在讲Xpath语法之前,首先我们需要了解一下Lxml库,要不然就算我们知道语法了,没有库的支持一切都是白搭,废话不多说,直接进入主题。
1、Lxml库
-
Lxml库的基本概念:
Lxml是Python中的一个解析库,支持Xpath语法解析方式,可以用来解析Xml结构,由于Html结构和Xml结构大致相似都是树形结构,所以Lxml也可以解析Html。 -
Lxml库的常见模块:Etree
我先来谈谈我对这个库的认识,Etree库的作用是对爬取出来的Html页面进行初始化操作,下面简单列举一下Etree模块的用法:1、
文本转换成HTML对象#HTML方法 html = etree.HTML(text)2、
将对象转成html文本 html = etree.HTML(text) result = etree.tostring(html)3、
解析页面并返还Html对象 html = etree.parse('text.html')
当然这个模块下想必不止这一些方法,Lxml库下也不止着一些模块,这边由于本人能力有限不能一一向大家介绍清楚,感兴趣的可以自己深入了解一下哈哈哈,这边草率地介绍一下爬虫解析页面时常用的三种方法。
-
Lxml安装:
- 命令行安装win+r,输入Cmd,进入终端模式(配好Python的环境变量)

2.在开发工具里面安装库包,这里作者用的时Pycharm,不过Pycharm安装库包的尿性大伙应该都清楚^ ^
- 命令行安装win+r,输入Cmd,进入终端模式(配好Python的环境变量)
输入Lxml,回车,不过作者这边死活加载不出来,见谅。
以上是作者对lxml的认识,如果有哪里没说完整、说错了的,发评论吐槽一下哈哈哈,人不挨打,长大不了,此外,作者了解了有关这方面的新知识,也会第一时间地更新博客,
1、Xpath篇
-
Xpath的基本概念:
通过路径表达式在XML、HTML文档里面寻找节点,进行导航 -
Xpath内部的基本函数:
XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。 -
Xpath是W3C标准:
XPath 于 1999 年 11 月 16 日 成为 W3C 标准。
XPath 被设计为供 XSLT、XPointer 以及其他 XML 解析软件使用。 -
Xpath节点:
类似于XML,整个HTML是被当做节点树对待的,
分为7类节点:元素,属性,文本,命名空间,处理指令,注释,根节点(文档节点)。
其实把它理解成网页Html的结构,比如《div></div》(makedown编辑器不支持<>符号)这种,无非是中间的英文单词换一个,有没有加一个class罢了,到时候直接F12 copy Xpath就好没必要想这么复杂。
5. Xpath节点之间的关系:
一、父关系
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
这里book就是titile、author、year、price的父级
二、子关系
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
继续套用上面的代码,titile、author、year、price就是book的子级
三、同胞
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
这里title、author、year、price就是四胞胎
四、先辈
先辈指的是子级的父或者子级的父的父
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
这里title、author、year、price四个的先辈分别指的是book和bookstore
五、后代
后代和先辈的意思正好反着来,也就是子代以及子子代
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
这里book、title、author、year、price就是bookstore的后代
现在简单梳理一下总共五种关系分别是:子代、父代、同胞、后代、先辈
- 选取节点:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 / 匹配某一个节点 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点。 |
| … | 选取当前节点的父节点。 |
| @ | 选取属性 |
- 谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
| 路径表达式 | 描述 |
|---|---|
| /a/b[1] | 选取属于a子元素的第一个b元素。 |
| /a/b[last()] | 选取属于a子元素的第一个b元素。 |
| /a/b[last()-1] | 选取属于a子元素的第二个b元素。 |
| /a/b[position() < 3] | 选取最前面的两个属于 a 元素的子元素的 b 元素。 |
| /a/b[@lang=‘tom’] | 选取属于a子元素属性为lang且值为tom的b元素。 |
| /a/b[price>35.00] | 选取属于a子元素中的b元素,且price属性大于35。 |
- 通配符
| 通配符 | 描述 |
|---|---|
| * | 所有元素节点 |
| @* | 所有带属性的节点 |
| node() | 所有节点 |
9.若干个路径同时匹配
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
将自己copy好的两个路径中间用 | 符号隔开就好
10.xpath在网页中路径的拷贝
一、随便打开一个网站,这里我选用的是Chrome浏览器,不同浏览器的检查可能会不一样。
二、F12打开终端
三、选择光标选择自己需要拷贝Xpath代码的位置,实时定位
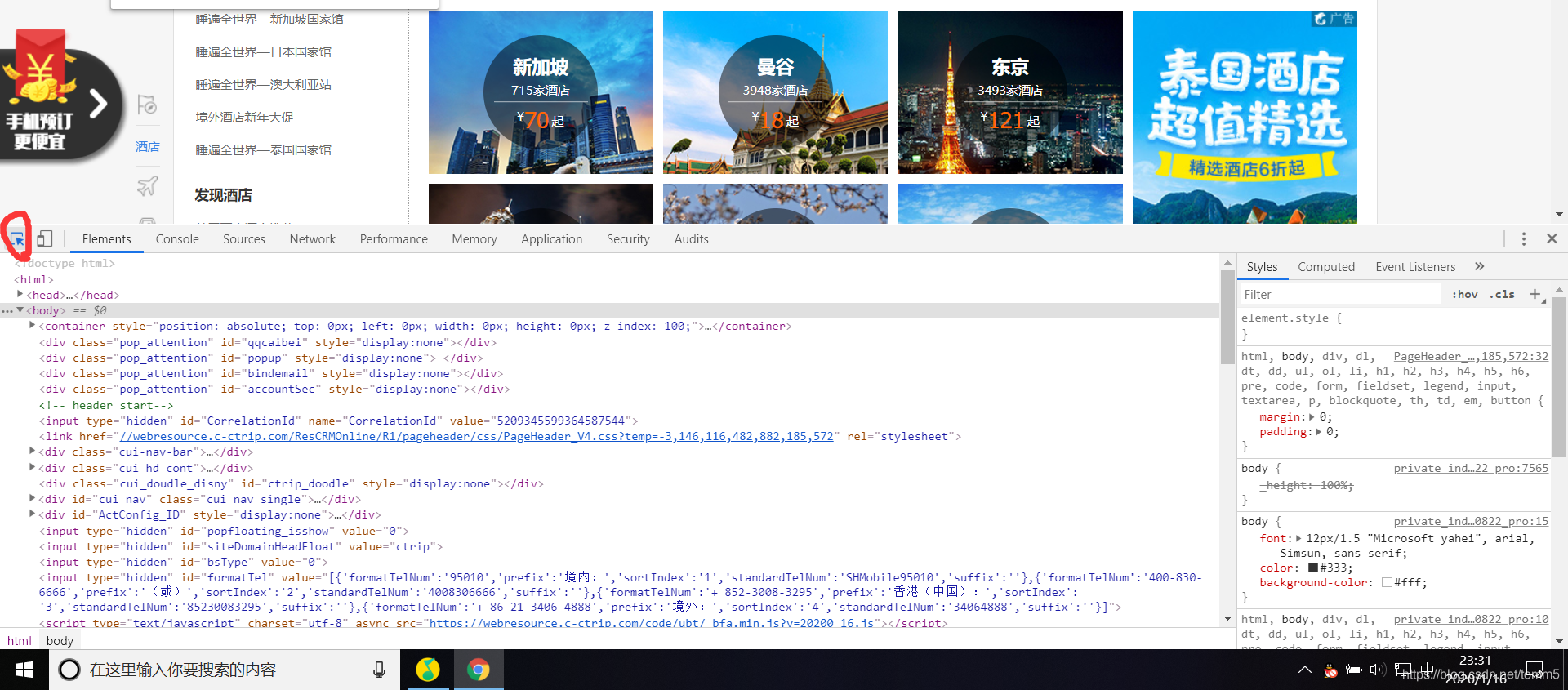
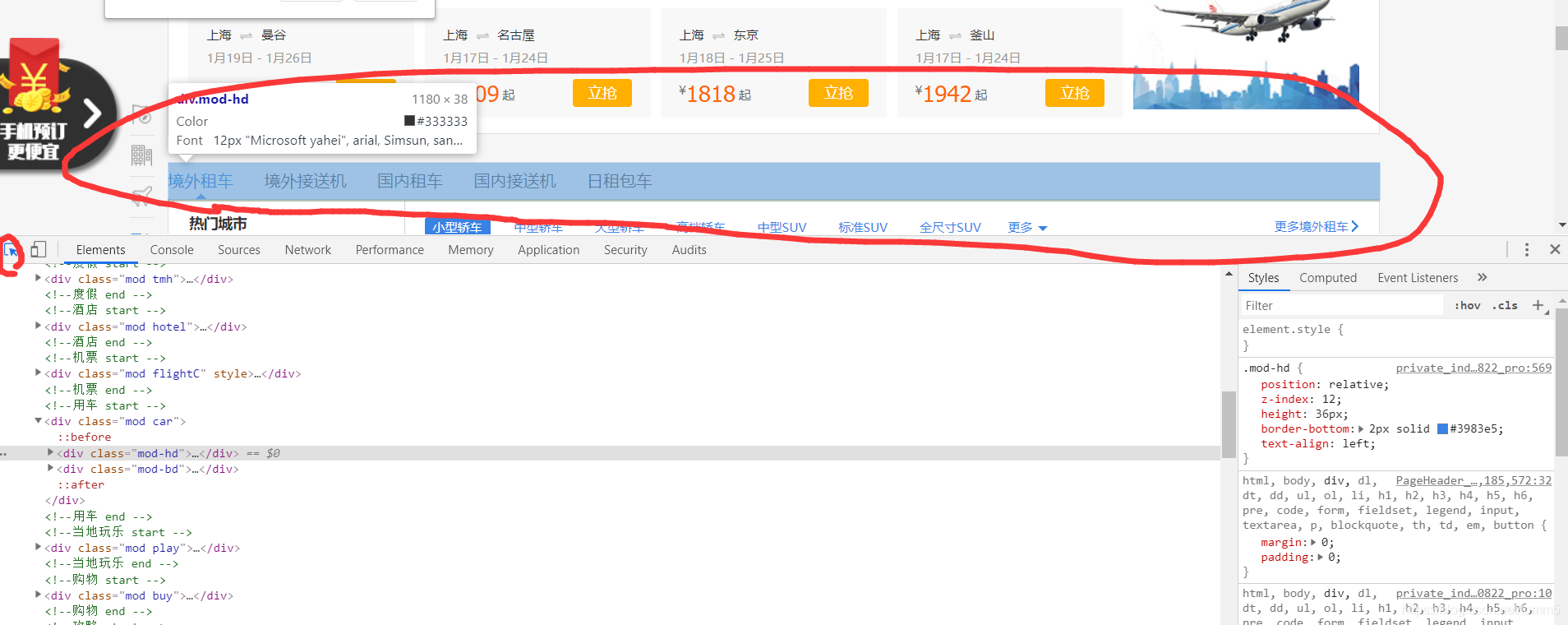
例如我移到到这,检查器就会自动追踪Html代码的位置
右键代码,在这里会有很多可以转换的格式,这里我们选择的是Xpath
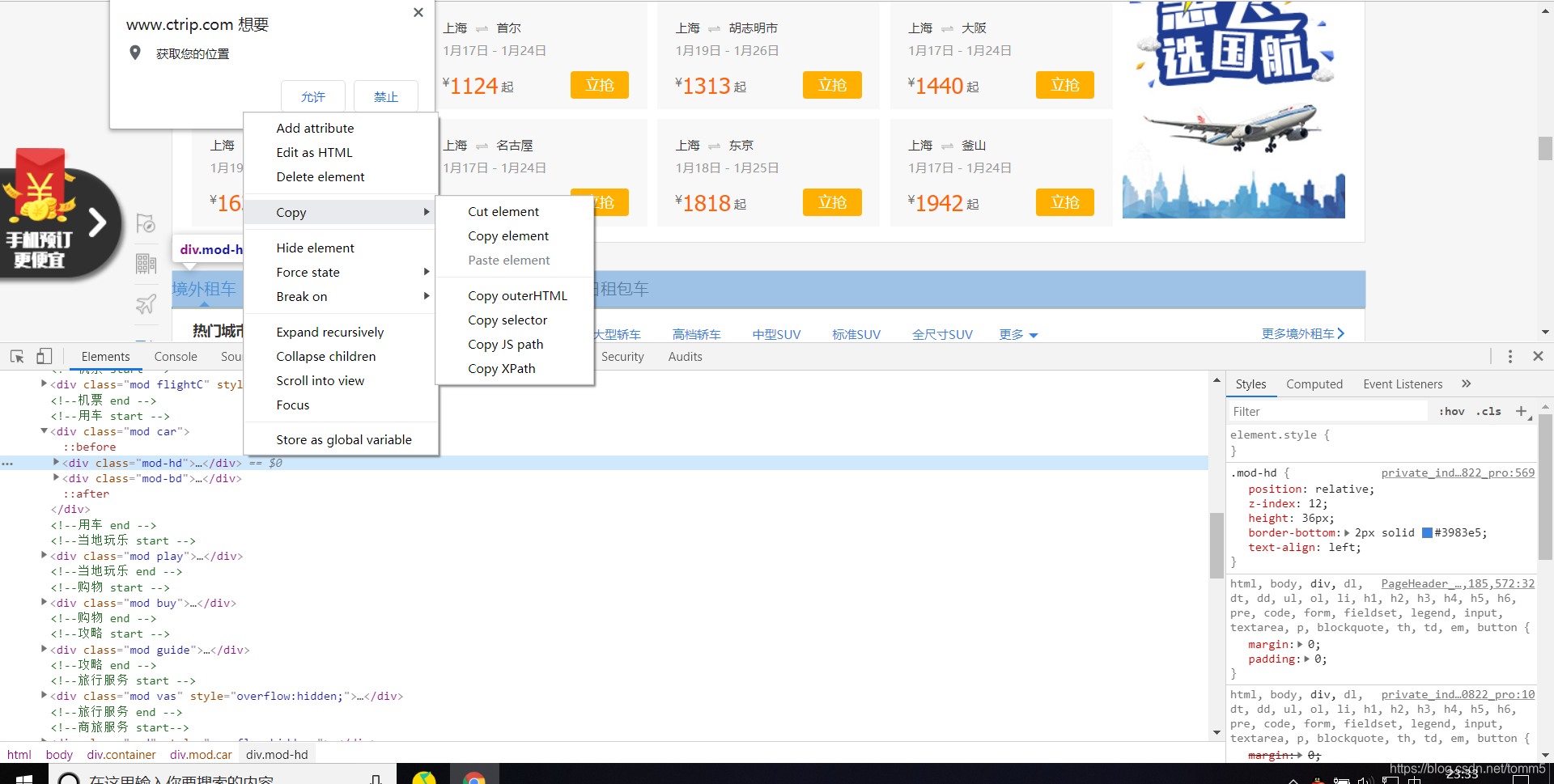
/html/body/div[14]/div[4]/div[1]
这个是我拷下来的选中区域的Xpath的路径表达式
很多内容摘抄置https://www.w3school.com.cn/index.html,感兴趣的小伙伴也可以到这里进行学习,如有侵权,请联系作者,谢谢。
