Django:路由系统
路由系统理解
1、系统功能:根据用户访问的不同url,执行对应的视图函数
2、web服务器可以根据用户访问的url地址的不同,返回相应的html页面,而html的页面渲染由视图函数处理,这就需要有一个模块负责分析用户访问的url地址,并根据预先定义的映射规则,将请求分发到不同的视图函数中进一步处理,负责这个工作的模块就是web框架中的路由系统。路由系统的工作总结起来就是:制定路由规则,分析url,分发请求到响应视图函数中
3、为了给应用程序设计URL,开发人员需要开发一个Python模块,这个模块就是就是URL的配置信息,通常将这个配置模块叫做URLconf。这个模块是一个纯粹的Python脚本,它包含了URL表达式与Python方法(视图)之间的映射,这里所说的Python方法就是Django应用中的视图方法。(如前面那章中的根目录下的urls.py和各个app下的urls.py都是URLconf实例)
4、路由系统的路由功能基于路由表,路由表是预先定义好的url和视图函数的映射记录。换句话说,可以理解成将url和视图函数做了绑定,映射关系有点类似一个python字典
5、路由表的建立是控制层面,需要在实际业务启动前就准备完毕,即:先有路由,后有业务。一旦路由准备完毕,业务的转发将会完全遵从路由表的指导
6、URL配置(URLconf)的本质是:URL与该URL调用的视图函数之间的映射表。以这种方式告诉Django,对于这个URL调用这段代码,对于那个URL调用那段代码
例1:
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
path("login/",include("Login.urls")),#新增登录路由
]注:
1、在Django中采用的是分布式路由,即先在各个APP下定义各自的路由配置,然后再在根目录下的urls.py文件中统一处理各个app(应用程序)下的路由(urls.py)
2、上面例子中定义了两个url,分别是admin/和login/,其中admin/直接对应的是处理函数(视图,admin.site.urls),而login/对应的则是一个app下的url子配置文件,因此需要在其子配置中找其对应的视图
3、所有的url路径和对应的视图映射都是写在"urlpatterns"中的,只是说分为根目录下的根配置(urls.py)和各个应用程序app下的子配置(urls.py)
4、所有的映射不是随便写的,而是使用"path"函数或者"re_path"函数进行包装的

URLconf基本格式
urlpatterns = [
path(正则表达式, views视图函数,字典型参数,别名),
]
'''
参数说明:
一个正则表达式字符串或具体的url字符串
一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
可选的要传递给视图函数的默认参数(字典形式)
一个可选的name参数
'''Django处理HTTP请求的流程
当用户发起一个HTTP请求时,Django就会按照以下逻辑对请求进行处理:
1、确定URL根配置位置,通常URL根配置在ROOT_URLCONF中设置:URL的根配置在根目录下的setting.py文件中,由项目名.urls组成,即指向根目录下的urls.py文件。因此每次请求时都会根据该配置先确定URL根配置在哪里,然后去对应配置文件中找url配置信息
ROOT_URLCONF = 'Web.urls'2、加载配置信息,在配置信息中查找urlpatterns:即加载根目录下的urls.py文件中的URL配置
urlpatterns = [
path('admin/', admin.site.urls),
path("url路劲",对应的视图函数或应用程序下的urls.py文件),
]3、按顺序检索urlpatterns中的所有URL模式字符串,并定位在第一个与URL匹配的URL模式字符串:即由请求中的URL匹配到urlpattern中的URL,进而确认对应的视图函数或子urls文件
4、当检索到匹配的URL模式字符串后,调用对应的视图方法,并传递以下参数给视图方法
⑴一个HttpRequest对象实例
⑵如果匹配到的URL模式字符串不包含任何组,那么匹配的信息会作为位置参数传递给视图
⑶如果在URLconf中没有找到任何匹配的URL模式字符串,或者出现其他任何错误,Django将会调用一个处理错误信息的视图
动态生成URL
1、前面介绍的URL都是固定的,即一开始就是在URLconf中定义、配置好了的,用户只需要输入正确的URL就能访问到对应的页面,如果输入了错误的URL,就不会访问到页面了
2、但实际上,在网页应用中,很多情况下需要动态编写URL,而不是用户直接在浏览器中输入URL,例如网页超链接的URL需要在生成网页时固定好
3、有时候,url中包含了一些参数需要动态调整。比如简书某篇文章的详情页面的URL是:https://www.jianshu.com/p/0aa957b19adfd,另一篇文章的url又是:https://www.jianshu.com/p/e10773fb1ebf。这两个URL中实际上不同的就是后面那串数字(e10773fb1ebf),试想一下,如果每篇文章都用前面那种定义URL的方法去定义配置一个URL的话,那就会显得很繁琐且浪费资源,因此,就可以在定义、配置URL的时候将后面这串数字定义成一个可变的(就跟我们在定义函数时一样,使用形参来代替实参,不论实参怎么变,形参都是一个)。前民两个URL中最后那串数字,实际就是这篇文章的ID,那么简书的文章详情页面的URL就可以写成https://www.jianshu.com/p/<id>,其中id就是文章的id,即在发出请求时由客户端(HTML之类的)捕捉到这篇文档的ID,然后动态的生成这篇文章的URL,进而进行请求
4、在Django中要动态的生成URL,可以使用尖括号的形式来定义一个参数(也可以在url中定义多个变量参数)。通过URL中传递参数给视图函数
5、也就是在url中捕获参数:在url规则中使用<变量名>,可以捕获到url中的值传递给视图(视图函数参数列表需要有对应接收)。通过在URL中传递参数来确定具体访问的URL,此时的URL就是可变的
例2:单个变量
⑴在任意应用程序app下的views.py文件下编写对应的视图处理函数

⑵在对应应用程序app下的urls.py文件中编写对应的url与视图的映射关系

注:
1、这里我们直接在应用程序app下的url.py文件中定义了url路径,那么在根目录下的urls.py文件中就不需要定义具体的url路径了
2、这里定义子urls.py的方法与前面那章用的方法不一致(相反的):现在我也不清楚是在根目录下的urls.py文件中定义具体的url路径好,还是在应用程序app下的urls.py中定义具体的url目录好。反正现在能跑通就好,这个后面学习
⑶在根目录下的url.py中定义对应url与子urls.py的对应关系

⑷现在就可以启动项目来访问对应的页面了,访问book视图:在浏览器中输入http://127.0.0.1:8000/book

访问bookDeta视图:在浏览器中输入http://127.0.0.1:8000/book/detail/1

注:
1、这里我们使用的是手动传入book_id(在浏览器中手动输入)的方式。实际中应该是通过HTML等,让客户端自己去找这个id然后添加到url中,再进行请求
2、注意:视图函数中使用的变量名(book_id),一定要与URL中使用的变量名<book_id>一致才行,如果两个地方不一致的话,就会报错
3、从实际url中可以看出,使用的动态变量<book_id>其实也是URL中的一个路径部分
例3:多个变量
多个变量:就是在一个url中使用多个url路径变量
⑴编写视图函数

⑵编写url与视图的映射关系

⑶访问页面:输入http://127.0.0.1:8000/book/detail/1/2

注:
1、在例2中我们在根URLconf(根目录下的urls.py)中已经配置了'polls.urls'文件的映射了"path('',include('polls.urls'))"所以这次就不需要再配置了
2、从这里来看的话:在应用程序APP下配置具体的url映射,在根URLconf在配置应用程序('polls.urls')的映射,这种方式感觉要方便点。根目录下的urls.py文件配置的是应用程序app下的整个urls.py文件,所以整个子urls.py中的所有URL路径配置都包含在里面了
使用查询字符串的方式生成URL
1、在日常中可能遇到过某个URL中存在"?"(URL中的参数部分),这种就是使用查询字符串的方式来生成URL
2、例如在百度中搜索"Python"时发送的URL为:https://www.baidu.com/s?wd=python。其中"?wd=python"这种就是使用查询字符串的方式
例4:
⑴编写视图函数

⑵编写url与视图的映射关系

⑶访问页面:输入http://127.0.0.1:8000/book/author?id=3
因为这个例子中使用到的根目录urls.py的配置与前面的配置是一样的,所以这里就不需要配置了
注:
以查询字符串的方式生成URL:
⑴不需要再视图函数中传递参数(除了必须要的request参数)。只需要在视图函数中使用request.GET.get('参数名称')的方式来获取。当然这里获取也不是必须的,只是说在后续的代码中我们需要从URL中获取某些传入的参数来进行操作。比如这个例子中,我们就是获取URL中的id参数的值,来进行打印
⑵URL路径与视图函数的映射关系也是跟普通的URL一样,不需要使用尖括号等来传递参数什么的。这个例子中不需要将"?id=3"这部分写在URL匹配规则中
⑶这个例子中获取参数的方式是使用:request.GET.get('id')。其表示获取请求URL上名为'id'的值
⑷请求分为get请求和post请求。这里使用"?xx==yy"的请求是get请求。所以这里我们在获取请求上的id时,使用的是request.GET
⑸在查询字符串方式中:request.GET获取的数据是一种类似于字典的数据类型,因此还可以使用request.GET['id']
⑹注:视图函数中的参数request表示:request对象,其包含客户端或浏览器请求上的所有数据,其中就包括这些查询字符串
⑺上面例子中我们使用的是手动输入'?id=3'的方式进行访问的,实际中这部分应该是由客户端、浏览器等自动完成的
URL参数类型转换器
1、path函数的定义为:path(route,view,name=None,Kwargs=None)
⑴route参数:URL的匹配规则,这个参数中可以指定URL中需要传递的参数,也可以指定传递的参数的类型
⑵view参数:可以为一个视图函数或者是类视图.as_view()或者是django.urls.include()函数的返回值
⑶name参数:这个参数是给URL取个名字的,在项目比较大,URL比较多的时候用处很大
⑷Kwargs参数:有时候需要给视图函数传递一些额外 的参数,就可以通过Kwargs参数进行传递。这个参数接收一个字典,传递到视图函数中的时候,会作为一个关键字参数传递过去
2、上面介绍了URL中传参的情况,传递参数是通过"<参数名>"尖括号的方式来进行指定的。并且在传递参数的时候,可以指定这个参数的数据类型,比如文章的id都是int类型,那么可以这样写<int:id> ,以后匹配的时候,就只会匹配到id可以转换为int类型的url ,而不会匹配其他的url ,并且在视图函数中获取这个参数的时候,就已经被转换成一个int类型了。其中还有几种常用的类型:
| str | 匹配任意非空的字符串类型。但是不能匹配URL分隔符"/",这是默认的URL参数转换器(除了反斜杠之外的任何字符都能匹配) |
| int | 匹配任意的零或者正数的整形。到视图函数中就是一个int类型(匹配任意大于等于0的整数) |
| slug | 匹配任意slug字符串,slug字符串包含任意ASCII字符、数字、连字符"-"和下划线'_' |
| uuid | 匹配uuid字符串,字符串中的字母必须为小写字码。如xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12) |
| path | 匹配任意非空字符串,包括URL分隔符"/"。这允许匹配完整的URL而不是URL的一个片段 |
注:转换器是写在尖括号里面的
例5:
⑴编写视图函数

⑵编写url与视图的映射关系

⑶访问正确的URL:http://127.0.0.1:8000/book/publishe/2(数字可以是一位或多位)

⑷访问错误的URL:http://127.0.0.1:8000/book/publishe/d

注:
1、上面介绍的几种转换器是django中内置的转换器,可以在converters.py文件中查看其具体的规则:from django.urls import converters
2、转换器的匹配规则其实是通过正则表达式来匹配的,只要满足对应的正则表达式,就能正常匹配。如Str类型的转换器的匹配规则是:regex = '[^/]+'(匹配除了反斜杠之外的任何字符)
3、在Django中还可以自定义URL的转换器规则,只是这里先不介绍,后面再介绍
查询字符串参数补充
有时我们在访问实际网址的时候回遇到这种用"&"符号连接的多个参数:这种用"&"连接的都是URL中的参数部分
例:使用查询字符串方式


注:
1、这里也跟前面在介绍一般的查询字符串方式传参的一样:request.GET.get()只是用于获取URL中对应参数的值,用于获取a,b的值然后拼接再打印。对实际访问的URL没有影响的。如实际访问的URL是http://127.0.0.1:8000/zh/index/?a=1&b=3&c=3,也是可以正常访问的的,只是说不会获取C的值
2、即查询字符串的URL在匹配URLconf中的URL时,只会匹配URL部分,不会匹配参数部分。查询字符串中的参数部分对匹配URL没有任何影响,参数部分只是用于视图函数取值的
例:URL传参方式:
下面例子因为在URL中使用了类型转换器,所以在视图函数中就不需要再进行转换类型了


导入其他URLconf
1、对于现代Web应用程序来说,一个工程下通常包含多个应用程序(app),每个应用程序中又会包含很多URL,如果将这些URL都写在URLconf根模块中的话,那么URLconf将会变得非常臃肿,不利于维护。对于这种情况,常用的解决办法就是为每一个应用程序写一套独立的URLconf,而URLconf根模块可以通过使用include()方法将其他应用程序的URLconf引用进来
2、如果把所有的app的views中的视图豆瓣放在根目录下的urls.py文件中进行映射,肯定会让代码显得非常乱,因此django给我们提供一个方法,可以在app内部包含自己的url匹配规则,而在根目录下的urls.py中再统一包含着个app的urls。使用这个技术需要借助include()函数
3、其实上面几个例子中我们已经使用到了这种方法,只是说,这里在详细、规范的介绍一下。这种方法就是所谓的分布式路由
例6:
现在需要有一个名为"图书"的app:该app下的所有url都是以"book/"开始的,如book/s/2/2/2等(这种命名url的方式应该是最常见的,同一个app下的所有url都是同样的开头,后面再具体细分)
⑴编写根目录下的urls.py文件:URLconf根模块
①因为现在app"图书"下的所有URL都是以book/开头的,因此我们可以将"book/"这块放到根目录下的urls.py中:这就表示,只要请求的url是以'book/'开头的,就会进入到这个app下的子urls.py中去,不是以"book/"开头的 就不会进去匹配
②前面我们的例子中:我们是将完整的url都放到了子urls.py文件中,而根目录下的urls.py我们我们配置的是空字符串。这样的话表示的是请求的每个url都会到每个子urls.py中去匹配一次,这样就会浪费资源

⑵编写应用程序下的urls.py文件:URLconf子模块
注:因为在根URLconf下定义的是"book/",这里面已经有斜杠了,所以在子URLconf中的url就不需要以斜杠开头了。如果根URLconf下定义的是"book",那子URLconf中的url就需要以斜杠开头了

⑶访问url


注:上面例子中我们访问了两个不同的app下的url(login和book)
1、在访问book时:首先在URLconf根模块中匹配login时未匹配上,因此不会进入到期其对应的urls.py文件中。匹配到book时,匹配成功,然后就进入到其对应的urls.py文件中再继续进行匹配
2、在访问login时:跟上面步骤一样
3、在app的urls.py中,所有的url匹配也是要放在一个名为urlpatterns的变量中,否则找不到(与根URLconf一样)
4、url会根据URLconf根模块(根目录下的urls.py)和URLconf子模块(app下的urls.py)进行拼接,所以需要注意不要多加斜杠
URL名字与反转
1、为什么需要URL名字:前面在介绍path()函数的时候,提到path()函数有一个name的参数(默认值为None),这个name参数的值就是URL的名字
⑴给URL命名,可以方便的在模板或Python代码中使用URL
⑵因为URL是经常变化的,如果在代码中写死可能就需要经常改代码。给URL取个名字,以后使用URL的时候就使用它的名字进行反转就可以了,就不需要写死URL了
2、在定义url与视图的映射path()函数时,向path()函数传递一个name参数就可以执行url的名字了
例7:
⑴编写一个首页视图和一个登陆视图
①下面代码中定义了一个首页视图和登陆页面视图,在首页视图中:如果用户没有传入查询字符串参数"username"(处理函数没有获取到参数username),那么就会跳转到登陆页面,如果传入的username参数,那么正常进入首页页面
②下面代码中的redirect()函数表示:重定向。即没有获取到username参数时,就跳转到url为"/login/"的页面
③在重定向(跳转到指定url)时,如果使用这种写法的话,就是将URL写死了,如果后期需要修改的话,就需要修改涉及到的每个视图函数和每个主、子URLconf等
⑵访问页面:http://127.0.0.1:8000或http://127.0.0.1:8000/?username=s

例7_1:此时需要将为"login/"的URL修改为"sigin/"。那么在上面例子中我们需要修改的地方就有
⑴在上面那个例子中,如果需要修改视图函数中跳转的页面URL时,那么需要修改的就有:视图函数的中跳转URL和子URLconf中的url映射

⑵访问修改后的页面:http://127.0.0.1:8000(可以看到直接访问该url时,会自动跳转到)http://127.0.0.1:8000/signin/

例7_2:通过url的名字进行跳转
1、上面例子中介绍了通过具体的url来进行跳转,也介绍了在url变化后,该怎么去修改跳转的url。但是如修改的url数量太多了的话,使用上面这种方法就不是很方便了。因此就有了更加灵活的写法:通过URL的名字来进行跳转
2、下面例子中使用到了两个函数:
①redirect()函数:进行重定向、跳转的函数,其参数可以是具体的url也可以是url名字反转之后的返回值
②reverse()函数:用于反转URL名字的函数,也就是通过url名字来找到具体的URL
3、从下面例子中可以看出:URL的名字尽可能要唯一,不然在进行跳转时可能会出现不是预期的结果
4、通过url的名字来进行重定向、跳转时,直接使用的是URL的名字name参数的值:redirect(reverse("login"))
5、使用这种写法的话:如果需要修改url的话,就不需要去修改视图函数中的url了,只需要修改子URLconf中的url就可以了。因为视图函数中并没有用到具体的url,而用的是其URL的名字,只要保证其名字不变就可以了

URL的命名空间
作用:上面例子中介绍了使用URL名字来进行重定向、跳转。但是如果一个项目大起来以后,就有可能会出现不同的APP下面的URL名字重复了。这样如果在进行跳转的时候,就有可能会出现跳转错误的情况。为了解决这种情况,就需要用到URL的命名空间了
定义命名空间
1、URL命名空间用于将URL进行隔离。应用程序名就可以作为URL的命名空间。例如dajngo.contrib.admin的命名空间就是admin
2、由于Django的应用程序可以部署多次,所以应用程序的实例名也可以作为命名空间
3、使用"命名空间名:URL名"的方式调用URL。命名空间可以嵌套使用,如"命名空间名1:命名空间名2:URL名"
4、应用命名空间的变量叫做:app_name
例8:在应用程序app下的URLconf中使用app_name属性声明应用命名空间


注:
1、上面例子中在视图中通过"Login:login"的方式来调用命名空间,这表示:明确的告诉"login"这个URL名字是在Login这个应用命名空间下面的(应用命名空间Login表示Login这个应用程序)
2、从上面的例子可以看出:
⑴我们在应用程序下的urls.py文件中定义URL路由时,就要一开始定义好该应用程序的命名空间
⑵不管项目中会不会出现URL名字重复的情况,我们都要一开始就定义好每个应用程序的命名空间且在编写重定向调转时,也要一开始就使用"应用命名空间:URL名字"的方式
3、注意:这种在应用程序app下的urls.py中声明的命名空间叫做应用命名空间。除此之外还有个叫实例命名空间的(后面介绍)
例8_1:实例命名空间适用场景
应用程序的实例名:一般情况下一个应用程序app在根目录URLconf中只有一个URL映射。但是一个应用程序app在根目录URLconf中也可以有多个URL映射。这种一个映射关系就叫一个应用程序实例名
⑴下图中可以理解为,实际中有两个管理系统,只是他们的URL是不一样的csm1和csm2

⑵直接访问从csm1和csm2:http://127.0.0.1:8000/csm1或http://127.0.0.1:8000/csm2
如果此时直接分别访问的话,会发现在访问csm2时,最后重定向后会跳转到http://127.0.0.1:8000/csm1/login/。但这并不是我们预期的

例8_1_1:在根目录下的URLconf中定义实例命名空间
⑴在根目录下的URLconf中通过include()函数的可选参数namespace来指定不同实例名的实例命名空间

⑵在视图中调用实例命名空间:"实例命名空间名:URL名"

⑶分别访问csm1和csm2:http://127.0.0.1:8000/csm1或http://127.0.0.1:8000/csm2,可以发现这次的访问是分开的

注:
1、上面分别介绍了应用命名空间和实例命名空间的作用与用法,两个命名空间在作用和使用上都是用区别的
⑴应用命名空间:在应用程序app下的urls.py中通过app_name变量进行声明,在视图函数中通过"应用命名空间名:URL名"进行调用。其作用是为了解决不同应用程序下有相同的URL名(确定该URL名是属于哪个应用程序的)
⑵实例命名空间:在根目录下的urls.py(主URLconf)中通过include()函数的可选参数namespace值进行声明,在视图函数中通过"实例命名空间名:URL名"进行调用。其作用是为了解决同一个应用程序APP有多个实例名(多个不同的URL映射到同一个应用程序app中,确定该URL属于哪个实例名)
2、一个app可以创建多个实例,可以使用多个URL映射到同一个app。所以这就会产生一个问题:在做反转的时候,如果使用应用命名空间,那么就会发生混淆。为了避免这个问题,我们可以使用实例命名空间。因此在做反转的时候,就可以根据实例命名空间来执行具体的URL了
URL反转:reverse()函数补充
1、前面我们提到的都是通过URL来访问视图函数。有时候我们知道这个视图函数(URL名字),但是想反转回它的URL(比如跳转、重定向等),这时候就可以通过reverse()函数来实现:reverse("list"),通过URL名字为"list",找到其对应的URL
2、如果有应用命名空间或者实例命名空间,那么应该在进行反转的时候加上其命名空间。如:reverse("book:list")
3、如果这个URL中需要传递参数,那么可以通过Kwargs来传递参数,如:reverse("book:list",Kwargs=("book_id"=1))
4、因为Django中的reverse()函数在进行反转时,不能区分GET请求和POST请求,因此在进行反转的时候不能添加查询字符串的参数。如果想要添加查询字符串的参数,只能手动添加(进行拼接)。如:login_url=reverse('login')+'?next=/'
例:跳转的页面URL中不需要传入参数
下面代码表示:在访问首页时,如果没有传入username参数,则跳转到登录页面:此时登录页面是不需要参数的

例_1:跳转的页面URL中需要传入参数

例_2:使用参训字符串方式跳转
编辑视图和URL


注:在视图中进行URL跳转时有几点需要注意
1、确定跳转后的URL的名字:list
2、为了不把代码写死,可以使用reverse()函数来确定需要跳转到的URL:reverse("list")
3、为了避免多个应用程序中存在相同的URL名或存在多个实例名时,可以使用应用命名空间或实例空间对应跳转的URL名进行区分:reverse("book:list")
4、确定跳转后的URL中是否需要参入参数
⑴如果不需要传入参数,则可以直接使用redirect(url)进行跳转
⑵如果需要传入参数,且传入的参数是通过URL直接传入,则可以使用reverse()函数的Kwargs参数传入默认的参数名和值:reverse("book:list",Kwargs=("book_id"=1))
⑶如果需要传入参数,且传入的参数以通过查询字符串的方式传入,则可以通过拼接URL的方式传入默认的参数名和值:login_url=reverse('login')+'?next=/'
5、注意:前面4个步骤其实都还不算跳转,只是在进行URL反转(确定跳转后的URL),再确定好跳转的URL后,就可以直接使用redirect(url)进行跳转
使用正则表达式:re_path()函数
1、前面我们在定义URL时URL都是具体的字符,即在进行请求时,请求的URL在匹配时必须要与URL定义时一模一样。另外就是通过URL传参时用到了类型转换器(类型转换器用到的是正则表达式),可以对参数值或类型进行一些限制
2、在定义URL时可以使用正则表达式来匹配URL,此时就需要使用到re_path()函数,而不是path()函数
⑴path()函数:用来将一个具体的URL(明确的URL)来与视图进行映射
⑵re_path()函数:也是用来将URL于视图进行映射。只是说其功能比path()函数更加多,即使用正则表达式来表示同一类型的URL,这时候的URL就不是具体的一个了,而是一系列
⑶使用re_path()函数定义URL时,可以直接使用对应的正则表达式来代替具体的URL:如,re_path(r'^$',views.article),
⑷re_path()函数中的正则表达式也支持对分组进行命名(获取URL中的参数),语法格式为:(?P<变量名>pattern),如re_path(r'^list/cus/(?P<year>\d{4})/$',views.article_list_cus)。另,URL中的参数名也必须要与视图函数中的参数名一致
例9:
⑴定义视图

⑵定义应用程序中的URLconf
①在re_path()函数中捕获URL中的变量时,语法意思为:将需要捕获的参数和URL的正则表达式整个用圆括号包起来。用尖括号将参数名括起来后在尖括号前加上问号和大写的P,后接URL的正则表达式
②自己在写的时候发现,如果需要在URL中捕获参数时,正则表达式中就不能含有圆括号了,不然会找不到URL,这里感觉应该是圆括号重复了,不能正常识别,所以这个例子中使用的是{}
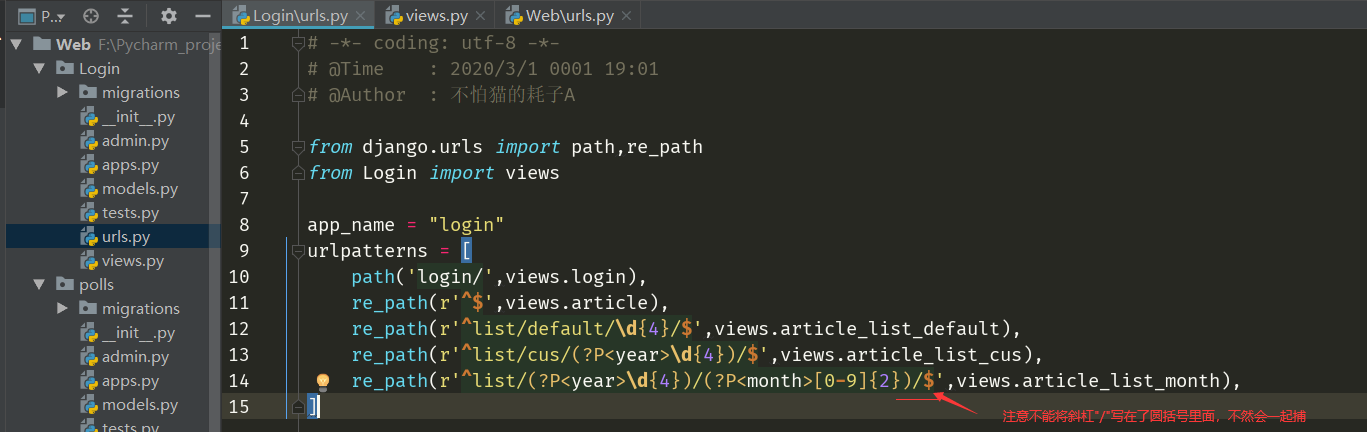
⑶定义根URLconf
⑷访问:必须符合URL中的正则表达式,才能正常访问





注:
前面在学习动态参数(类型转换器)时,也遇到了正则表达式:给我的感觉就是
1、re_path()函数的URL和类型转换器的URL:都是匹配某一系列的URL而不是只能匹配某一个具体的URL
2、re_path()函数的URL能更进一步的限制URL的范围,使用范围相对于类型转换器的URL更小。类型转换器可以达到部分re_path()函数的URL的功能
3、由下面的例子就可以看出:使用int内置转换器的话,只能限制是否为数字,不能限制其长度(因为int转换器内部使用的也是正则表达式,其内部的正则表达式只限制了类型未限制长度)。而使用re_path()函数的URL可以直接通过正则表达式来更进一步的限制URL(当然我们还可以自定义类型转换器)
例9_1:



注:
1、re_path()函数与pat()函数的作用是一样的,只不过re_path是在写URL的时候可以使用正则表达式,功能更加强大:匹配一系列的URL而不是某一个具体的URL
2、写正则表达式时都推荐使用原生字符串,也就是以"r"开头的字符串
3、在正则表达式中定义变量,需要使用圆括号括起来。这个参数是有名字的话,需要使用?P<参数名字>。然后后面添加正则表达式的规则
4、如果不是特别要求。直接使用path()函数来定义URL就够了,除非URL中确实需要使用正则表达式来解决时才使用re_path():
⑴一方面是因为正则表达式比较不容易理解
⑵另一方面就是使用正则表达式定义的URL是适用于某一系列的URL,因此首先就得确认这一系列的URL是否都可以使用该URL对应的视图,如果某个URL符合正则表达式,但是不符合其对应的视图的话,就尴尬了
自定义URL参数类型转换器
对于更加复杂的URL场景,开发人员可以自定义参数类型转换器,自定义参数类型转换器包括以下几个部分:
1、一个regex属性,属性值为正则表达式
2、一个to_python(self,value)方法,该方法用于将匹配的URL参数转换为指定类型,当类型转换失败后抛出ValueErroe异常
3、一个to_url(self,value)方法,该方法用于将Python类型转换为类型转换器字符串
4、将定义好的转换器注册到Django中
需求:
实现一个获取文章列表的demo,用户可以根据"/articles/文章分类/"的方式来获取文章,其中文章分类采用的是"分类1+分类2+分类3...."的方式拼接的,并且如果只有一个分类,那么不需要加号,实例如下:
1、获取python分类下的文章:/articles/python/
2、获取python和django分类下的文章:/articles/python+django/
3、获取python、django和flask分类下的文章:/articles/python+django+flask/
以此类推注:根据上面我们的需求可以看出,这个需求中的URL肯定不能通过path()函数来实现,因为path()函数定义的URL只能匹配某一个具体的URL。但可以通过re_path()函数来实现,re_path()函数定义的URL可以通过正则表达式来匹配某一系列的URL
例10:通过正则表达式来实现

注:这个例子中不管是python还是python+django...都是一个整体,都是属于categories变量的,它们是在一个圆括号里面的

4、在介绍转换器之前,需要进一步介绍下转换器的作用:前面只是说可以限制URL中传递参数的类型,其实其还有其他作用。如下图为内置的类型转换器Int,其主要也是也由三部分组成的
⑴regex变量:正则表达式,表示URL的匹配规则,用来匹配URL的
⑵to_python方法:在将参数传递给视图函数之前,将参数转为对应的指定类型,如这里是int类型,就表示在传递给视图函数之前将其转为int类型,如果转换失败,就抛出异常
⑶to_url方法:将Python数据类型转换为一段url的方法

to_python方法:
1、从下面的图片中可以看出,to_python方法的作用是:在将参数传递给视图函数之前,将参数转为对应的指定类型,现将参数传递给to_python()方法,再将转换后的参数传递给视图
2、因为URL中传递的参数类型默认是字符串型,可能我们在视图中需要的参数类型是整形,因此可以使用转换器进行转换,同时也对URL进行了限制(不仅可以限制URL的匹配规则也可以对URL参数进行转型)(当然也可以不使用转换器,在视图函数中进行转换也可以)

to_url方法:
1、从下面图片中可以看出,to_url方法的作用是:在使用reverse()函数将视图反转为URL时(根据URL名来反转为URL),将Python类型的参数转为url参数
2、to_url方法在进行反转时:会先将参数的值(例子中的article_id)传递给to_url方法进行转换,然后再将转换后的参数值传递给reverse()方法(如果例子中传递的是一个具体的整形,如1的话,就会返回字符串型的1)
3、可以看出:to_python方法和to_url方法的作用是相反的

需求:
1、在"文章分类"参数传递到视图函数之前,把这些分类分类储存到列表中。如参数是"python+django",那么传到视图函数的时候就要变成["python","django"]
2、以后在使用reverse()函数进行反转时,限制传递的"文章分类"的参数应该是一个列表,并且要将这个列表变成"python+django"的形式
例11:
1、编写自定义转换器代码
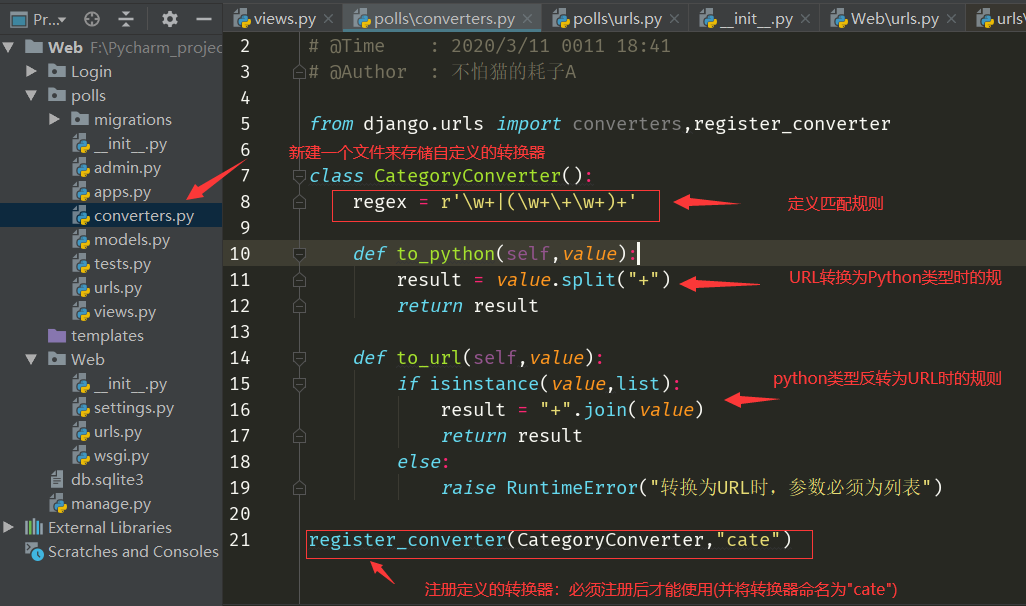
2、注册自定义转换器

3、编辑视图

4、访问:http://127.0.0.1:8000/article/list/python+django+flask/

5、URL反转

注:从上面的例子中可以看出
1、URL转换器和正则表达式的URL的作用其实是差不多:都是匹配一系列的URL。只是URL转换器还有其他一些作用
⑴to_python()方法:将URL中的值转换一下(转换后的类型由代码确定),然后再将转换后的值专递给视图函数
⑵to_url()方法:在做URL反转的时候,将传进来的参数转换后拼接成一个正确的URL,拼接后的格式也是由转换器中的代码确定
2、感觉正则表达式的URL和自定义的URL转换器,两者来说是差不多的:转换器的转换功能感觉单独的在视图函数中也可以进行转换,只是说写成一个转换器方便反复调用
3、定义一个URL时,可以考虑下其需不需要反转(特别是需要使用正则表达式来定义时)、视图函数中需不需要用到这个URL中的参数、这个URL后面会不会进行反转之类的。如果有,那就可以考虑为这个URL编写一个转换器
URL映射时指定默认参数
示例:
1、有时我们在访问一个网站的首页时,其URL为:http://www.qiushidabaike.com/hot。然后我们再访问这个网页的第二页(同一个页面下的第二页)时,其URL变为了:http://www.qiushidabaike.com/hot/page/2
2、这个例子中,第二次访问的URL比第一次URL中多了一个"page/"的参数,这个参数时我们在访问时没有传入的(参数2是第二页的值),这种场景下,"page/"这个参数就是映射时自动添加的默认参数
例12:
1、编辑视图:定义视图函数时设置默认参数(page=0)

2、访问:http://127.0.0.1:8000/article/或http://127.0.0.1:8000/article/page/3/


3、另外一种传递方式

注:
1、上面例子中主要的就是:需要注意的是由两个URL来对应一个视图(考虑URL的两种情况:带参数和不带参数)
2、另外:include()函数中也可以传递默认参数,include()函数中的默认参数将会被传递给每一个被引用的URL
3、URL中传递的参数可以和字符串组合:path('page/index_<int:page>/',views.books)。http://127.0.0.1:8000/article/page/index_3/。相当于就是捕获这个page参数后再与"/index_"进行拼接
