深度学习网络
深度学习是啥,以及各种网络原理什么的,以及它们有什么样的特点,这里都不去系统阐述了。不懂的自行出门右转补基础。这里我所采用的是CNN和RNN(双向LSTM)的混合网络,对每一个导联都搭建一个对应的模型训练,最终再进行综合。这是总体的大框架。 不过在讲具体地网络结构之前,我们这里先来看一个问题。
记录与片段的标签“冲突”
现在有很多论文都在使用CNN进行ECG的分类判别,他们的输入,多以心拍和短片段(例如3s,5s等)为主,几乎没看到以整条记录为输入的方案。个人认为,若以整条记录直接作为输入,有两个缺点:
- 一般记录的长度较大,信息量,特征种类必定也偏大。为了能最大程度地提取这些信息,每层配置的卷积核也需要更多,而这样会造成整个网络非常臃肿,而且也不利于局部特征的聚焦,但ECG的异常有时恰恰是一些局部的变化表征的。
- 记录的长度经常不等,而CNN一般接受等长的输入,一旦记录长度的变化范围比较大,那就要通过较大的人为延拓或是上下采样等方式使之等长,这对数据信息有一定的破坏作用。
所以将记录切成一个个小片段,能保证网络的精简,又能强化局部特征,确实是个不错的解决方案。但是,这里就存在个问题,标签是根据记录给定的,那么这些片段的标签怎么办?要知道,如果一条记录被判定为异常信号,并不意味着其中任意一段都是异常,最明显的,比如室性早搏:

如果像图中红框那样的切片,那自然可以跟记录的标签一致,因为确实包含了异常的部分;然而,如果不走运切到了像图中蓝框的片段,该片段是完全正常的,这时其实际标签跟记录的标签就发生了冲突。如果采用直接切片,并直接打上记录的标签,就会造成“误导”;而由于异常的发生的具体位置是很难精确预知的,想纠正这种“误导”,势必会增加人的干预。那现在我们想要这么一种方案:
- 输入确实是一条记录,而标签就是记录的标签,避免前述的标签冲突问题。
- CNN直接处理的应该是局部片段,保持其对局部特征的感知能力,同时使网络不至于太臃肿。
- 输入信号等长,而且要尽量减少对信号的延拓,最大程度保证原信号不被破坏。
基于上述的需求,下面我提出了一种解决方案,试图兼顾以上的条件。
我的方案
记录切片方式
CPSC-2018数据库中,最短的记录有6 s,最长的有144 s,最长是最短的24倍。以以上的几个属性为基准,我们对于每条记录统一切取24个片段,每条片段的长度为6 s。这样,除了最长的144 s的记录可以比较正常的,片段之间无重叠地切取,其他长度的记录的片段与片段之间都需要重叠才能满足条件,就像下图所示:

具体重叠的采样点长度,可以根据公式计算,设采样率为fs = 250 Hz,记录实际长度为L, 需要切取的片段数为n = 24,每片长度为l = 6 s则片段之间的重叠长度ol为:
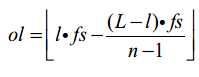
若记录长度就是6 s,则可以选择直接复制24次,当然,还可以在信号长度后延拓24-1个点,使得上式有意义。这里虽然也进行了人为延拓,但把人为延拓控制在了最小。这样,每条记录就被处理成了同样形式的24 * 6s片段组。同时,除了极少数极端短记录存在很小的人为延拓外,其他都尽量保持了原有的数据信息。那下一个问题就是,这样的数据形式,用什么样的网络来处理,保证其与记录标签的一一对应?
网络结构
这里,我们用24个独立的1维卷积(与池化)层组合处理24个片段。同时,这24个片段之间存在时间序列特性,因为我们是按照记录的时间顺序切取的。为了强化这种特性,使用双向LSTM汇总,再级联一个全连接层输出最后的分类结果。这么说可能有些抽象,直接上图:

在这个网络中,对于一条记录的24个片段,是作为一个整体,输入到不同的分支中。每个分支都是个1维CNN结构,处理的是一个6s的局部片段,有利于增强其对局部特征的感知;最终24个分支由一个双向LSTM强化它们之间的时间序列属性,由全连接层输出其最终的结果;由于片段之间一般互有覆盖,信息存在冗余,为减轻这种情况,在CNN与双向LSTM之间增加dropout,有利于减轻过拟合,提升泛化能力,而keep_prob按照经验值设为0.5。这样,用于loss计算的标签就是整条记录的标签,没有前述的冲突问题。整个网络基于keras(TensorFlow as backend)搭建, 采用SGD + Momentum的方法进行训练,具体参数设置可参见开源的代码文件。
对于每个导联,我们都会训练一个相同的网络。另外,对于网络的输入片段,都进行了z-score标准化。至于最后的得到的12个网络如何融合后面会讲到。
人工HRV特征提取与模型融合
HRV特征
我们经常会在文献中,尤其是时间较早的一些文献中,看到使用一些具体波形形态参数,例如QRS间期,PR间期,ST段斜率等作为特征来判定类别的方案。这类方案的出发点是提取这些特征,直接跟医学经验挂钩。但是,除了QRS波主波定位被认为是比较成熟之外,其他的基准点。例如P波及其起止点,T波起止点是较难准确定位的,即便现在有很多定位算法,但是其鲁棒性也远不如QRS波定位。而基于QRS波定位便可轻易得到的RR间期,进行心率变异性(Heart Rate Variability,HRV)分析是一个足够鲁棒的选择,同时,HRV分析在房颤,早搏等异常诊断上也常有应用,也有其相应的医学意义。
从另一方面来看,我们前面使用CNN自动学习特征。CNN的长处在于局部细节特征的提取,而HRV分析中的特征,例如计算RR间期的标准差,是一个典型的统计特征,显然CNN对类似的特征并未有特殊的设计。所以,在我们前面的深度学习网络基础上,补充一些HRV特征,或是跟RR间期相关的统计特征,能形成比较良好的互补,起码在直觉和理论上是这样的。因此,我引入了下面的一些特征。因为所有导联是同时采集的,在时间上是完全平行的,所以以下特征均以II导联为基准:
- RR间期标准差
- 最大RR间期
- 最小RR间期
- 平均RR间期
- pNN50:相邻RR间期差距大于50ms的比率
- R波密度:R波个数/记录长度
- RMSSD:相邻RR间期差值的均方根
- RR间期的采样熵:衡量RR间期变化混乱度
另外数据库也提供了每条记录所属个体的年龄和性别,这里也把这2个特征引入进来。
模型融合
对于每个12导联记录,现在我们得到了12个针对每个导联的深度学习模型,以及相应的人工特征。我们使用12个网络得到12组-9类别softmax概率,我们取前8个概率(由于所有概率相加为1,因此取8个就足够表示),共12*8=96个数值作为特征;加上我们的人工特征9+2=11个(根据参数设定,采样熵最终有两个返回值),得到107维特征。然后,基于这样的特征组合,再训练一个各类算法竞赛中大名鼎鼎的XGBoost,融合以上所有信息,得到最后的结果。同样,XGBoost的调参也仅针对平衡后的验证集进行。
小结
这一部分具体阐述了所采用方案的主体,包括神经网络和人工特征设计。其中,信号切片代码存于CPSC_utils.py,网络结构实现和人工特征设计代码存于CPSC_model.py,单导联网络训练存于CPSC_train_single_lead.py,所有导联网络训练存于CPSC_train_multi_leads.py, 人工特征的处理存于CPSC_extract_features.py, 最终的融合存于CPSC_mix.py。具体地,请参见开源代码:
https://github.com/Aiwiscal/CPSC_Scheme
喜欢请给star和fork。
