体功能是部署在⼀起的,那么我们只能通过处理语句来限制;
这时,我们可以使用查询重写功能,把压力最大的SQL语句直接重写成"select 1"返回。
第三步这个操作的风险很高,它可能存在两个副作用:
- 如果别的功能里面也用到了这个SQL语句模板,会有误伤;
- 很多业务并不是靠这⼀个语句就能完成逻辑的,所以如果单独把这⼀个语句以select 1的结果返回的话,可能会导致后面的业务逻辑⼀起失败。
2 MySQL的可靠性、IO优化
只要redo log和binlog保证持久化到磁盘,就能确保MySQL异常重启后,数据可以恢复。
MySQL写⼊binlog和redo log的流程是怎么样的?如何保证redo log真实地写⼊了磁盘?
2.1 binlog的写入机制
写⼊逻辑比较简单:事务执行过程中,先把日志写到binlog cache,每个线程⼀个;
当事务提交的时候,再把binlog cache写到binlog文件中:
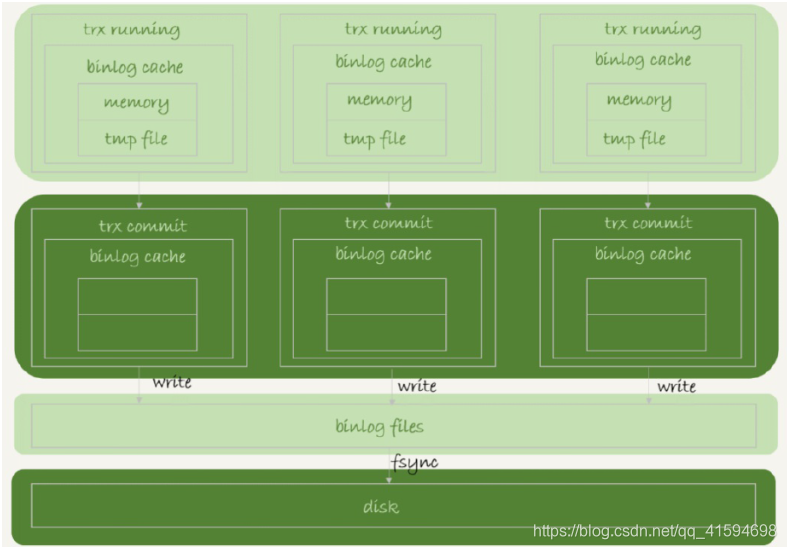
write指的是指把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快。
fsync指的是将数据持久化到磁盘的操作。⼀般情况下认为fsync才会占磁盘的IOPS。
sync_binlog控制write和fsync的时机:
- sync_binlog=0的时候,表示每次提交事务都只write,不fsync;
- sync_binlog=1的时候,表示每次提交事务都会执行fsync;
- sync_binlog=N(N>1)的时候,表示每次提交事务都write,但累积N个事务后才fsync。
2.2 redolog的写入机制
redolog的三种状态:对应图中三种颜色块
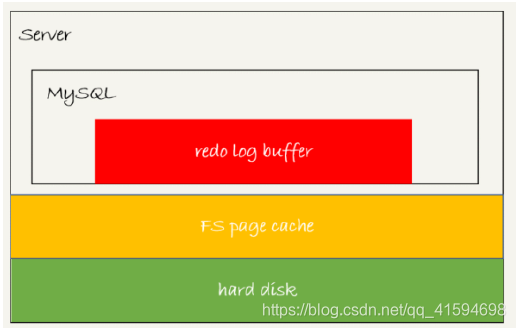
这三种状态分别是:
- 存在redo log buffer中,物理上是在MySQL进程内存中(红色);
- 写到磁盘(write),但是没有持久化(fsync),物理上是在文件系统的page cache里面(黄色);
- 持久化到磁盘,对应的是hard disk(绿色)。
innodb_flush_log_at_trx_commit参数控制了redolog的写入策略:
- 设置为0的时候,表示每次事务提交时都只是把redo log留在redo log buffer中,每隔固定时间写入page cache(操作系统缓存)并刷新到磁盘(只write,不fsync)
- 设置为1的时候,表示每次事务提交时都将redo log直接持久化到磁盘;
- 设置为2的时候,表示每次事务提交时都只是把redo log写到page cache(操作系统缓存),每隔固定时间刷新到磁盘
InnoDB有⼀个后台线程,每隔1秒,就会把redo log buffer中的日志,调用write写到文件系统的page cache,然后调用fsync持久化到磁盘。(包括没有提交事务,但是已经写到redo log buffer中的redolog)
除了后台线程每秒⼀次的轮询操作外,还有两种场景会让⼀个没有提交的事务的redo log写⼊到磁盘中:
- redo log buffer占用的空间即将达到
innodb_log_buffer_size⼀半的时候,后台线程会主动写盘。
注意,由于这个事务并没有提交,所以这个写盘动作只是write,⽽没有调用fsync,也就是只留在了文件系统的page cache。 - 并行的事务提交的时候,顺带将这个事务的redo log buffer持久化到磁盘。
假设⼀个事务A执行到⼀半,已经写了⼀些redo log到buffer中,这时候有另外⼀个线程的事务B提交,如果innodb_flush_log_at_trx_commit设置的是1,那么按照这个参数的逻辑,事务B要把redo log buffer里的日志全部持久化到磁盘。这时候,就会带上事务A在redo logbuffer里的日志⼀起持久化到磁盘。
如果事务没提交就崩溃了,但是有些更新操作进入了redolog且持久化到了磁盘,会产生数据不一致吗?答案是不会,因为Innodb会判断是否需要崩溃恢复,此时会判断为不需要
2.3 组提交机制
sync_binlog和innodb_flush_log_at_trx_commit都设置成 1(”双1“配置),⼀个事务完整提交前,需要等待两次刷盘,⼀次是redo log(prepare 阶段),⼀次是binlog。
那么如果从MySQL看到的TPS是每秒两万的话,每秒就会写四万次磁盘;
但是,用工具测试出来,磁盘能力也就两万左右,怎么会有两万的TPS?
因为使用了组提交机制:使用LSN(日志逻辑序列号)用来对应redo log的⼀个个写入点,每次写入长度为length的redo log, LSN的值就会加上length;
如图所示,是三个并发事务(trx1, trx2, trx3)在prepare 阶段,都写完redo log buffer,持久化到磁盘的过程,对应的LSN分别是50、120 和160:
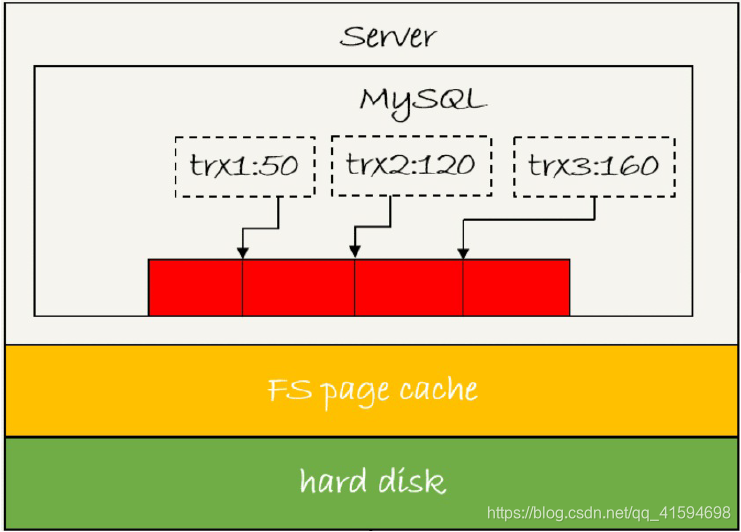

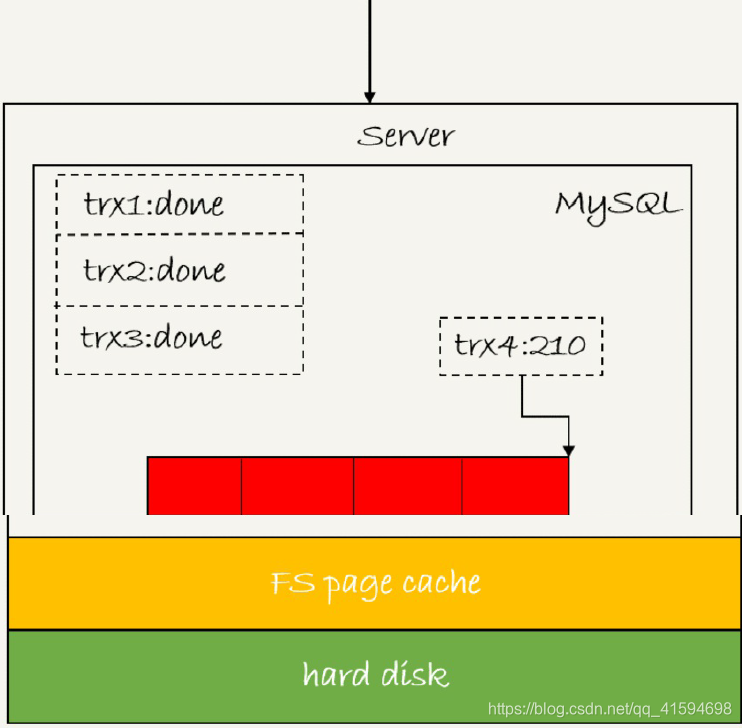
- trx1是第⼀个到达的,会被选为这组的 leader;
- 等trx1要开始写盘的时候,这个组里面已经有了三个事务,这时候LSN也变成了160;
- trx1去写盘的时候,带的就是LSN=160,因此等trx1返回时,所有LSN小于等于160的redo log,都已经被持久化到磁盘;
- 这时候trx2和trx3就可以直接返回了。
所以,⼀次组提交里面,组员越多,节约磁盘IOPS的效果越好,因此MySQL做了个优化:让fsync拖时间;
当然,如果只有单线程压测,那就只能⼀个事务对应⼀次持久化操作了。
如何拖时间?
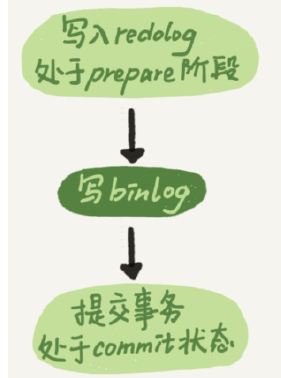
如图为两阶段提交,写binlog分为两阶段:
- 先把binlog从binlog cache中写到磁盘上的binlog文件;
- 调用fsync持久化。
MySQL为了让组提交的效果更好,把redo log做fsync的时间拖到了步骤1之后,可以积攒更多的redolog:
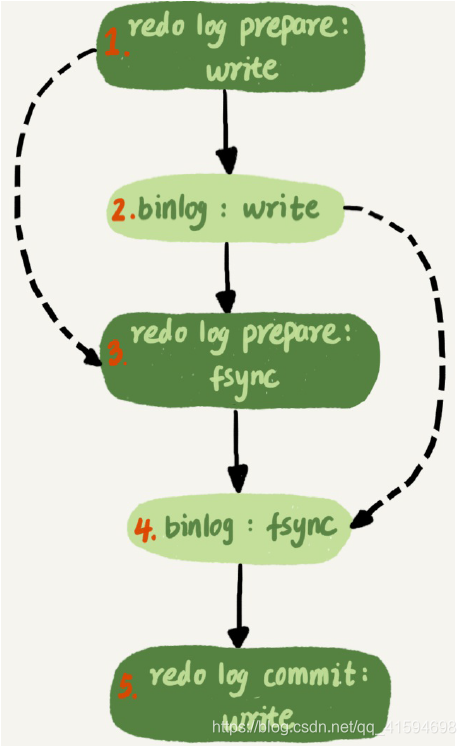
这样的话binlog也可以组提交了:在执行图5中第4步把binlog fsync到磁盘时,如果有多个事务的binlog已经写完了,也是⼀起持久化的,这样也可以减少IOPS的消耗。
但是通常情况下第3步执行得会很快,所以binlog的write和fsync间的间隔时间短,导致能集合到⼀起持久化的binlog比较少,因此binlog的组提交的效果通常不如redo log的效果那么好;
如果想提升binlog组提交的效果,可以通过设置 binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count来实现。
- binlog_group_commit_sync_delay参数,表示延迟多少微秒后才调用fsync;
- binlog_group_commit_sync_no_delay_count参数,表示累积多少次以后才调用fsync。
这两个条件是或的关系,也就是说只要有⼀个满足条件就会调用fsync;
所以,当binlog_group_commit_sync_delay设置为0的时候,binlog_group_commit_sync_no_delay_count也⽆效了。
2.4 总结
可以看到,WAL机制主要得益于两个方面:
- redo log 和 binlog都是顺序写磁盘,磁盘的顺序写比随机写速度要快;
- 组提交机制,可以大幅度降低磁盘的IOPS消耗。
如果MySQL现在出现了性能瓶颈,而且瓶颈在IO上,可以通过哪些方法来提升性能呢:
- 设置
binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count参数,减少binlog的写盘次数。
这个方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间,但没有丢失数据的风险。 - 将
sync_binlog设置为大于1的值(比较常见是100~1000);
这样做的风险是,主机掉电时会丢binlog日志。 - 将
innodb_flush_log_at_trx_commit设置为2;
这样做的风险是,主机掉电的时候会丢数据。
3 误删数据
误删数据的分类:
- 使用delete语句误删数据行;
- 使用drop table或者truncate table语句误删数据表;
- 使用drop database语句误删数据库;
- 使用rm命令误删整个MySQL实例。
- 数据行
使用Flashback工具通过闪回把数据恢复回来
Flashback恢复数据的原理:修改binlog的内容,拿回原库重放;
使用这个方案的前提是,需要确保binlog_format=row 和 binlog_row_image=FULL:
- 对于insert语句,对应的binlog event类型是Write_rows event,把它改成Delete_rows event即可;
- 同理,对于delete语句,也是将Delete_rows event改为Write_rows event;
- 而如果是Update_rows的话,binlog里记录了数据行修改前和修改后的值,对调这两行的位置即可。
如果误操作有多个,则要按相反顺序执行
不建议直接在主库上恢复,因为可能造成数据的二次破坏:可能已经在之前误操作的基础上,业务代码逻辑又继续修改了其他数据,如果这时候单独恢复这几行数据,而⼜未经确认的话,就可能会出现对数据的⼆次破坏。
事前预防:
- 把sql_safe_updates参数设置为on;
这样⼀来,如果忘记在delete或者update语句中写where条件,或者where条件里面没有包含索引字段的话,这条语句的执行就会报错;
如果真的要删除,则使用where id >= 0即可,且建议使用truncatetable或者drop table命令,性能较好 - 代码上线前,必须经过SQL审计。
使用delete命令删除的数据还可以用Flashback来恢复。而使用truncate /drop table和drop database命令删除的数据,就没办法通过Flashback来恢复了;
因为即使配置了binlog_format=row,执行这三个命令时,记录的binlog还是statement格式;
binlog里面就只有⼀个truncate/drop 语句,这些信息是恢复不出数据的。
那么,如果我们真的是使用这几条命令误删数据了,这种情况下,要想恢复数据,就需要使用全量备份,加增量日志的方式了
- 误删库/表
使用全量备份,加增量日志的方式要求线上有定期的全量备份,并且实时备份binlog。
使用mysqlbinlog来恢复数据:
- 取最近⼀次全量备份,假设这个库是⼀天⼀备,上次备份是当天0点;
- 用备份恢复出⼀个临时库;
- 从日志备份里面,取出凌晨0点之后的日志;
- 把这些日志,除了误删除数据的语句外,全部应用到临时库。(mysqlbinlog)
可以使用master-slave方法替代mysqlbinlog来加速:可以让临时库只同步误操作的表、可以用上并行复制技术
- 延迟复制备库
可以缩短恢复数据需要的时间
- 预防误删库/表的方法
账号分离
制定操作规范
- rm删除数据
对于⼀个有高可用机制的MySQL集群来说,只要不是恶意地把整个集群删除,而只是删掉了其中某⼀个节点的数据的话,HA系统就会开始工作,选出⼀个新的主库,从而保证整个集群的正常工作。
要做的就是在这个节点上把数据恢复回来,再接⼊整个集群
4 kill
能kill掉的:
1 比如执行⼀个查询的过程中,发现执行时间太久,要放弃继续查询,这时我们就可以用kill query命令,终止这条查询语句。
2 语句处于锁等待的时候、
当用户执行kill query thread_id_B时,MySQL里处理kill命令的线程做了两件事:
- 把事务的运行状态改成
THD::KILL_QUERY(将变量killed赋值为THD::KILL_QUERY); - 给事务的执行线程发⼀个信号。
kill无效的情况:即从show processlist结果上还存在,不过Command=Killed
1 线程没有执行到判断线程状态的逻辑,如锁等待、由于IO压力过大,读写IO的函数⼀直⽆法返回,导致不能及时判断线程的状态
2 终止逻辑耗时较长
kill的本质:
发送kill命令的客户端,并没有强行停止目标线程的执行,而只是设置了个状态,并唤醒对应的线程;
而被kill的线程,需要执行到判断状态的“埋点”,才会开始进⼊终止逻辑阶段;
并且,终止逻辑本身也是需要耗费时间,
5 大表的全表扫描
5.1 Server层
实际上,服务端并不需要保存⼀个完整的结果集。取数据和发数据的流程是这样的:
-
获取⼀行,写到net_buffer中。这块内存的大小是由参数net_buffer_length定义的,默认是16k。
-
重复获取行,直到net_buffer写满,调用网络接口发出去。
-
如果发送成功,就清空net_buffer,然后继续取下⼀行,并写⼊net_buffer。
-
如果发送函数返回EAGAIN或WSAEWOULDBLOCK,就表示本地网络栈(socket send buffer)写满了,进入等待,直到网络栈重新可写,再继续发送。
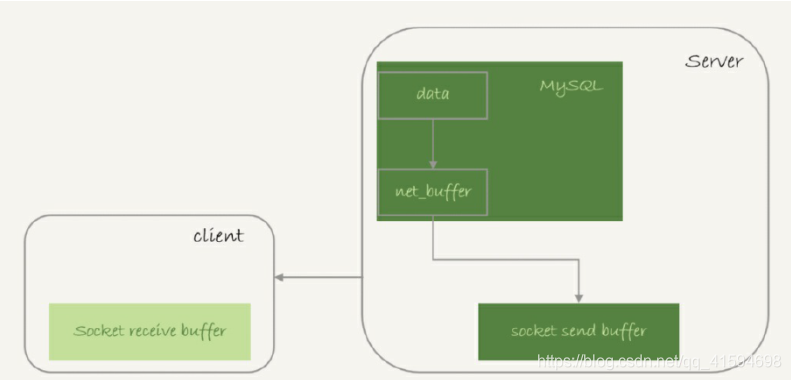
可以看到: -
⼀个查询在发送过程中,占用的MySQL内部的内存最⼤就是net_buffer_length这么大,并不会达到大表的所有数据那么大,比如200G;
-
socket send buffer 也不可能达到200G(默认定义/proc/sys/net/core/wmem_default),如果socket send buffer被写满,就会暂停读数据的流程。
对于正常的线上业务来说,如果⼀个查询的返回结果不会很多的话,建议使用mysql_store_result这个接口,直接把查询结果保存到本地内存;
如果太多的话就使用mysql_use_result方法,这个方法是读⼀行处理⼀行。
⼀个查询语句的状态变化:,“Sending data”并不⼀定是指“正在发送数据”,而可能是处于执行器过程中的任意阶段。
MySQL查询语句进⼊执行阶段后,首先把状态设置成“Sending data”;
然后,发送执行结果的列相关的信息(meta data) 给客户端;
再继续执行语句的流程;
执行完成后,把状态设置成空字符串。
5.2 InnoDB层
InnoDB内存管理(Buffer Pool)用的是最近最少使用 (Least Recently Used, LRU)算法,这个算法的核心就是淘汰最久未使用的数据,内部使用链表实现
为了避免非业务性的大表扫描把业务的数据全部从内存中清空,改进了此算法:按照5:3的比例把整个LRU链表分成了young区域和old区域(类似JVM内存区域的思想)
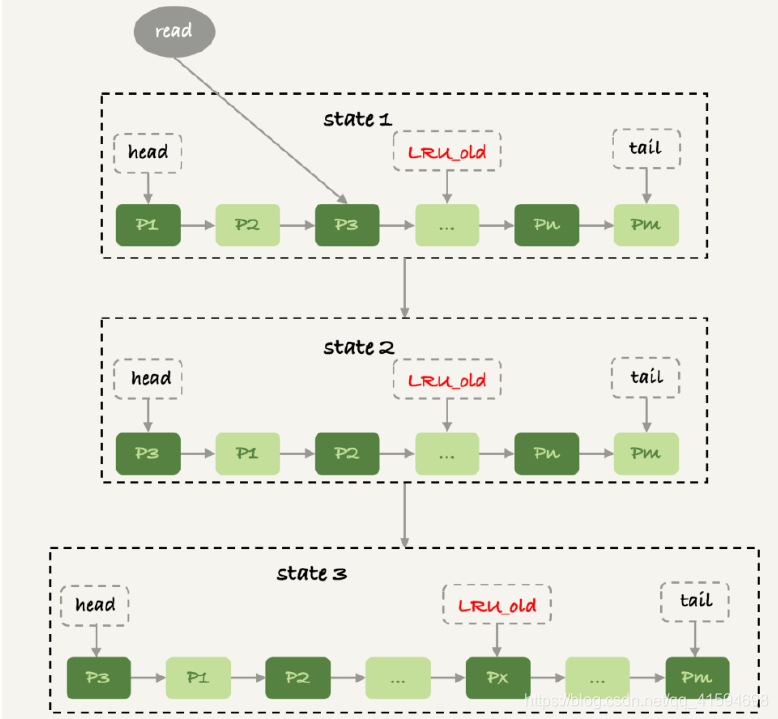
流程:
- 图中状态1,要访问数据页P3,由于P3在young区域,因此将其移到链表头部,变成状态2。
- 之后要访问⼀个新的不存在于当前链表的数据页,这时候淘汰掉最后一个数据页Pm,新插入的数据页Px放在LRU_old处
- 处于old区域的数据页,每次被访问的时候都要做下面的判断:
若这个数据页在LRU链表中存在的时间超过了1秒,就把它移动到链表头部;
如果这个数据页在LRU链表中存在的时间短于1秒,位置保持不变;
1秒这个时间,是由参数innodb_old_blocks_time控制的。其默认值是1000,单位毫秒。
这个策略,就是为了处理类似全表扫描的操作量身定制的;
以扫描200G的非业务、历史数据表为例,看看改进后的LRU算法的操作逻辑:
- 扫描过程中,需要新插⼊的数据页,都被放到old区域;
- ⼀个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第⼀次被访问和最后⼀次被访问的时间间隔不会超过1秒,因此还是会被保留在old区域;
- 再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是young区域),很快就会被淘汰出去。
可以看到,这个策略最大的收益,就是在扫描这个大表的过程中,虽然也用到了Buffer Pool,但是对young区域完全没有影响,从而保证了Buffer Pool响应正常业务的查询命中率。
6 grand和flush privileges
grant语句是用来给用户赋权的
grant语句会同时修改数据表和内存,判断权限的时候使用的是内存数据;
因此,规范地使用grant和revoke语句,是不需要随后加上flush privileges语句的。
flush privileges语句本身会用数据表的数据重建⼀份内存权限数据,所以在权限数据可能存在不⼀致的情况下再使用;
这种不⼀致往往是由于直接用DML语句操作系统权限表导致的,所以我们尽量不要使用这类语句。
7 性能分析explain
全部10列:id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra
7.1 id
每个 SELECT语句都会自动分配的一个唯一标识符.
表示查询中操作表的顺序,有三种情况:
id相同:执行顺序由上到下
id不同:如果是子查询,id号会自增,id越大,优先级越高。
id相同的不同的同时存在
id列为null的就表示这是一个结果集,不需要使用它来进行查询。
7.2 select_type
查询类型,主要用于区别普通查询、联合查询(union、union all)、子查询等复杂查询。
- SIMPLE
表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且
只有一个
- PRIMARY
一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。且只
有一个
- SUBQUERY
除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquery(select或where列表)
- DEPENDENT SUBQUERY
表示这个subquery的查询要受到外部查询的影响
- UNION
union连接的两个select查询,第一个查询是PRIMARY,除了第一个表外,第二个以后的表select_type
都是union
- DEPENDENT UNION
与union一样,出现在union 或union all语句中;
与dependent union类似,这个查询要受到外部查询的影响
- UNION RESULT
包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
- DERIVED
from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
7.3 table
显示的查询表名,如果查询使用了别名,那么这里显示的是别名
如果不涉及对数据表的操作,那么这显示为null
如果显示为尖括号括起来的就表示这个是临时表,后边的N就是执行计划中的id,表示结果来自于这个查询产生。
如果是尖括号括起来的<union M,N>,与类似,也是一个临时表,表示这个结果来自于union查询的id为M,N的结果集。
7.4 type
依次从好到差:
system>const>eq_ref>ref>fulltext>ref_or_null>unique_subquery>index_subquery>range>index_merge>index>ALL
一般要知道的是:
system>const>eq_ref>ref>range>index>ALL
建议到达range,最好能到ref
除了all之外,其他的type都可以使用到索引;
除了index_merge之外,其他的type只可以用到一个索引
优化器会选用最优的索引
- system
表中只有一行数据或者是空表。
- const
使用唯一索引或者主键,如将主键置于where中,通常type是const;
其他数据库也叫做唯一索引扫描
- eq_ref
关键字:连接字段主键或者唯一性索引。
此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 ‘=’, 查询效率较高.
- ref
针对非唯一性索引,使用等值(=)查询非主键。或者是使用了最左前缀规则索引的查询。
返回匹配某个单独值的所有行
- fulltext
全文索引检索
全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
- ref_or_null
与ref方法类似,只是增加了null值的比较。实际用的不多。
- unique_subquery
用于where中的in形式子查询,子查询返回不重复值唯一值
- index_subquery
用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
- range
索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
- index_merge
表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
- index
关键字:条件是出现在索引树中的节点的。可能没有完全匹配索引。
索引全表扫描,把索引从头到尾扫一遍,常见于:使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
- All
全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
7.5 possible_keys
此次查询中可能选用的索引,一个或多个
7.6 key
查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
7.7 key_len
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。
留意下这个列的值,算一下多列索引总长度就知道有没有使用到所有的列了。
另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
7.8 ref
显示索引的哪一列被使用了
如果是使用的常数等值查询,这里会显示const
如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段
如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
7.9 rows
这里是执行计划中估算的扫描行数,不是精确值(InnoDB不是精确的值,MyISAM是精确的值,主要原
因是InnoDB里面使用了MVCC并发机制)
7.10 extra
这个列包含不适合在其他列中显示单十分重要的额外的信息,这个列可以显示的信息非常多,有几十
种,常用的有:
distinct:在select部分使用了distinct关键字
no tables used:不带from字句的查询或者From dual查询
使用not in()形式子查询或not exists运算符的连接查询,这种叫做反连接;
即,一般连接查询是先查询内表,再查询外表,反连接就是先查询外表,再查询内表。using filesort:排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中
说明MySQL会使用一个外部的索引排序,而不是按照索引顺序进行读取。
MySQL中无法利用索引完成的排序操作称为“文件排序”using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
表示相应的SELECT查询中使用到了覆盖索引(Covering Index),避免访问表的数据行,效率不
错;
如果同时出现Using Where ,说明索引被用来执行查找索引键值
如果没有同时出现Using Where ,表明索引用来读取数据而非执行查找动作。using temporary:表示使用了临时表存储中间结果。
MySQL在对查询结果order by和group by时使用临时表
临时表可以是内存临时表和磁盘临时表,执行计划中看using where(重要):表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。
查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。
5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
8 优化步骤
五大思路,步骤层层递进,全部分为5个点来讲解
8.1 慢查询日志
可以使用mysqldumoslow来搜索慢查询日志中的SQL语句
更专业的话可以使用percona- toolkit
知道了哪些SQL比较慢之后,就可以具体针对SQL来分析了
8.2 profile
可以分析出一条SQL语句的硬件性能瓶颈,当然也可以show profile来得到sql的执行时间,替代第一步
8.3 服务器优化思路
- 将数据保存在内存中,保证从内存读取数据
- 内存预热
- 降低磁盘写入次数
- 提高磁盘读写
8.4 表设计优化
- 中间表的设计
- 冗余字段的设计
- 拆表字段
- 拆表数据
- hash拆分
- 冷热隔离
8.5 SQL优化
- limit优化
- 索引优化
- join优化
- orderby、groupby
- 最左前缀原则
- 范围条件(range)右边的所有条件全失效。
- 使用<、<=、>、>=等条件操作导致全表扫描失效。
- 一般最好写like查询的条件是"字符串%",而"%字符串%“与”%字符串"这两种形式是会导致索引失效;
用“覆盖索引:建立的索引与查询的字段最好在查询个数与顺序上完全一致”来解决; - 查询条件varchar类型的字符串不加单引号会导致索引失效。
- 少用or,用它来链接查询的是否也会导致索引失效。
- 索引列上无计算操作,不然也会到索引失效。
