#2020/3/3 ~
#不定时查错补缺
(如果哪里有错误,希望可以联系Q2278326006,非常感谢)
目录
前言:为什么学习了C语言基础之后,发现自己还是写不出漂亮高效的代码。其实根本原因就是基础毕竟是基础,所谓掌握C语言。要时刻记住代码在内存中的位置时刻知道代码在内存中是如何规划的。心中有内存,眼睛是编译器。有我无C。多么伟大艰难的梦想。
-
内存机构

C语言的程序经过编译之后在内存中的分配形式如右图,
1. Text/Code Segment 文本/代码区
2. Initialized Data Segments 初始化的数据区(常量)
3. Uninitialized Data Segments 未初始化的数据区(静态)
4. Heap Segment 堆区
5.Stack Segment 栈区
数据由低地址指向高地址 分为只读和动态,动态里面最重要的是堆和栈还有静态存储区的理解
- 只读区就是存放代码和常量的地方,没有动态的改动
- 动态区就是动态改变呗
-
Text/Code Segment 文本/代码区
这个区主要用来保存机器代码,一个可执行对象文件的文本区通常是只读区,可以防止程序被意外修改。
-
Initialized Data Segments 初始化的数据区(常量)
初始化的数据区存储了所有的初始化了的全局的,静态的,常量的,外部的变量。这些变量没有在函数内部定义或者是以静态的方式在函数内部定义了
-
Uninitialized Data Segments 未初始化的数据区(静态)
未初始化的数据区,又称作BSS (Block Started by Symbol),这个区一般紧连着初始化的数据区,用来保存所有的初始化为0的全局变量和静态变量,或者没有初始化,比如 static int i;将会存在BSS中。
- Stack Segment 栈区 (后进先出)分配存放的是函数参数值、局部变量值等,执行函数调用时,系统在栈上为函数内的形参和局部变量开辟空间,函数结束会自动释放这些空间,。同时栈分配效率高没有内存碎片这种问题,是连续分配的哦
- Heap Segment 堆区 堆上分配空间,在程序运行过程中,用动态内存分配函数来申请的内存是从堆上分配的,通过malloc, realloc和free等来管理。堆区被所有线程,公用库,动态加载模块所共享。动态内存的生存期由程序员决定。分配效率低,如果频繁使用会造成内存碎片的内部碎片。会造成内存不足
-
关键字
| auto | 声明自动变量 |
| int | 声明整型变量 |
| double | 声明双精度变量 |
| long | 声明长整型变量 |
| char | 声明字符变量 |
| float | 声明浮点型变量 |
| short | 声明短整形变量 |
| signed | 声明有符号类型变量 |
| unsigned | 声明无符号类型变量 |
| struct | 声明结构体变量 |
| union | 声明联合数据类型变量 |
| enum | 声明枚举类型变量 |
| static | 声明静态变量 |
| switch | 用于开关变量 |
| case | 用于语句分支 |
| default | 开关语句中的其他分支 |
| break | 跳出当前循环 |
| continue | 结束当前循环,开始下一轮循环 |
| register | 声明寄存器变量 |
| const | 声明只读变量,其修饰的只读变量必须在定义的同时初始化 |
| volatile | 直接存取原始内存地址 |
| typedef | 用以给数据类型取名 |
| extern | 声明变量是在其他文件中声明 |
| return | 子程序返回语句 |
| void | 声明函数无返回值或者无参数,声明空类型指针 |
| do | 循环语句的循环体 |
| while | 循环语句的循环条件 |
| for | 一种循环语句 |
| if | 条件语句 |
| else | 条件语句否定分支 |
| goto | 无条件跳转 |
| sizeof | 计算对象所占内存空间大小 |
较为特殊的关键字:
- volatile关键字: volatile提醒编译器它后面所定义的变量随时都有可能改变,因此编译后的程序每次需要存储或读取这个变量的时候,告诉编译器对该变量不做优化,都会直接从变量内存地址中读取数据,从而可以提供对特殊地址的稳定访问。。如果没有volatile关键字,则编译器可能优化读取和存储,可能暂时使用寄存器中的值,如果这个变量由别的程序更新了的话,将出现不一致的现象。(简洁的说就是:volatile关键词影响编译器编译的结果,用volatile声明的变量表示该变量随时可能发生变化,与该变量有关的运算,不要进行编译优化,以免出错)
中断服务程序中修改的供其它程序检测的变量,需要加volatile;
当变量在触发某中断程序中修改,而编译器判断主函数里面没有修改该变量,因此可能只执行一次从内存到某寄存器的读操作,而后每次只会从该寄存器中读取变量副本,使得中断程序的操作被短路。
多任务环境下各任务间共享的标志,应该加volatile;在本次线程内, 当读取一个变量时,编译器优化时有时会先把变量读取到一个寄存器中;以后,再取变量值时,就直接从寄存器中取值;当内存变量或寄存器变量在因别的线程等而改变了值,该寄存器的值不会相应改变,从而造成应用程序读取的值和实际的变量值不一致 。
存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义;假设要对一个设备进行初始化,此设备的某一个寄存器为0xff800000。for(i=0;i< 10;i++) *output = i;前面循环半天都是废话,对最后的结果毫无影响,因为最终只是将output这个指针赋值为9,省略了对该硬件IO端口反复读的操作。
可以看出这个关键字在微机编程和有编译器优化的环境下效果尤为重要。
-
register 这个关键字命令编译器尽可能的将变量存在CPU内部寄存器中而不是通过内存寻址访问以提高效率。而且它的大受制于硬件的寄存器大小,并不是意味着只要加了这个关键字定义变量,这个变量就是存在寄存器中了。只是在寄存器资源充足情况下才是如果定义成功的话,对这个变量取地址时编译器会发出错误信息,因为编译器找不到这个变量的内存地址了,它已经是存在硬件的寄存器中了;
-
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值,必须定义时初始化哦
-
void 这个关键字就很有意思了,是空的,除了声明函数返回值为空之外,还有一个重要的使用途径就是创建以后空类型的指针,空类型的指针有什么用处,主要就是用来做一个返回指针类型不确定的函数的返回值,调用后需要进行指针类型强制转换,还可以定义空类型指针变量 比如 void *p;
-
const 可以保护被修饰的变量,防止意外修改,可也以修饰指针,声明时必须初始化
-
typedef 这个关键字主要是用来其别名。常用来给结构体其别名
-
预编译指令
| #include | 最为常见的预处理,作为文件的引用 包含一个源代码文件 |
| #define | 定义宏 |
| #undef | 未定义宏 |
| #if | 如果给定条件为真,则编译下面代码 |
| #ifdef | 如果宏被定义,则编译下面代码 |
| #ifndef | 如果宏未被定义,则编译下面的代码 |
| #elif | 如果前面的#if给定条件不为真,当前条件为真,则编译下面代码 |
| #endif | 结束一个#if…#else条件编译块 |
| #error | 停止编译并显示错误信息 |
| #line | 改变编译器用来指出警告和错误信息的文件号和行号 |
| #pragma | 为编译程序提供非常规的控制流信息 |
预定义标识符:
为了处理一些有用的信息,预处理定义了一些预处理标识符,虽然各种编译器的预处理标识符不尽相同,但都会处理下面四种:
__FILE__:正在编译的文件名 __LINE__:正在编译的文件的行号
__DATE__:编译时刻的日期字符 __TIME__:编译时刻的时间字符串
其中有几个经常使用:
#include <> 表示程序从系统自带的头文件路径去搜索没有着再来搜索用户路径,#include " " 则相反。
#ifndef #define #endif 这三个组合有利于模块化程序设计
例如: #ifndef _NAME_H_
#define _NAME_H_
...
#endif
这样的意义是第一次引用这个头文件的时候,会为该文件宏定义一个 _NAME_H_ 的名字了,后面如果为了程序可读性增强可能还会接着多次引用这个头文件,此时就会防止多次引用而引发编译器发出警告。因为第一次引用已经定义了 _NAME_H_这个入口,所以#ifndef 就会不满足,编译器直接过滤掉这一部分内容了。所以 例如 _NAME_H_ 这名字必须在整个工程里是一对一关系的,不能重复命名。
-
指针应用
所谓指针就是指向内存地址,内存中存储的东西都是有地址的,然而通过地址去访问这个地址里面的东西小效率高,而且衍生出一系列精妙的算法和数据结构,C语言指针是C语言能在这么多语言中的德高望重的一个重要原因。
编写C语言变量的时候,通常用直接寻址方式, 定义就是 【变量 变量名】。这种方式就是直接寻址,变量被赋予了一个地址,内存会直接通过这个地址寻址这个变量,然后指针呢 ,通过指针可以实现间接寻址。指针就是一个中间人 ,通过它来寻找变量了,指针是C语言的精髓,有了它可以实现很多不能实现的功能,代码更加具有可用性封装性可移植性,说白了指针就是一个外部介入者,但是它直接让用户编程和内存连通起来了。
那么指针占用多少内存空间呢?我们知道指针有很多种类型 char int float 数组 结构体 一级 二级等等
但是记住一点,不管类型的指针它们占用的空间都是固定的哦,它占用的内存空间由机器决定,可以通过sizeof来确定,例如

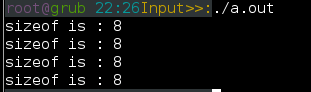
输出都是8个字节,因为我的环境是64位机。
基本指针类型:
#include "stdio.h"
#define N 2
void fen(int num[],float *m){ //定义函数 行参1 数组型(其实相当于 int *num) 形参2 一级指针型
int i = N;
int *u; //指针定义时不初始化赋予其地址是绝对不行的
u = NULL; //这里给指针赋予初值NULL的被允许的,通常不知道给一个指针怎么初始化的可以用NULL
u = &i; //指针赋予真正有用的地址 也就是变量i在内存的地址
float b;
for(;i>=0;i--){ //当一个指针被赋予有意义的地址的时候 *p 就表示的是这个地址里面的内容,就是详
*m += num[*u]; //相当于一个改指针数据类型的一种变量,可以执行变量可以做的操作
}
*m = *m/2;
}
void main(){
int sccess[N] = {2,8};
float mean;
fen(sccess,&mean); //数组的名字就是表示保存数组数据的首地址。所以不用取地址了,
printf("Is = %f\n",mean);
}
以上代码主要重要内容就是
1、形参变量 int num[] 其实是可以表示为 int *num的,因为数组名其实就是指针
2、指针定义后必须要初始化,不能在一个程序里留下一个什么都没有指向的指针,必要可以用NULL(0)来作为初始化值
3、指针被初始化的时候只能赋值地址,不能赋值一个数值。不要把*号带着了。例如 *p = 10;就是错误的因为这时候指针不知道指向 哪里呀,直接赋值就是错误。还有一点就是加上* 之后比如*p,那么它表示的就是地址里的值,如果地址需要偏移,那么就要去掉 * 号再操作 比如 p++ p-- ,意思就是地址加1 地址减1
函数指针:
比如函数 int hello(int i,int a){}; 则可以定义函数指针 int (*name)(int ,int ); 如果这样 name = hello;那么这个函数指针 int (*name)(int ,int );就是指向了这个 hello 函数了。指针函数的作用呢其实就是为了使函数更加具有通用性,
那么具体有什么用或者有什么思想在里面?例如:
1 #include "stdio.h"
2 int Con(int *x,int *y);
3 void main(){
4 int i[2] = {6,8},b;
5 int (*f) (int*,int*)=Con;
6 // f = Con;
7 b = (*f)(&i[0],&i[1]);
8 printf("%d\n",b);
9 }
10
11 int Con(int *x,int *y){
12 return *x+*y;
13 }
![]()
这个例子看到了基本的使用方法,可能会说有点多此一举,但是下面的例子你就知道了;
1 #include "stdio.h"
2 int Con(int *x,int *y,int (*f)(int,int));
3 int add(int x,int y) ;
4 int sub(int x,int y) ;
5 int mu(int x,int y) ;
6 void main(){
7 int i[2] = {6,8},b;
8 b = Con(&i[1],&i[0],add);
9 printf("add :%d\n",b);
10 b = Con(&i[1],&i[0],sub);
11 printf("sub :%d\n",b);
12 b = Con(&i[1],&i[0],mu);
13 printf("mu :%d\n",b);
14 }
15
16 int Con(int *x,int *y,int (*f)(int,int)){
17 int i;
18 i = (*f)(*x,*y);
19 return i;
20 }
21 int add(int x,int y) {
22 return x+y;
23 }
24 int sub(int x,int y) {
25 return x-y;
26 }
27 int mu(int x,int y) {
28 return x*y;
29 }
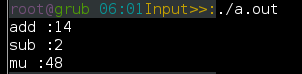
通过这个例子可以看到什么??哈哈哈,可以让函数名作为形参咯,酷毙了有吗。这样就可以让函数通用性更加强大了。
指针表示二维数组:
用指针表示二维数组有两种方法,一种是称为行指针方法。一种是称为列指针方法
#include "stdio.h"
3
5 void main () {
6
7 int arr[10][10];
8 int (*p)[10]; //行指针
9 int *u; //列指针
10 p=arr;
11 u = *arr;
12 arr[0][1] = 1;
13 arr[1][1] = 11;
14 arr[0][5] = 5;
15 arr[1][6] = 16;
// 分别用行指针和列指针方式输出
16 printf("connect is : %d %d \n",*(*(p+1)+6),*(u+0*10+1));
// a[1][6] a[0][1] 等价于
17 printf("connect is : %d %d \n",*(*(p+0)+1),*(u+1*10+1));
// a[0][1] a[1][1] 等价于
18 printf("connect is : %d %d \n",*(*(p+0)+5),*(u+1*10+6));
// a[0][5] a[1][6] 等价于
21 }

行指针方式解析:
定义 int (*p)[N] 这种方式是行指针方式,其含义是定义 int [N] 类型的指针。指针指向每一行的首地址。所以接下来 要给 指针 p 赋值,把数组 arr 也就是首行首地址的地址给指针 p。于是二维数组中的元素就可以按照 *((*p+i)+j) 这种方式读写数据。其中 i 表示行 j 表示列 ,
二维数组把其 arr[i][j] 看成这个数组是arr[i] 为名字的数组就好理解了,实际上用指针表示的时候就是这个意思,因为 这样 int (*p)[N] 定义的二维数组指针不就是意味着二维数组的 每一行的首地址(arr[n] ) 其实就是名字。而且我们知道数组名其实表示的就是地址,于是 *(*(p+i)+j) 就可以访问其中任意元素了。
其中 *(p+i) 这里的意思和以前不同 因为我们的指针类型是 int [N] 二维数组的指针型了,不再是一位数组 int 型指针了呀。在 *(*(p+i)+j) 里来说 它表示着行地址 ,比如 第一行地址 就用 *(p+0) 表示于是在此地址下 再加上列的地址,然后 *(*(p+i)+j) 就得出 i 行 j 列结果了。
把二维数组看做10层楼每层楼10户人家的话 ,那么其实行指针方式就是每一层楼有个管理。要通过每一层的管理才能去访问本层用户,*(p+i)就是相当于每一层的管理员 *((*p+i)+j) 就是通过管理员访问住户
列指针方式解析:
列指针的访问方式呢就是这一栋楼就只有一个管理员,通过他就可以访问任意住户了。是线性关系的。
其中定义 int 类型指针 u .然后 把 *a (也就是 数组首地址再进行取值的地址,那就是列地址)赋值给 u ,
那么此时 u 访问二维数组的时候是线性的了,把元素看成了一维化。直接以一维数组的方式访问,于是二维数组就可以按照 *(u+i*n+j))这种方式读写数据,同样表示为 i 行 j 列。
比如*(u+1*10+6)) ,其中为了方便看。10代表的就是这个数组每一行有几个元素,在程序中是确定的常量,1是行号,6表示这一行第几个元素。
1 #include "stdio.h"
2 void Han(int (*p)[10],int i,int j) ;
3 void LieOutput (int *p ,int i,int j);
4 void Output (int arr[][10] ,int i,int j);
5 void main(){
6 int arr[10][10];
7 Han(arr,10,10);
8 LieOutput(*arr,10,10);
9
10 Output(arr,10,10);
11 }
12
13 void Han(int (*p)[10],int i,int j) { //行指针赋值
14 int a,b;
15 for(a = 0;a<i;a++) {
16 for(b = 0;b<j;b++) {
17 *(*(p+a)+b) = a*b;
18 printf("%d ",*(*(p+a)+b));
19 }
20 printf("\n");
21 }
22 }
23 void LieOutput (int *p ,int i,int j) //列指针输出
24 {
25 int a,b;
26 for(a = 0;a<i;a++) {
27 for(b = 0;b<j;b++) {
28 // *(p+a*10+b) = a*b;
29 printf("%d ",*(p+a*10+b));
30 }
31 printf("\n");
32 }
33
34 }
35 void Output (int arr[][10] ,int i,int j){ //常规方式输出
36 int a,b;
37 for(a = 0;a<i;a++) {
38 for(b = 0;b<j;b++) {
39 printf("%d ",arr[a][b]);
40 }
41 printf("\n");
42 }
43 }
~ 
行指针和列指针说不上哪一种更好,看二维数据的读写方式和个人算法的需求,但是有一个问题 ,如果二维数组存放字符串那么空间会是固定的了,但是字符串是有长有短呀,有时候如果二维数组过于长,那么无型间浪费好多空间的,比如下面:
1 #include "stdio.h"
2 void HanOutput(char (*p)[10],int i,int j) ;
3 void main(){
4 char arr[3][10] = {"hello","Iam is","Linux C"}; //本来占用21(加上末尾'\0')个字节
5 printf("sizeof is : %d\n",sizeof(arr));
6 HanOutput(arr,3,10);
7 }
8
9 void HanOutput(char (*p)[10],int i,int j) {
10 int a,b;
11 for(a = 0;a<i;a++) {
12 for(b = 0;b<j;b++) {
13 printf("%c",*(*(p+a)+b));
14 }
15 printf("\n");
16 }
17 }
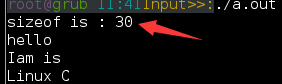 占用了30个固定的空间了,浪费9个字节。
占用了30个固定的空间了,浪费9个字节。
如果用指针的话,就可以达到节约空间的效果了,另一方面也方便很多,程序更为精妙,
1 #include "stdio.h"
2 void Output(char *p[]) ;
3 void main(){
4 char *arr[] = {"helloMyfirend","IamLinux C","how are you?"};
5 printf("sizeof is : %d\n",sizeof(arr));
6 Output(arr);
7 }
8
9 void Output(char *p[]) {
10 for(;*p!='\0';p++) {
11 printf("%s ",*p);
12 }
13 }
14
 可以看到占用空间就是指针的整体大小,
可以看到占用空间就是指针的整体大小,
总结一下就是 char *ch[] ={"str1"."str2","str3"}; char ch[][N] = {"str1"."str2","str3"};
这两种存储方式在内存中是截然不同的 ,第一种指针数组存放的是每一个字符串的首地址啦,通过地址来访问,同时很重要的是每一个字符串占用的空间都是不浪费的,有多长占用多长,
第二种的话要规定数组的长度 N ,.这个是固定死了,不管字符串多长多短 ,都会占用N空间,造成很大的浪费。
还有区别就是如果对其保存的字符串进行头字母排序这些操作的时候呀,第一种的效率非常之高,因为可以通过转换字符串的指针索引就可以实现排序了。就是改变一下指针指向就行。如果是第二种方法那就是会直接整一个字符串进行内存空间的移动排序,真正要耗费很多时间。可以这样说,第一种的指针数组改变的是指针指向的地址,而且普通二维数组则是改变所有数据内存物理位置。
下面一个简单的例子实现排序
1 #include "stdio.h"
2 #include "string.h"
3 void Output(char *p[]);
4 void Swp(char *p[]);
5
6 void main(){
7 char *arr[5] = {"B","G","E","A","F"};
8 printf("sizeof is : %d\n",sizeof(arr));
9 Swp(arr);
10 Output(arr);
11 }
12
13 void Output(char *p[]) {
14 for(;*p!='\0';p++) {
15 printf("%s ",*p);
16 }
17 }
18 void Swp(char *p[]) {
19 int i,j;
20 char* temp = NULL;
21 for (i = 0;i<5;i++) {
22 for (j = i+1;j<5;j++) {
23 if(strcmp(p[i],p[j])>0){
24 temp = p[j];
25 p[j] = p[i];
26 p[i] = temp;}
27 }
28 }
29 }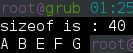 还说明了一点就是这种指针定义字符串在数量多而且长度很不一的情况下才能体现出它的领先优势。
还说明了一点就是这种指针定义字符串在数量多而且长度很不一的情况下才能体现出它的领先优势。
-
结构体
结构体可以其实抽象为一个变量,也是存储数据的东西,只是里面包含不同的类型的变量。注意使用的方法和掌握应用技巧就会有很大的好处。结构体在C语言里是非常重要的东西。看看是怎么定义的吧!!

这三种分别什么意思呢。这就要涉及结构体的声明了啊,我们要声明一个结构体要具有这种方式 :
struct [结构体标签] {结构体成员变量} ; 对应图1
struct {结构体成员变量} [初始名字] ; 对应图2
struct [结构体标签] {结构体成员变量} [初始名字]; 对应图5
如果要在其他地方定义这个结构体变量的话可以这样呀
struct [结构体标签] [结构体变量名];
所以结构体标签必须要有啊,不然无法扩展定义了。如果用第二种方式,只能用str这个结构体变量了。第一和第三种是差不多的,只是第三种是先声明一个str 的变量了。
这时候 value 与 str 就是同样的一种东西了。最后还有一种终极方法,都知道 typedef 这个关键字吧哈哈。所以
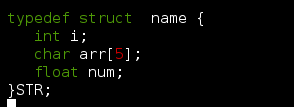
这时候 这个结构体 的别名就是 STR 啦 STR就是 struct name 的替代了。这样定义这个结构体变量的时候就可以 STR value 了 ;是不是又简便了呢。
结构体其实可以嵌套的哦,来试试。

可以看到嵌套的形式是这样的,这样的好处就是便于管理和封装。
下面看看怎么使用还有结构体初始化吧。
1
2 #include "stdio.h"
3 #include "string.h"
4
5
6 typedef struct chr {
7 int y;
8 int m;
9 int f;
10 }DATE;
11
12
13 typedef struct name {
14 int i;
15 char arr[5];
16 float num;
17 DATE date;
18 }STR;
19
20 void main () {
21
22 STR value2; //定义时没有初始化
23 STR value1 = {20,"abcde",4.33,{23,54,67}}; //定义时初始化
24 value2 = value1; //这个很重要。结构体的赋值也可以这样子,直接用 = 赋值的
25
// 下面的赋值方法只是针对没有初始化的value2的初始化赋值,这样子赋值的话 数组arr不能直接
// value2.arr = "abcde" ;这是非法的哦,只能value2.arr[i] = "";或者用字符串复制函数咯
//还有一点就是如果声明结构体时没有初始化的话,像value2这样的,之后是不能直接
// 以 value2 = {20,"abcde",4.33,{23,54,67}};这种形式赋值的 这样也是错误的 只能用以下的
26 value2.i = 20;
27 strcpy (value2.arr,"abcde");// strcpy (value2.arr,value1.arr);
28 value2.num = 4.33;
29 value2.date.y = 23;
30 value2.date.m = 54;
31 value2.date.f = 67;
32
33 }也可以声明结构体数组哦
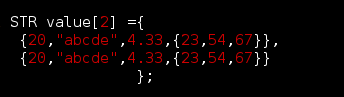
读取和赋值操作如果不是指针结构体的话用的 的 . 这个符号,看看效果
#include "stdio.h"
3 #include "string.h"
4
5
6 typedef struct chr {
7 int y;
8 int m;
9 int f;
10 }DATE;
11
12
13 typedef struct name {
14 int i;
15 char arr[5];
16 float num;
17 DATE date;
18 }STR;
19
20 void main () {
21
22 STR value[2] ={
23 {20,"abcde",4.33,{23,54,67}},
24 {20,"abcde",4.33,{23,54,67}}
25 };
26 STR value1 = {20,"abcde",4.33,{23,54,67}};
27 // 这里输出字符串 要规定一下长度 %.5s 不然会输出溢出
28 printf(" %d,%.5s,%f \n %d,%d,%d \n %d,%.5s,%f \n %d,%d,%d\n",
29 value[0].i, value[0].arr, value[0].num,
30 value[0].date.y, value[0].date.m, value[0].date.f,
31 value1.i, value1.arr, value1.num,
32 value1.date.y, value1.date.m, value1.date.f
33 );
34
35 }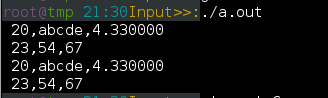 访问嵌套结构体必须要使用级联方式,
访问嵌套结构体必须要使用级联方式,
接下来到结构体指针了,其实和单纯的变量指针没啥区别, 但是指针结构体是访问要使用 -> 了哦
20 void main () {
21
22 STR str;
23
24 STR value[2] ={
25 {20,"abcde",4.33,{23,54,67}},
26 {2,"hello",3.33,{3,4,7}}
27 };
28 STR *p,*u;
29 u = &str; //由于str是普通变量,所以初始化和常规变量一样
30 p = value; // value是数组结构体,所以只需名字就是,就是首地址
/*
下面就是演示了指针结构体如何表示其元素了,用变量名 加 -> 这种方式最好,其实也可以
(*p). 这种方式的。还有就是 指针的地址加减意味着结构体数组的一个索引的偏移,和普通一维数组指针是差不多的
*/
33 printf(" %d,%.5s,%f \n %d,%d,%d \n",
34 p->i, p->arr, p->num,
35 p->date.y, p->date.m, p->date.f
36 ) ;
37 p++;
38 printf(" %d,%.5s,%f \n %d,%d,%d \n",
39 p->i, p->arr, p->num,
40 p->date.y, p->date.m, p->date.f
41 ) ;
42 p--;
43 printf(" %d,%.5s,%f \n %d,%d,%d \n",
44 (*p).i, (*p).arr, (*p).num,
45 (*p).date.y, (*p).date.m, (*p).date.f
46 );
47
48 u->i = 99; u->arr[0] = 'a'; u->num = 8.88;
49 u->date.y=100;
50 u->date.m=200;
51 u->date.f=300;
52 printf(" %d,%.5s,%f \n %d,%d,%d \n",
53 (*u).i, (*u).arr, (*u).num,
54 (*u).date.y, (*u).date.m, (*u).date.f
55 );
56 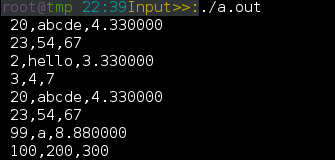
结构体和函数的运用其实与一维数组和函数的运用是一个道理,你可以只把名字穿传过去呀但是在里面操作其元素的话就不会影响到外面的结果哦,只限于函数内部操操作在栈中。所以如果要修改其值那就用指针就行,取地址传参到函数就可以了。
1 #include "stdio.h"
2 typedef struct chr {
3 int y;
4 int m;
5 int f;
6 }DATE;
7 typedef struct name {
8 int i;
9 char arr[5];
10 float num;
11 DATE date;
12 }STR;
13 void StructTest (STR *p,STR pyy);
14
15 void main (){
16
17 STR str;
18 StructTest(&str,str);
19 printf(" %d \n",str.i);
20 }
21
22 void StructTest (STR *p,STR pyy) {
23 p->i = 666;
24 pyy.i = 777;
25 printf(" %d \n",pyy.i);
26 printf(" %d \n",p->i);
27
28 }
可以看到输出结果是是可以知道,不加指针的形参接受传递给函数的结构体相当就是已经独立出去了,怎么操作都和原来的无关的,都不知道自己老子是谁了哈哈哈。当然再不考虑安全性情况下,用指针传递的效率是大大高于普通的效率的。
结构体在内存的的存储方方式根据不同的硬件机构也会有所不同,但是核心存储方式的 对齐方式 ,根据占用空间最大的那个变量来觉得其他元素的占用大小。计算结构体的占用空间大小只能用sizeof这个函数去计算,不能自己算哦。
比如:
3 #include "stdio.h"
4 #include "string.h"
5
6
7 typedef struct chr {
8 int y;
9 int m;
10 int f;
11 }DATE;
12
13
14 typedef struct name {
15 int i;
16 char arr[5];
17 float num;
18 DATE date;
19 }STR;
20
21 void main () {
22
23 STR str;
24 printf("%d\n",sizeof(str));
25 }
~ ![]()
输出28个字节大小,为什么呢 按道理 float 4个字节 int 4个字节 char 1个字节 ,那加起来不是 25个才对??
因为结构体要求对齐所以会以最大字节的变量的存储大小为整数存放。。 28是不是4的倍数哈哈,是的,那再测试一下了


可以看到输出的结果就是对齐方式咯。所以结构体的不好地方就是定义的变量差别较大就会有点浪费空间了,注意对齐就好。
共用体 :
union 共用体其实和结构体的定义访问赋值的操作都是一样的,但是不一样的就是保存方式不一样,变量是共用存储空间的,什么意思呢,其实就是说无聊共用体里面有多少个变量。最终它占据的存储空间其实是以最大的那个变量为主,看看效果

![]()
毫无疑问输出的是4,因为变量 int float 是最大的占用空间类型。那怎么理解里面的变量的共存内存空间的呢,其实共用体名如其人
就是共用这一份存储空间,但是同时具有多种类型,你想用作浮点型也行 想用字符型也可以,做int型也行。
但是共用体初始化只能初始化第一个变量,并且每一个变量都是瞬时保存的,意思就是其实里面囊括的char float int型的变量,但是你一个时间只能操作一种。默认之后一次操作的变量才是有效,前面的操作会被覆盖,因为共用空间嘛,
其实只要有一个例子就很好理解了,比如我要做一个能同时放 int 和 float两种数据类型的变量,怎么办,这个时候就可以用共用体来实现。
3 #include "stdio.h"
4 #include "string.h"
5
6
7
8 typedef union name {
9 int i;
10 float num;
11 }STR;
12
13 void main () {
14
15 STR str;
16 str.i = 1;
17 str.num = 1.66;
18 printf("%f %d\n",str.num,str.i);
19
20 str.i = 666;
21 printf("%f %d\n",str.num,str.i);
22 }
~ 输出:

可想而知,我们一个变量同时是int 和 float 数据类型,但是只能操作一种,而且会被覆盖的,没有被操作的那些变量里面的值将会是不可预知的哦;
-
结构体指针应用案例
利用指针来实现以下洗发牌的小程序,感受指针的魅力
纸牌52张,分四组 ,

其实只要分为 牌面和牌号 就行了。牌面 有 红桃 黑桃 梅花 方块 (Hearts spades diamonds clubs),牌号是 A 2 3 4 5 6 7 8 9 10 J Q K
#include "stdio.h"
2 #include "time.h"
3 #include "stdlib.h"
4 #include "string.h"
5 typedef struct stu { //定义纸牌的牌面和类别。
6 char face[8];
7 char num[2];
8 }STR;
9
10 void WriteBoard(STR p[],char *n[],char *f[]) { //初始化纸牌属性
11 int i;
12 for (i = 0;i<52;i++) {
13 strcpy(p[i].face,f[i/13]);
14 strcpy(p[i].num,n[i%13]);
15 }
16 }
17 void RandSend(int randnum[]) { // 洗牌,随机打乱顺序
18 int i,j,temp;
19 srand(time(NULL));
20 for(i =0;i<52;i++) {
21 j = rand()%52;
22 temp = randnum[i];
23 randnum[i] = randnum[j];
24 randnum[j] = temp;
25 }
26 }
27 void Initrand(int randnum[]) { // 牌重新按照顺序排序
28 int i;
29 for(i =0;i<52;i++) {
30 randnum[i] = i;
31 }
32 }
33 void OutputInit(STR p[],int randnum[]) { //发牌
34 int i,b = 0;;
35 for(i =0;i<52;i++) {
36 b++;
37 printf(" [%.8s] %.2s",p[randnum[i]].face,p[randnum[i]].num);
38 if(b==13){b = 0; printf("\n");}
39 }
40
41 }
void main () {
43 int i;
44 int randnum[52]; // 洗牌数组
45 STR board[52]; //存放牌的属性
46 char *numcon[] = {"A","2","3","4","5","6","7","8","9","10","J","Q","k"}; //牌面
47 char *facecon[] = {"Hearts","Spades","diamonds","clubs"}; //类型
48 WriteBoard(board,numcon,facecon); //装载牌
49 Initrand(randnum); //初始化装载洗牌数据
50 OutputInit(board,randnum); //发牌
51 Initrand(randnum); //初始化装载洗牌数据
52 RandSend(randnum); //洗牌
53 OutputInit(board,randnum); //发牌
54 }
这个代码最值得研究的就是洗牌这里,每次洗牌需要保证牌号都是不一样的,于是使用的srand(time(NILL));这个函数进行播随机种子,这样就保证rand函数在每次执行的时候都能产生不同的组合的数据。 如果不加你就会发现rand虽然产出随机数据,但是每一次的随机数都是同一种组合:

根据随机数,可以利用交换算法吧randnum数组里的有序排列变成无序排列,不管每一个随机数出现是不是和之前的意义都会改变rangnum[i]的值,因为进行了位置的交换而不是数据的交换。这样才是真正的高效率。
