文章目录
Scala 数组
scala中,有两种数组,一种是定长数组,另一种是变长数组
Scala的定长数组
- 定长数组指的是数组的长度是不允许改变的
- 定长数组的元素是可以改变的
- 在scala中,数组的泛型使用[]来指定
- 使用()来获取元素
语法:
// 通过指定长度定义数组
val/var 变量名 = new Array[元素类型](数组长度)
// 用元素直接初始化数组
val/var 变量名 = Array(元素1, 元素2, 元素3...)
例如:
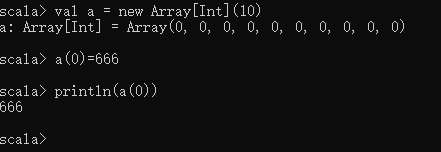
val a = new Array[Int](10)
a(0) = 666
println(a(0))
Scala的变长数组
- 变长数组指的是数组的长度是可变的,可以往数组中添加、删除元素
- 创建变长数组,需要提前导入ArrayBuffer类
import scala.collection.mutable.ArrayBuffer
语法:
创建空的ArrayBuffer变长数组
val/var a = new ArrayBuffer[元素类型]()
创建带有初始元素的ArrayBuffer
val/var a = ArrayBuffer(元素1,元素2,元素3....)
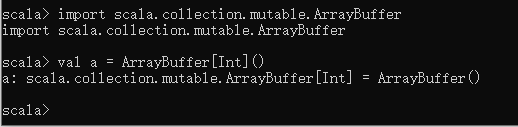
例如: 定义一个长度为0的整型变长数组
val a = ArrayBuffer[Int]()
例如:定义一个包含"zhangsan", “lisi”, "wangwu"元素的变长数组
val a = ArrayBuffer("zhangsan", "lisi", "wangwu")

Scala变长数组元素的添加,修改和删除
- 使用+=添加元素
- 使用-=删除元素
- 使用++=追加一个数组到变长数组
参考代码:
// 定义变长数组
scala> val a = ArrayBuffer("hadoop", "spark", "flink")
a: scala.collection.mutable.ArrayBuffer[String] = ArrayBuffer(hadoop, spark, flink)
// 追加一个元素
scala> a += "flume"
res10: a.type = ArrayBuffer(hadoop, spark, flink, flume)
// 删除一个元素
scala> a -= "hadoop"
res11: a.type = ArrayBuffer(spark, flink, flume)
// 追加一个数组
scala> a ++= Array("hive", "sqoop")
res12: a.type = ArrayBuffer(spark, flink, flume, hive, sqoop)
Scala数组的遍历
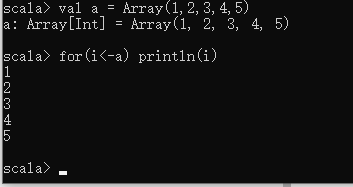
使用for表达式直接遍历数组中的元素
val a = Array(1,2,3,4,5)
for(i<-a) println(i)
使用索引遍历数组中的元素
val a = Array(1,2,3,4,5)
for(i <- 0 to a.length - 1) println(a(i))
for(i <- 0 until a.length) println(a(i))
to和until有个小区别,相信聪明的你已经观察出来了,如果你没看出来,点这里

Scala数组常用方法
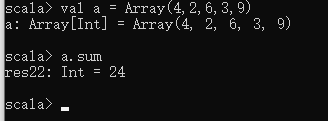
求和——sum方法
val a = Array(4,2,6,3,9)
a.sum
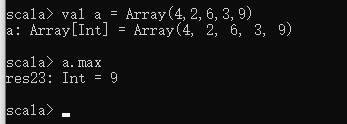
求最大值——max方法
val a = Array(4,2,6,3,9)
a.max
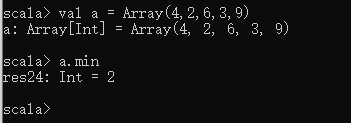
求最小值——min方法
val a = Array(4,2,6,3,9)
a.min
Scala数组的排序
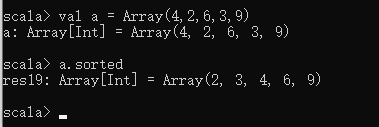
升序(从小到大)排序
val a = Array(4,2,6,3,9)
a.sorted
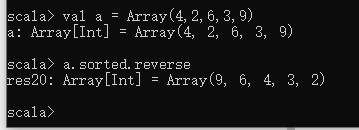
降序(从大到小)排序 (相当于先升序排序,再反转)
val a = Array(4,2,6,3,9)
a.sorted.reverse
Scala数组的其它方法
实在太多放不下,请自行查阅本地scala版本对应的API文档(英文的)。
一般的,API文档就在scala安装目录下的\api\scala-library\index.html中
E:\soft\scala2.11.12\api\scala-library\index.html
打开这个文件可以看到如下界面,在左上角输入Array即可查看所有的方法介绍。

同理,其它不会使用的方法也可以查看API文档。
