前言
逻辑回归的因变量常为二元分类变量(可为多元),自变量可以是分类变量也可以是连续变量。他早就成为各行业广泛运用的分类模型之一。
逻辑回归除了和其他模型一样喜欢干净数据外,还特别喜欢因变量为二分类变量的数据(多次重复,贼重要)。也就是当你的因变量是超二分类变量的时候,要尽最大的努力将其归并为二分类,如此甚好。
基本原理
关于逻辑回归,360百科:https://baike.so.com/doc/6732765-6947090.html给出了小白化介绍。我不会再赘述,但对其中的关键点划重点还是能做到。
Attention To Key
Key 1 前世今生
逻辑回归长什么样?怎样长成这个样子的呢?
这就要从线性回归模型说起。对于连续型变量来说,线性回归非常好解释。由于其用普通最小二乘法(OLS Regression)拟合,预测区间从负无穷滚向正无穷,有些预测值在分类变量的实际问题中是不好解释的。而且,普通最小二乘法的要求比较苛刻,要求变量分布服从正太分布。而二分类变量为二项分布,是非正太的。
到此,引入线性概率模型(Linear Probability)就理所当然了。线性概率模型其实也有不足之处。概率取值在[0,1]上,Linear Probability 的预测值会很飘,飘出[0,1]范围就不是我们喜欢的样子了。So? 再将模型塑个型,逻辑回归模型也就顺理成章的被用来解决因变量是分类变量的问题。

Key 2 轮回审判
轮回审判?还不如说是数据分析师对所建模型优劣的灵魂拷问。
模型优劣?在商业环境中,人们喜欢优益,也就要求模型“快”,“准”,“稳”。这个要求往往是理想主义者的梦中情人,现实点说,很难实现。当模型的评估不通过时,需要反复对数据与模型进行调修,这个过程是极度不舒适的。所以再强调一下:数据清洗一定到位,对模型的应用场景要熟悉,对业务要理解。不然,建立的模型泛化能力会很差,“审判”不通过,便只能将模型打入“轮回”,直到模型的评估通过为止。
通过什么来“审判”?ROC曲线(https://baike.so.com/doc/5499846-5737282.html)是非常好用的工具了!这里直接上一盘偷拍:

Logistic回归构建初始信用评级-R实战
上面介绍了Logistic回归,这里通过R软件来实现。做好准备,R相对于python来说更容易上手,只是需要添加很多第三方开源包(R的优势)。
建模准备
汽车违约贷款数据:
加载数据集及相关第三方包
accepts<-read.csv("F:\\R语言\\data\\accepts.csv",stringsAsFactors = F)
library(prettyR)
library(carData)
library(car)
library(ROCR)
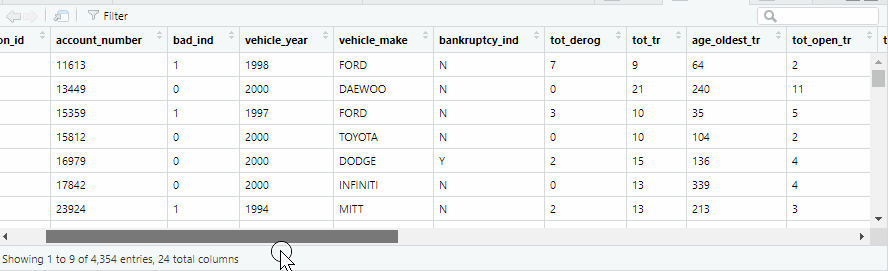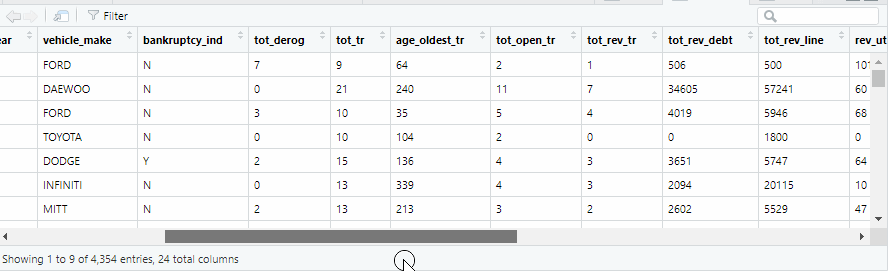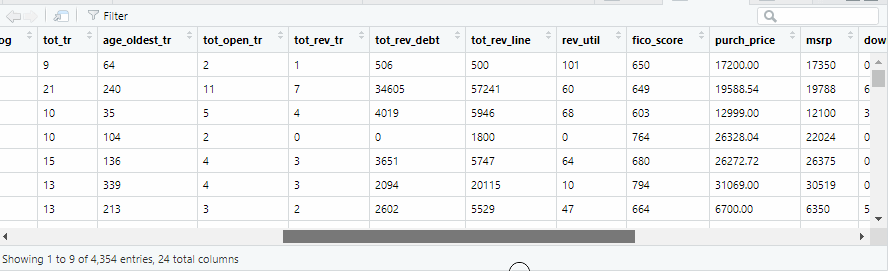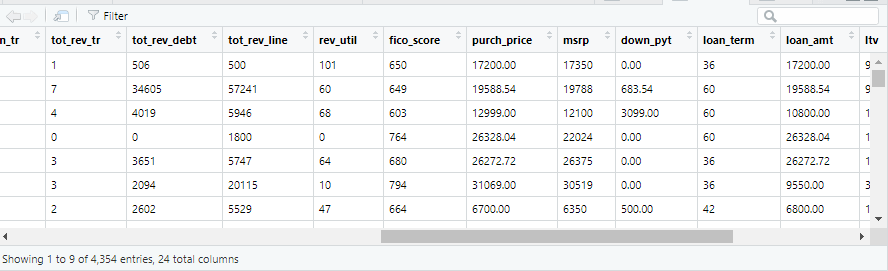
数据探查与处理
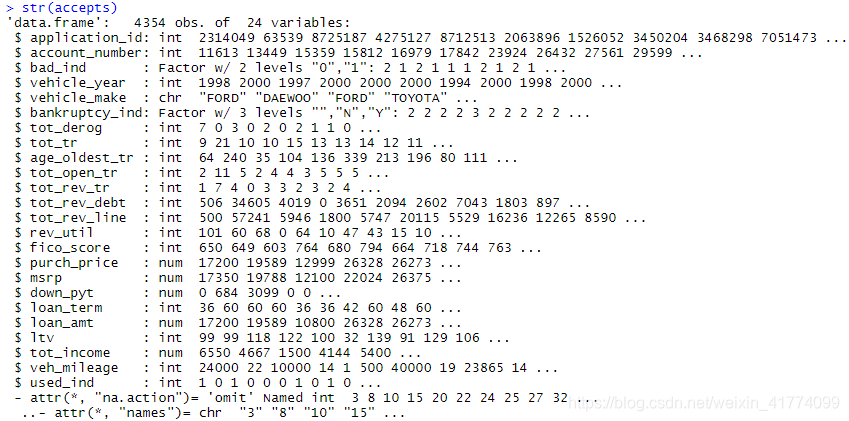
可以看到数据的各类变量类型及取值,以及是否有缺失值等!对于缺失值这里采取直接删除行记录,分类变量做因子化处理。
str(accepts)
#分类变量因子化
accepts$bad_ind<-as.factor(accepts$bad_ind)
accepts$bankruptcy_ind<-as.factor(accepts$bankruptcy_ind)
##建立训练集与测试集
accepts<-na.omit(accepts)#去掉Na行记录
attach(accepts)
set.seed(100)
select<-sample(1:nrow(accepts),length(accepts$application_id)*0.7)
train=accepts[select,]
test=accepts[-select,]
模型建立
模型探索—变量筛选
将意向变量放入多元logistic回归函数glm中,检验模型的效果:
##多元logistic回归
lg<-glm(bad_ind ~fico_score+bankruptcy_ind+tot_derog+age_oldest_tr+rev_util +
ltv+ veh_mileage,family=binomial(link='logit'))
summary(lg)
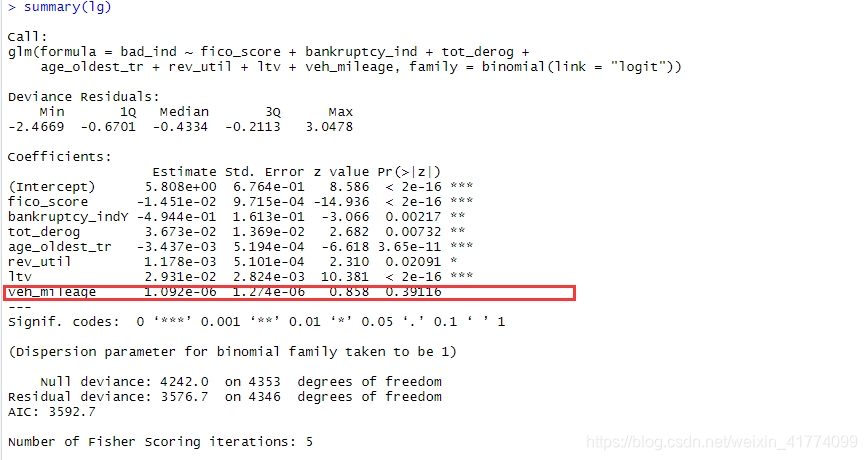
veh_mileage变量的P值较大,不应融入模型。应该重新对模型进行筛选。线性回归中的向前回归和先后回归以及逐步回归筛选的方法在逻辑回归中依然有用。这里用逐步回归筛选:
##进行逐步logsitic回归
lg_ms<-step(lg,direction = "both")
summary(lg_ms)
lg<-glm(bad_ind ~fico_score+bankruptcy_ind+age_oldest_tr+rev_util+ltv,
family=binomial(link='logit'))
summary(lg)

可以看到筛选出来的变量的P值都比较小,对模型是有帮助的优质变量。
多重共线性检验
多重共线性用方差膨胀因子(Vif)来检查。一般认为Vif不大于10位非多重共线性变量。可知,逐步回归筛选出来的变量间的Vif都小于10.通过多重共线性检查。如果检查未通过的话,需要对变量进行处理,比如降维(PCA,因子分析),或者换更模型岭回归(逻辑回归的升级版)等。
vif(lg_ms)

得到模型
bad_ind = 5.8387633 -0.0145523* fico_score
-0.4963368*bankruptcy_indY+0.0369379 *tot_derog
-0.0034479*age_oldest_tr+0.0011731*rev_util
+0.0295138*ltv
模型评估
不只是逻辑回归采用Roc曲线工具进行模型评估,很多分类器模型都如此。Roc涉及的还有混淆矩阵这个概念,这里不细说。
##预测
train$p<-predict(lg_ms, train,type='response')
test$p<-predict(lg_ms, test,type='response')
pred_Te <- prediction(test$p, test$bad_ind)
perf_Te <- performance(pred_Te,"tpr","fpr")
pred_Tr <- prediction(train$p, train$bad_ind)
perf_Tr <- performance(pred_Tr,"tpr","fpr")
plot(perf_Te, col='blue',lty=1);
plot(perf_Tr, col='black',lty=2,add=TRUE);
abline(0,1,lty=2,col='red')
lr_m_auc<-round(as.numeric(performance(pred_Tr,'auc')@y.values),3)
lr_m_str<-paste("Mode_Train-AUC:",lr_m_auc,sep="")
legend(0.58,0.15,c(lr_m_str),2:4,cex=0.6,bty="n",fill='blue')
lr_m_auc<-round(as.numeric(performance(pred_Te,'auc')@y.values),3)
lr_m_str<-paste("Mode_Test-AUC:",lr_m_auc,sep="")
legend(0.58,0.1,c(lr_m_str),2:4,cex=0.6,bty="n",fill='black')#fill='black'
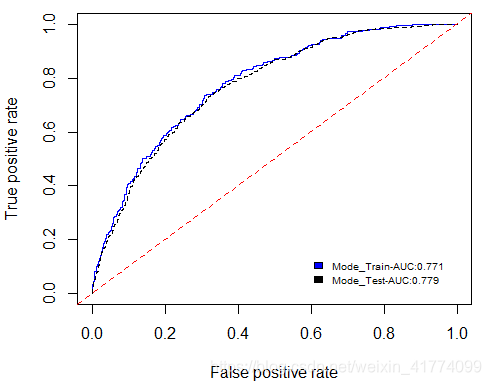
从上图可以看到,模型在训练数据和测试数据中表现都还好,AUC值都有70%+,在实际问题的处理中,这样的一个模型效果算一般。这里给一个模型评估的Roc阈值表:
| ROC阈值 | 意义 |
|---|---|
| [0.5,0.7) | 效果较低,但要用于股票预测,已经比较厉害了 |
| [0.70.85) | 效果一般般 |
| [0.85,0.95) | 效果比较棒 |
| [0.95,1] | 效果牛X,但好像太过于理想了,需要慎重 |
总结
数据分析放在古代可能叫账房或者军师,这样说是没毛病的。我们要对数据熟悉、对业务熟悉、对模型熟悉、对运算工具熟悉。很多东西更多的要求通,而不是精(能精的话,谁不想呢,加油!),更多要求应变而非墨守成规,更多要求懂得移花接木(就像绝代双骄里的那门功夫或者像倚天屠龙记里的乾坤大罗移)。这些好像扯远了,具体点:
| 事项 | 重要程度 |
|---|---|
| 业务理解 | ***** |
| 数据预处理 | ***** |
| 模型选择 | ***** |
| 模型评估与修正 | ***** |
好吧,这不像是总结 ~~~,列出来的都是重点。在之后的数据分析工作中,多学多实践,加油!
