Linux内核中的无限循环
内核中无限循环的写法有for( ; ; ),while(1),while(true)
内核代码中的for( ; ; )
内核代码中的while(1)
内核代码中的fwhile(true)
这三种写法有什么区别?
这和编译器有关
- 在VS2010中进行测试
在循环处设置断点,并开启调试,然后反汇编,可以看到for( ; ; ),while(1)的汇编语句。


可以很明显的看到,for(;;)只有1句,while(1)有4句,而且for(;;)不占用寄存器,也没有判断跳转(并不是不能跳转)。
总结:for(;;)指令少,不占用寄存器,也不需要判断跳转。因此for(;;)写法执行效率更高。
while(true)需要包含C99标准中的<stdbool.h>头文件,但是VS2010中的编译器对C99标准没有很好的支持,并没有包含这个头文件,所以while(true)没有测试成功。
 可以想到的是,true就是一个宏,它的值为1,所以它的汇编和while(1)应当是一样的。
可以想到的是,true就是一个宏,它的值为1,所以它的汇编和while(1)应当是一样的。
- 在GCC中进行测试.
对于gcc来说,情况有所不同。经过反汇编后,发现三种写法的汇编语句是一样的,这得益于GCC强大的优化功能。GCC在编译时候进行优化(具体如何优化,需要编译原理的知识了),屏蔽掉了差异,因为三者本质都是表示无限循环(或者死循环),所以使用objdump工具反汇编后,看到三者的汇编语句是一样的。
测试代码:
- for( ; ; )
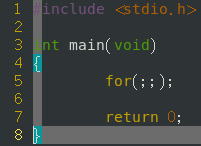
- while(1)
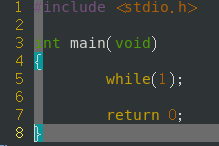
- while(true)

用gcc (GCC) 4.8.5编译后,使用objdump反汇编,分别对应如下:
- for(;;)反汇编后的汇编语句
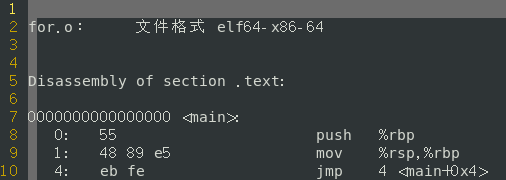
- while(1)反汇编后的汇编语句

- while(true)反汇编后的汇编语句
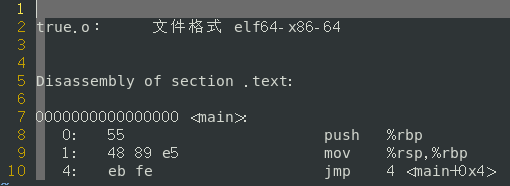
可以看出经过GCC优化之后,三种写法的汇编是一样的。所以在UNIX/Linux环境中编程,使用三者之一均可。但我更偏向于for(;;)这种写法,除了这种写法很“秀”之外,另一个原因就是在代码移植的时候,尤其是向windows平台,在底层指令实现的时候,无疑for(;;)的效率更高,而且也可以摆脱windows下编译器报警告的困扰。
- 选择for(;;)而不是while(1)的另外两层原因
- 更改为for(;;)可以消除警告,可以有意创建无限循环。
- 没有“永远为真”的条件,编写起来更短。for(;;)7个字符,while(1)8个字符
for(;;)的含义
for循环包含三个部分
- 一个预循环部分,在循环开始之前执行。
- 连续条件部分,尽管缺省时为true,但将使循环继续进行。
- 迭代部分,该部分在循环主体的每次迭代之后执行。
基本上,可以将for循环视为:
for (setup; test; advance)
...
如果“测试”(test)为空,则将其视为true,并且循环继续运行。空的“设置”(setup)和“前进”(advance)根本不起作用。
扫描二维码关注公众号,回复: 10324930 查看本文章
所以,for(;;)在逻辑上就是表达无限循环的意思。
.
