一、为什么要这么搞,此方法是我同事告诉我的,思路大概是:建立一个中间件(数据库表)。
场景:多数情况,我们用IN查询,里面有重复值,mysql会自动过滤IN里面的重复值,造成查询的结果是小于IN里面的条数,但是某些特殊情况,我们是不需要那么做的,我为什么会思考这种情况,如下是业务给我的小需求。
1、给了我一批客户id,大概有6千多条,需要知道这批id的客户名称,补充到excel表的后面一一对齐,但是通过excel高亮重复可以看到这批数据是有重复,由于数据库这个字段是字符串类型建立,所以通过excel的公式="’"&A1&"’," 转成有引号的形式,由于表数据量比较大,避开不走索引,全局扫描。

2、模拟IN查询,可以看出我们想要条数是13条,由于重复了,只获取到12条,所以这不是我们想要的,如果数据大,不采取其它措施,难搞哟。

3、因此,想到了数据库创建一个临时表,来关联查询。

4、通过excel导入该字段就行了,具体导入作为开发人员这里应该不用说了。
5、关联查询就可以了,然后导出结果,拷贝到相应excel里面,给需求方即可。
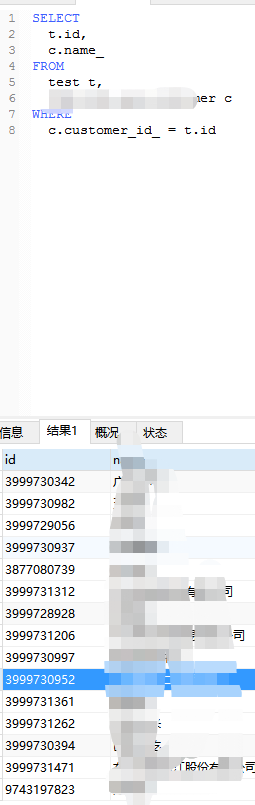
mysql的sql查询IN里面有重复的值,怎么不去重查询,这是一条思路

猜你喜欢
转载自blog.csdn.net/weixin_43137113/article/details/105120318
今日推荐
周排行