User-Agent 反爬虫绕过实战
User-Agent爬虫指的是服务器通过校验请求头中的User-Agent值来区分正常用户和爬虫程序的手段,这是一种较为初级的反爬虫手段。
"""
User-Agent 反爬虫绕过实战
实例1.校园新闻网列表页User-Agent反爬虫
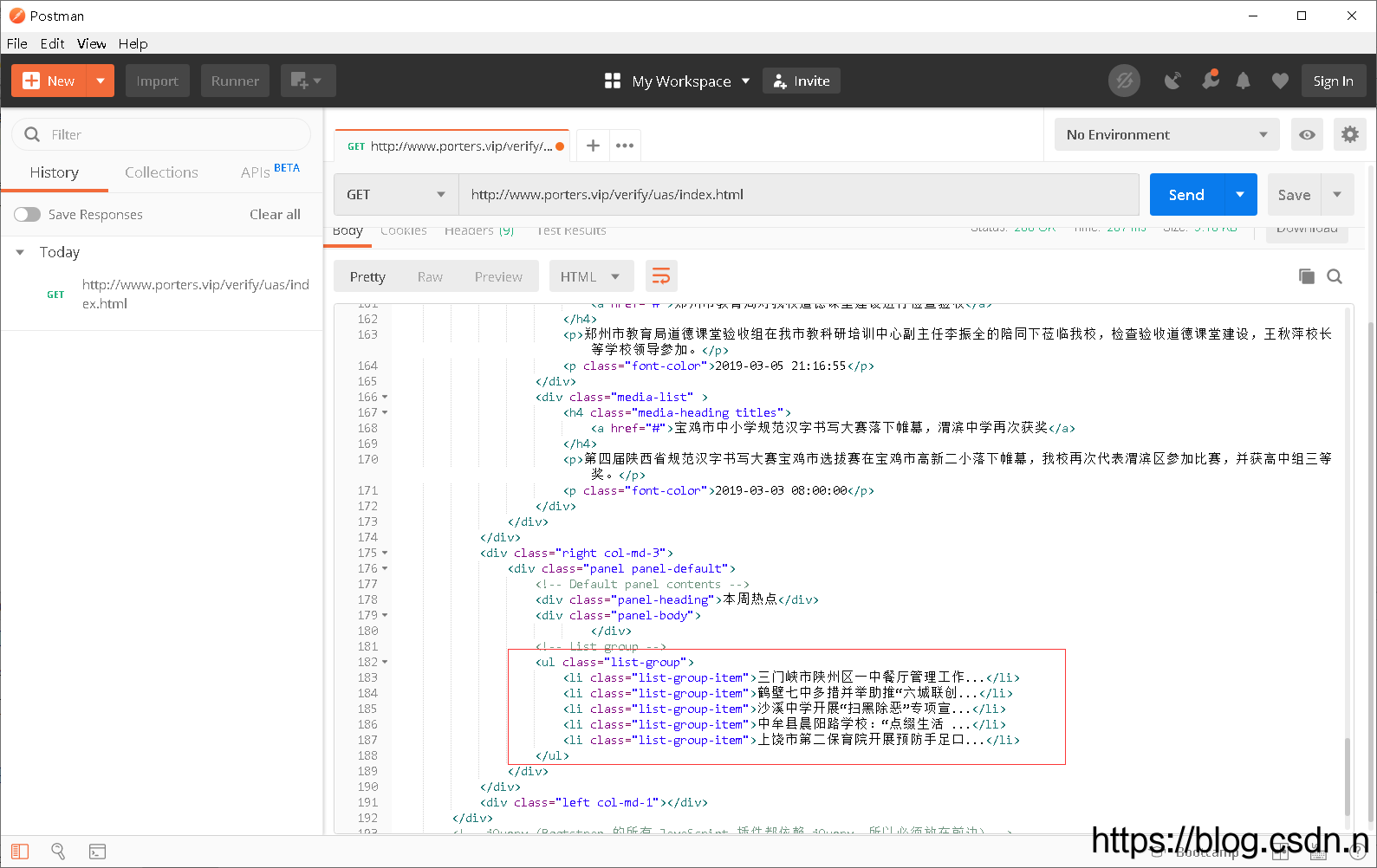
任务:爬取校园新闻网站页面右侧“本周热点”列表中的新闻标题
URL:http://www.porters.vip/verify/uas/index.html
"""
import requests
from parsel import Selector
url = 'http://www.porters.vip/verify/uas/index.html'
#向目标网站发起请求
resp = requests.get(url=url)
#打印输出状态码
print(resp.status_code)
#如果本次请求的状态码为200,则继续,否则提示失败
if resp.status_code == 200:
sel = Selector(resp.text)
#根据HTML标签和属性从响应正文中提取新闻标题
res = sel.css('.list-group-item::text').extract()
print(res)
else:
print('This request is Fial !')
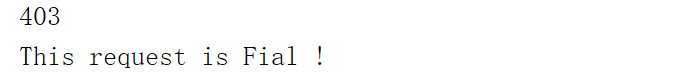
请求并没有成功,但是浏览器可以正常打开,这是为什么呢?难道是网站出了什么问题,我们可以用Postman试一试,Postman请求结果如下