编程界的小学生
一、原理
下面两篇博客已经把RDB和AOF讲透了。
1、RDB优缺点以及原理
2、AOF优缺点以及原理
二、面试:RDB与AOF哪个快?
1、分析
这道题不严谨,因为不知道他问的是持久化过程哪个快还是说Redis主进程对外提供请求哪个快?(也就是说哪个持久化方式会对主进程影响较大)
2、持久化过程哪个快
那肯定AOF,因为AOF每次只追加命令,而RDB每次都是全量覆盖。
3、哪个持久化方式会对主进程影响较大
那肯定是AOF效率低,因为AOF是串行的,相当于每次处理完命令都要同步的写入磁盘(当然也看具体策略),而bgsave模式的RDB则是开启子进程并行的处理这件事,不影响主进程对外提供请求,即使AOF策略开到最容易丢失数据的那种,那也是不定期磁盘操作,这是毫秒级别的。而RDB持久化即使发生CopyOnWrite也只是寻址操作,纳秒级别的。
三、文件格式
1、RDB
1.1、文件在哪
在哪是可配置的,在redis.conf里有如下配置:
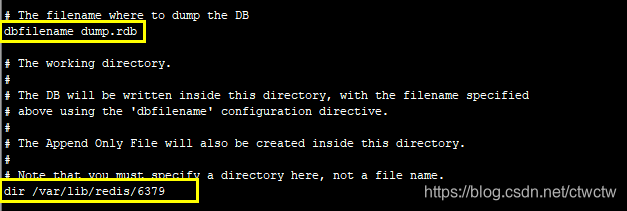
1.2、文件格式
- 以rbd后缀结尾
- 以REDIS开头的二进制格式,所以体积很小。
cd /var/lib/redis/6379

2、AOF
2.1、文件在哪

还在上面那张图里的dia /var/lib/redis/6379文件夹下,名字叫appendonly.aof。
2.2、文件格式
首先需要开启aof,为了方便测试再将策略改为每次执行命令都aof。
appendonly yes
appendfsync always
# 重启redis
service redis_6379 restart
# 客户端连接
redis-cli
# 执行命令
set t1 123
这时候会在/var/lib/redis/6379目录下生成一个aof文件。
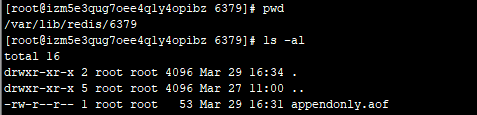
来看下aof内容

PS:其实这个格式内容我打算放到实战篇写的,想了下,算了,就在这干吧!
来翻译下:
首先Redis是以行来划分,每行以\r\n行结束。每一行都有一个消息头,消息头共分为5种分别如下:
(+) 表示一个正确的状态信息,具体信息是当前行+后面的字符。
(-) 表示一个错误信息,具体信息是当前行-后面的字符。
(*) 表示消息体总共有多少行,不包括当前行,*后面是具体的行数。
($) 表示下一行数据长度,不包括换行符长度\r\n,$后面则是对应的长度的数据。
(: ) 表示返回一个数值,:后面是相应的数字节符。
有了上面的基础再来看这个aof文件的内容
*2:两行,也就是往下数两行,也就是SELECT 0这两行。意味着选择第一个库。
$6:就代表SELECT有6个字节长度。
$1:就代表0的长度是1。
*3:三行,也就是set t1 123
以此类推
三、混合持久化
Redis4.0以及以后新增的内容,很强大。默认开启,也建议开启。但具体还要看业务,比如业务就允许数据丢失,那直接RDB就完事了,不需要开AOF,这样效率还高。如果一点数据都不允许丢失,那只能RDB+always策略的AOF,换言之,不管怎样,都建议开启RDB,RDB可以应对灾难性快速恢复。
看这篇文章的【五、RDB-AOF混合持久化】部分就够了
彻底搞懂Redis持久化之AOF原理
这里多说下混合持久化的格式。
刚我们看了aof的格式是这样的,可以发现很占用空间

那么我们手动触发AOF的rewrite功能(注意这里是混合模式),执行bgrewriteaof命令即可手动触发

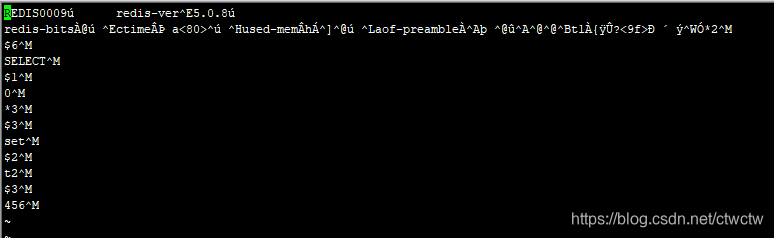
这时候我们会发现文件大小发生了变化,由于我只执行了set t1 123这条命令,本身就很小,所以看不大小占用问题。数据大的情况很明显。我们还可以看下文件内容

发现我们的aof文件变成了rdb格式,二进制格式。
我们继续发送命令set t2 456,然后再观察aof文件内容,会发现变成混合模式了,前半部分RDB,后半部分AOF,当下次再触发REWRITE的时候,AOF又会被压缩成二进制,变成RDB。这就是混合模式。
四、个人公众号
微信公众号【Java码农社区】

