窗口函数/解析函数/分析函数/OLAP函数
温馨提示:如果您发现本文哪里写的有问题或者有更好的写法请留言或私信我进行修改优化
★ 称呼的差异
- DB2中称这种函数为联机分析处理OLAP函数
- Oracle中称这种函数为解析函数/分析函数
- 但ISO SQL标准把它们称为窗口函数
★ 名词解释
- 解析函数基于一组行来计算合计值。它们与聚合函数的不同之处在于,它们为每个组返回多个行。行的组称为窗口,由analytic_clause定义。对于每一行,定义了行的滑动窗口。该窗口确定用于执行当前行计算的行范围。窗口大小可以基于实际的行数或逻辑间隔(例如时间)。
- 解析函数是查询中执行的最后一组操作,除了最后的ORDER BY子句。在处理分析函数之前,必须完成所有JOIN以及所有的WHERE,GROUP BY和HAVING子句。因此,分析功能只能出现在SELECT列表或ORDER BY子句中。
- 分析功能通常用于计算累积,移动,居中和报告汇总。
★ 关键词
- 开窗函数:over()
- 分组子句:partition by
- 排序子句:order by
- 窗口子句:rows | range | Specifying
- 范围表达:unbounded preceding | unbounded following
★ 例句
温馨提示:本文改编于[Daily_Footprint]:https://www.cnblogs.com/shenjie0622/p/10045696.html
select e.deptno,
e.empno,
e.ename,
e.sal,
--相当于使用sum和group by组合,不过下面的写法方便快捷
sum(e.sal) over() 公司总收入,
--按部门分组并求每个部门的收入之和(简写,但是和全称意思相同)
sum(e.sal) over(partition by e.deptno) 各部门收入1,
--按部门分组并求每个部门的收入之和(全称,但是和简写意思相同)
sum(e.sal) over(partition by e.deptno order by e.empno rows between unbounded preceding and unbounded following) 各部门收入2,
--按照员工编号(empno)的排序后的累计,如果该列难以理解可以在表e后加[order by 2]以便理解查看
sum(e.sal) over(order by e.empno) 全体员工收入累计,
--按部门(deptno)分组,同时按员工编号(empno)排序后在本部门内取收入累计,相当于前一列的升级版,如果该列难以理解可以在表e后加[order by 1,2]以便理解查看
sum(e.sal) over(partition by e.deptno order by e.empno) 部门员工收入累计
from scott.emp e;
|
|
DEPTNO |
EMPNO |
ENAME |
SAL |
公司总收入 |
各部门收入1 |
各部门收入2 |
全体员工收入累计 |
部门员工收入累计 |
| 1 |
10 |
7782 |
CLARK |
2450.00 |
29025 |
8750 |
8750 |
13175 |
2450 |
| 2 |
10 |
7839 |
KING |
5000.00 |
29025 |
8750 |
8750 |
21175 |
7450 |
| 3 |
10 |
7934 |
MILLER |
1300.00 |
29025 |
8750 |
8750 |
29025 |
8750 |
| 4 |
20 |
7369 |
SMITH |
800.00 |
29025 |
10875 |
10875 |
800 |
800 |
| 5 |
20 |
7566 |
JONES |
2975.00 |
29025 |
10875 |
10875 |
6625 |
3775 |
| 6 |
20 |
7788 |
SCOTT |
3000.00 |
29025 |
10875 |
10875 |
16175 |
6775 |
| 7 |
20 |
7876 |
ADAMS |
1100.00 |
29025 |
10875 |
10875 |
23775 |
7875 |
| 8 |
20 |
7902 |
FORD |
3000.00 |
29025 |
10875 |
10875 |
27725 |
10875 |
| 9 |
30 |
7499 |
ALLEN |
1600.00 |
29025 |
9400 |
9400 |
2400 |
1600 |
| 10 |
30 |
7521 |
WARD |
1250.00 |
29025 |
9400 |
9400 |
3650 |
2850 |
| 11 |
30 |
7654 |
MARTIN |
1250.00 |
29025 |
9400 |
9400 |
7875 |
4100 |
| 12 |
30 |
7698 |
BLAKE |
2850.00 |
29025 |
9400 |
9400 |
10725 |
6950 |
| 13 |
30 |
7844 |
TURNER |
1500.00 |
29025 |
9400 |
9400 |
22675 |
8450 |
| 14 |
30 |
7900 |
JAMES |
950.00 |
29025 |
9400 |
9400 |
24725 |
9400 |
★ 语法
analytic_function::=
![]()
analytic_clause::=

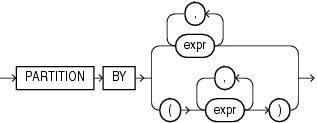
query_partition_clause::=
order_by_clause::=

windowing_clause ::=

★ 语法注解
- 名词注释
| 名词 |
释义 |
| unbounded |
无限的 |
| preceding |
之前的 |
| following |
之后的 |
| current row |
当前行 |
- 语句注释
rows|range between unbounded preceding and unbounded following表中的所有记录(第一条至最后一条记录)
rows|range between unbounded preceding and current row第一行至当前行的汇总
rows|range between current row and unbounded following当前行到最后一行的汇总
rows|range between 1 preceding and current row 前1行到当前行的汇总
rows|range between 1 preceding and 1 following 前1行到当前行的下1行的汇总
- rows
拿当前的行号(假设为3)为基础去制订范围(假设为3-1≤3≤3+2),然后拿制订的范围行所对应的字段值去匹配order by sal中,满足α≤sal≤β的sal值(α是行号为2的字段值,β是行号为5的字段值)(和range不同的是,rows是拿行号对应的字段数据去比较)
- range
拿当前的行号(假设为3)为基础去制订范围(假设为3-1≤3≤3+2),然后拿制订的范围行编号作为一个值去匹配order by sal中,满足2≤sal≤5的sal值(和rows不同的是,range是拿行号作为数值去比较)
- 案例(用来对比rows和range)
※ SQL语句
with t as
(select (case
when level in (1, 2) then
1
when level in (4, 5) then
6
else
level
end) sal
from dual
connect by level < 10)
select sal,
sum(sal) over(order by sal) default_sum,
sum(sal) over(order by sal range between unbounded preceding and current row) range_unbound_sum,
sum(sal) over(order by sal rows between unbounded preceding and current row) rows_unbound_sum,
sum(sal) over(order by sal range between 1 preceding and 2 following) range_sum,
sum(sal) over(order by sal rows between 1 preceding and 2 following) rows_sum
from t;
※ 下表为SQL的结果集:
|
|
SAL |
DEFAULT_SUM |
RANGE_UNBOUND_SUM |
ROWS_UNBOUND_SUM |
RANGE_SUM |
ROWS_SUM |
| 1 |
1 |
2 |
2 |
1 |
5 |
5 |
| 2 |
1 |
2 |
2 |
2 |
5 |
11 |
| 3 |
3 |
5 |
5 |
5 |
3 |
16 |
| 4 |
6 |
23 |
23 |
11 |
33 |
21 |
| 5 |
6 |
23 |
23 |
17 |
33 |
25 |
| 6 |
6 |
23 |
23 |
23 |
33 |
27 |
| 7 |
7 |
30 |
30 |
30 |
42 |
30 |
| 8 |
8 |
38 |
38 |
38 |
24 |
24 |
| 9 |
9 |
47 |
47 |
47 |
17 |
17 |
- value_expr(根据rows/range的不同value_expr可以是:常数/常量/表达式/时间间隔)
① 函数:NUMTOYMINTERVAL
※ 句法
![]()
※ 目的
NUMTOYMINTERVAL将数字转换n为INTERVAL YEAR TO MONTH文字。参数n可以是任何NUMBER值或可以隐式转换为NUMBER值的表达式。该参数interval_unit可以是CHAR,VARCHAR2,NCHAR,或NVARCHAR2数据类型。的值interval_unit指定单元的单位,n并且必须解析为以下字符串值之一:
' YEAR'
' MONTH'
interval_unit不区分大小写。括号内的前导值和尾随值将被忽略。默认情况下,返回的精度为9。
※ 例句
SELECT last_name, hire_date, salary,
SUM(salary) OVER (ORDER BY hire_date
RANGE NUMTOYMINTERVAL(1,'year') PRECEDING) AS t_sal
FROM employees
ORDER BY last_name, hire_date;
② 函数:NUMTODSINTERVAL
※ 句法
![]()
※ 目的
NUMTODSINTERVAL转换n为INTERVAL DAY TO SECOND文字。参数n可以是任何NUMBER值或可以隐式转换为NUMBER值的表达式。该参数interval_unit可以是CHAR,VARCHAR2,NCHAR,或NVARCHAR2数据类型。的值interval_unit指定单元的单位,n并且必须解析为以下字符串值之一:
' DAY'
' HOUR'
' MINUTE'
' SECOND'
interval_unit不区分大小写。括号内的前导值和尾随值将被忽略。默认情况下,返回的精度为9。
※ 例句
SELECT manager_id, last_name, hire_date,
COUNT(*) OVER (PARTITION BY manager_id ORDER BY hire_date
RANGE NUMTODSINTERVAL(100, 'day') PRECEDING) AS t_count
FROM employees
ORDER BY last_name, hire_date;
③ interval expression(区间表达式)
⑴ interval year to month 类型
※ 格式:
INTERVAL 'integer [- integer]' {YEAR | MONTH} [(precision)][TO {YEAR | MONTH}]
该数据类型常用来表示一段时间差, 注意时间差只精确到年和月. precision为年或月的精确域, 有效范围是0到9, 默认值为2
※ 例句A:
select INTERVAL '123-2' YEAR(3) TO MONTH from dual;
表示: 123年2个月, "YEAR(3)" 表示年的精度为3, 可见"123"刚好为3为有效数值, 如果该处YEAR(n), n<3就会出错, 注意默认是2
※ 例句B:
select INTERVAL '5-3' YEAR TO MONTH + INTERVAL '20' MONTH from dual;
表示: 5年3个月 + 20个月 = 6年11个月
⑵ inter day to second 类型
※ 格式:
INTERVAL '{ integer | integer time_expr | time_expr }'
{ { DAY | HOUR | MINUTE } [ ( leading_precision ) ]
| SECOND [ ( leading_precision [, fractional_seconds_precision ] ) ] }
[ TO { DAY | HOUR | MINUTE | SECOND [ (fractional_seconds_precision) ] } ]
leading_precision值的范围是0到9, 默认是2. time_expr的格式为:HH[:MI[:SS[.n]]] or MI[:SS[.n]] or SS[.n], n表示微秒.
范围值:
HOUR:0 to 23
MINUTE: 0 to 59
SECOND: 0 to 59.999999999
※ 例句A:
INTERVAL '400' DAY(3)
表示: 400天
※ 例句B:
INTERVAL '4 5:12:10.222' DAY TO SECOND(3)
表示: 4天5小时12分10.222秒
④ add_months(可行性待研究)
……(未完待续)
- Window子句定义
※ 当使用 WINDOW 子句语法时,以下限制将适用
- 如果指定 PARTITION BY 子句,则必须将其置于 WINDOW 子句内。
- 如果指定 ROWS 或 RANGE 子句,则必须将其置于引用函数的 OVER 子句中。
- 如果为窗口指定 ORDER BY 子句,可将该子句置于WINDOW 子句中,或者置于引用函数的OVER 子句中,但不能同时置于二者之中。
- WINDOW 子句必须位于 SELECT 语句的 ORDER BY 子句之前。
- 写法1
SELECT manager_id,
last_name,
hire_date,
COUNT(*) OVER(PARTITION BY manager_id ORDER BY hire_date RANGE NUMTODSINTERVAL(100, 'day') PRECEDING) AS t_count
FROM employees
ORDER BY last_name, hire_date;
- 写法2(将Window子句单独抽离出来,供各over子句调用)(该方法似乎不适应于Oracle,待研究)
SELECT SUM(s.sal) OVER(w ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS sum_qty,
AVG(s.sal) OVER(w ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS avg_qty
FROM scott.emp s
WHERE s.sal>800 WINDOW w AS(PARTITION BY s.deptno ORDER BY s.empno)
ORDER BY sal;
★ 各数据库对比
| 数据库 |
窗口函数 |
版本 |
| Oracle |
支持 |
≥8.1.6 |
| DB2 |
支持 |
≥(不知道,待研究) |
| PG |
支持 |
≥8.4 |
| MySQL |
支持 |
≥8.0 |
| SqlServer |
支持 |
≥2005 |
★ 优点
- 类似Group By的聚合
- 非顺序的访问数据
- 可以对于窗口函数使用分析函数、聚合函数和排名函数
- 组内排名问题(排名问题,各部门按业绩排名;topN问题)
- 同时具有分组和排序功能(先分组后排名)
- 简化了SQL代码(消除Join)
- 不减少原表行数
- 消除中间表
★ 知识点
- 当ORDER BY后面缺少窗口从句条件,窗口规范默认是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
- 当ORDER BY和窗口从句都缺失, 窗口规范默认是 ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
- OVER从句支持以下函数, 但是并不支持和窗口一起使用它们。
※ Ranking函数: Rank, NTile, DenseRank, CumeDist, PercentRank.
※ Lead 和 Lag 函数
- 窗口就是分析函数分析时要处理的数据范围
- 如果分析函数没有指定ORDER BY子句,也就不存在ROWS/RANGE窗口的计算;
- range是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内对应列都包含在内
- rows是物理窗口,即根据order by子句排序后,取的前N行及后N行的数据计算(与当前行的值无关,只与排序后的行号相关)
★ 常用函数
分析功能通常在数据仓库环境中使用。在下面的分析函数列表中,带星号(*)的函数允许使用完整语法,包括windowing_clause。
- AVG *
- CORR *
- COUNT *
- COVAR_POP *
- COVAR_SAMP *
- CUME_DIST
- DENSE_RANK
- FIRST
- FIRST_VALUE *
- LAG
- LAST
- LAST_VALUE *
- LEAD
- LISTAGG
- MAX *
- MEDIAN
- MIN *
- NTH_VALUE *
- NTILE
- PERCENT_RANK
- PERCENTILE_CONT
- PERCENTILE_DISC
- RANK
- RATIO_TO_REPORT
- REGR_ (Linear Regression) Functions *
- ROW_NUMBER
- STDDEV *
- STDDEV_POP *
- STDDEV_SAMP *
- SUM *
- VAR_POP *
- VAR_SAMP *
- VARIANCE *
★ 分析函数案例汇总(由于版权和篇幅原因,请访问原文)
https://blog.csdn.net/cc_0101/article/details/80884076
★ 特别感谢各位网友的支持,相关参考文章链接如下:
https://docs.oracle.com/cd/E11882_01/server.112/e41084/functions004.htm#SQLRF06174
https://www.cnblogs.com/shenjie0622/p/10045696.html
http://www.blogjava.net/pengpenglin/archive/2008/06/25/210536.html
https://blog.csdn.net/huozhicheng/article/details/5843782/
https://blog.csdn.net/haiross/article/details/15336313
https://blog.csdn.net/cc_0101/article/details/80884076
https://blog.csdn.net/richieruan/article/details/52712447?locationNum=6
https://blog.csdn.net/wangxw8746/article/details/40371227
https://blog.csdn.net/cc_0101/article/details/80884076
