OCR文本扫描项目实战(图像预处理,调用pytesseract.image_to_string()完成文本识别)
本项目和源代码来自唐宇迪opencv项目实战
本文是一篇OCR文本扫描项目实战的学习笔记。在opencv-python环境下对图像进行轮廓检测、透视变换等处理。调用pytesseract模块实现文本扫描。
恳请批评指正
OCR文本识别
什么是OCR,百度里的定义是:
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。
简单说来,打印在纸上的“hello word”,将它以一张图片的形式输入到计算机中,计算机经过一系列的处理,识别出“hello word”,转化成了可以复制的文本格式就更好啦O(∩_∩)O。
OCR应用方面广泛,常见的比如翻译软件中的拍照翻译。
项目概述
本项目分为两部分:
1 对输入图像进行一系列预处理
2 对处理后的图像进行文本扫描并输出识别的结果
实现的流程图如图所示:
输入一张包含文字信息的的图片
处理后的结果如图所示:

进行OCR文本识别的输出结果为:

文末附代码
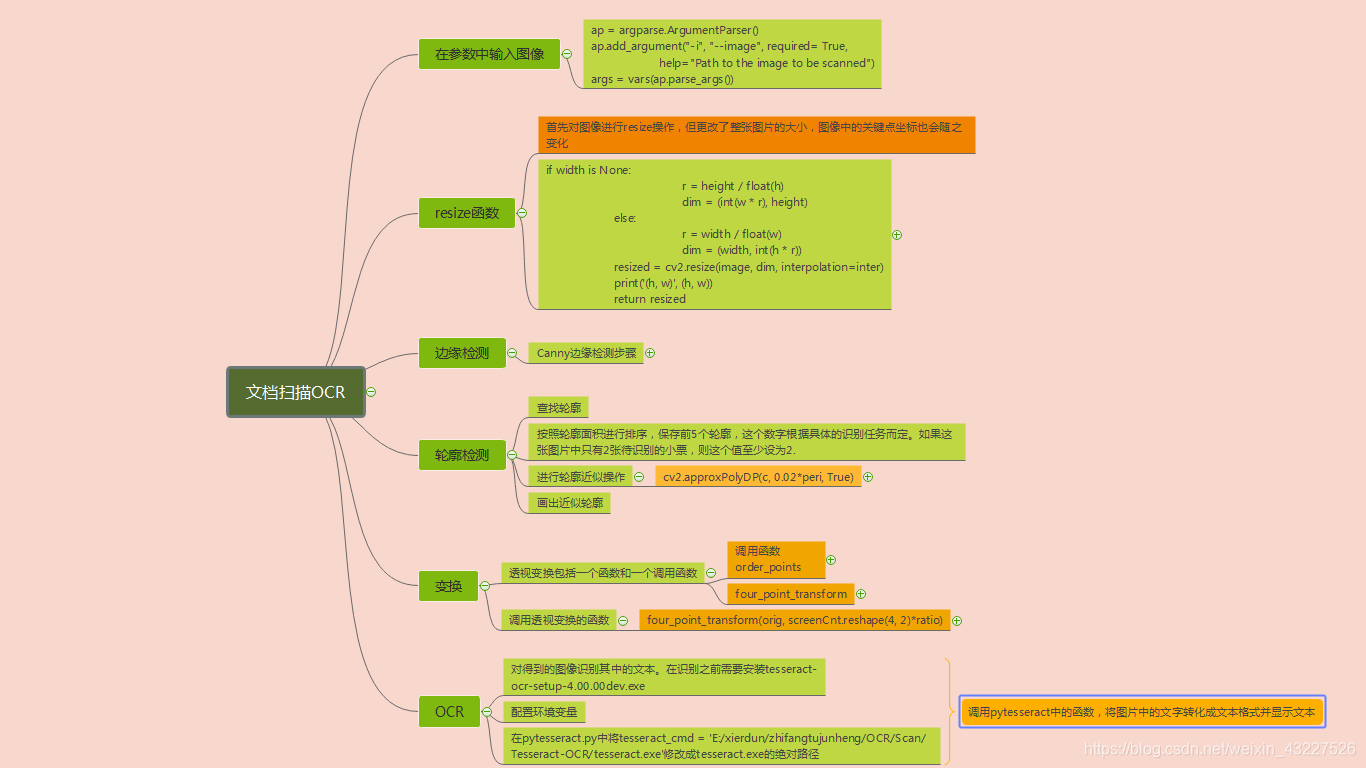
算法步骤
1 设置参数
在参数中输入图片的相对路径,将图片传入。
import argparse
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required= True,
help="Path to the image to be scanned")
args = vars(ap.parse_args())
参数修改为图片的相对路径:
–image images/hello.jpg
2 图片预处理操作
resize 操作
resize函数的作用是按照原图像相同长宽比,当给定长(height)或者宽(width)时将原图resize成与原图像同比例的大小。
至于这一步为什么要进行resize操作,我分析有两点原因。
1 实验使用的图像多为手机拍摄的图片,图片大小至少为3500*4000,在imshow(),在屏幕显示并不能像是完整的图像,不利于观察。
2 用原图直接调用pytesseract image_to_string时可能返回值为空(我没明白)
该函数的返回值是resize后的图片;参数是原图像和指定的变换后的width或height值。
接着对图像进一步操作
Canny边缘检测步骤
参考一篇写canny边缘检测的博客
1.使用高斯滤波器以平滑图像滤除噪声
2.计算图像中每个像素点的强度和方向
3.应用非极大值抑制(Non-maximum suppression,NMS)来消除边缘检测带来的杂散响应。
4.应用双阈值检测(Double-Threshold)来确定真实的和潜在的边缘
5.通过抑制孤立的弱边缘最终完成边缘检测。
Canny边缘检测之前需要先降噪----高斯滤波
GaussianBlur(src,ksize,sigmaX [,dst [,sigmaY [,borderType]]])-> dst
第一个参数是输入图像,可以是Mat类型,图像深度为CV_8U、CV_16U、CV_16S、CV_32F、CV_64F。
第二个参数是输出图像,与输入图像有相同的类型和尺寸。
Size ksize: 高斯内核大小,这个尺寸与前面两个滤波kernel尺寸不同,ksize.width和ksize.height可以不相同但是这两个值必须为正奇数,如果这两个值为0,他们的值将由sigma计算。
double sigmaX: 高斯核函数在X方向上的标准偏差
double sigmaY: 高斯核函数在Y方向上的标准偏差,如果sigmaY是0,则函数会自动将sigmaY的值设置为与sigmaX相同的值,如果sigmaX和sigmaY都是0,这两个值将由ksize.width和ksize.height计算而来。
Canny边缘检测函数
canny = cv2.Canny(gauss, 75, 200)
第一个参数时输入的图像,第二个参数是MinVal,第三个参数是MaxVal。
如果该点的梯度大于MaxVal, 则将该点处理为边界。如果该点的梯度大于MinVal且小于MaxVal,则抗癌电视都与边界相连,如果相连则将该点处理为边界,否则不是边界。如果该点小于MinVal则该点不是边界。
轮廓检测
查找轮廓,轮廓检测使用的模型是RETR_LIST,检测所有轮廓, 并将其保存在一条链表中
cv2.findContours(img, mode, methord)
下表列出了轮廓检测的模型mode
| MODE | 注释 |
|---|---|
| RETR_EXTERNAL | 只检测最外面的轮廓 |
| RETR_LIST | 检索所有轮廓,并将其保存到一条链表中 |
| RETR_CCOMP | 检索所有轮廓,并将他们组织为两层 ,顶层是各部分的外界边界,第二层是空洞的边界 |
| RETR_TREE | 检测所有轮廓,并重构嵌套轮廓的整个层次 |
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
检测到所有轮廓后根据轮廓面积大小对轮廓进行排序,并保留前五个,画出这按照面积排序的前五个轮廓(在绘制轮廓之前别忘了复制原图像,否则显示原图形也会被更改。)
** 轮廓近似**
定义一个循环,遍历轮廓,完成轮廓近似的操作。
peri = cv2.arcLength(c, True)
先计算出轮廓的周长,然后以轮廓周长乘以一个百分比作为轮廓近似的精度。
approx = cv2.approxPolyDP(c, 0.02*peri, True)
True表示轮廓是封闭的
而轮廓近似的返回值是能够包含图像的点的集合。既然是逐个点确定,又包含了整个图像,那一定是从最大的轮廓开始。当返回值的长度为4,即返回点的个数为4时,说明确定的就是能将最外面的最大轮廓包围的四边形的四个顶点。显示图像如图所示:

透视变换
透视变换(Perspective Transformation)是将成像投影到一个新的视平面(Viewing Plane)
自定义函数 order_points()
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
程序中定义了两个函数,order_point函数用一种方法来分辨这四个定位点分别对应于四边形的那个顶点,简单说就是给四个点起名字。
左下(bl), 右下(br), 右上(tr), 左上(tl),并将四个点按顺势者或逆时针依次存放。从那个点开始存放不重要,关键是要通过这四个点的坐标关系确定每一个点分别对应(四边形)的哪一个顶点。简单说来就是给每一个点起了一个代号,方便使用它,后面有用。
第二个函数 four_point_transform(image, pts)进行透视变换了。首先调用函数order_point,使用这四个起好名字的点。根据几个关系利用公式 s = ((x2-x1)2 +(y2-y1)2 )1/2 。因为四个点确定的近似轮廓不一定是矩形,所以分别取长和宽最大长度,
自定义函数 def four_point_transform()
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
dst对应的是与原图像中轮廓大小相同,只是进行了坐标变换的图像。左上角坐标点为(0,0),图像的长、宽分别为四边形轮廓长、宽最大值的四个定位点。将原图像中卡片的轮廓抠出来,变换了坐标。
透视变换函数包含在自定义函数four_point_transform()中
透视变换就是将原始的四个定位点,变换后定位点分别对应dst(左上角的定位点是(0, 0))中的四个定位点坐标。
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
返回时M是由原坐标透视变换到目标坐标点的变换矩阵。第二个返回图像的透视变换函数cv2.warpPerspective(image, M, (maxWidth, maxHeight))第一个参数是原始图像,第二个参数是变换矩阵(原图片中的小卡片是一个轮廓,变换后图像中小卡片充满了整张图像), 第三个参数是变换后图像的长和宽(场合宽是前面计算出的轮廓长宽取最大值的结果)。
最后该函数返回的结果是透视变换后的图像。
调用four_point_transform函数
warped = four_point_transform(orig, screenCnt.reshape(4, 2)*ratio)
说一下为什么要乘这个ratio
因为之前做的一系列图像处理操作(最后得到了近似轮廓的四个定位点)都是在resize后的图像上进行的。还记得resize函数是怎么做的吗,参数中给定width或者height的值,按照与原图像相同的比例对图像进行缩放。那么图像中每一个点的坐标都发生了相应的变化(不是面积大小,而是点的坐标发生了变化)
用plt显示图片验证一下
所以我们在程序一开始就把原图坐标和变化后图像的坐标的比例ratio记录下来。
我们刚刚说是图片上的每个像素点坐标发生了相应的变化,那么我们轮廓近似的四个定位点当然不例外就在其中。
所以相当于是吧原图像上的卡片四角的点坐标透视变换到与原图像相同大小的平面上,而four_point_transform函数的第二个参数scrrnCnt
中存储的坐标点应该与第一个参数中图像大小保持一致(都是原图或者都是resize变换后的,一致即可)。那我为什么要从一开始就做resize这一步呢?(因为图太大电脑屏幕放不下, 我要是有个巨大的屏幕是不是会省去很多麻烦)。
改了参数运行一下,嗯!
warped = four_point_transform(image, screenCnt.reshape(4, 2))
warped = four_point_transform(orig, screenCnt.reshape(4, 2)*ratio)
接下来就是灰度化、二值化一条龙服务。
终于把这张小卡片从图像中单独扣出来了!
结果如图所示:

附代码
# coding = utf-8
# 导入模块
import cv2
import numpy as np
import argparse
# 设置参数,输入图像为参数
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required= True,
help="Path to the image to be scanned")
args = vars(ap.parse_args())
# resize函数的作用是,按照原图像相同的长宽比,将图像的h转化到指定值大小,以改变图像的大小
def resize(image, width=None, height=None, inter=cv2.INTER_AREA):
dim = None
(h, w) = image.shape[:2]
if width is None and height is None:
return image
# 如果只给出了height值
if width is None:
r = height / float(h)
dim = (int(w * r), height)
else:
r = width / float(w)
dim = (width, int(h * r))
resized = cv2.resize(image, dim, interpolation=inter)
print('(h, w)', (h, w))
return resized
# 读取输入
img = cv2.imread(args["image"])
# 坐标变换
ratio = img.shape[0]/500
orig = img.copy()
# 调用resize函数
image = resize(orig, height=500)
# 图像预处理,
# Canny边缘检测
gray_img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# cv2.GaussianBlur(InputArray src, OutputArray dst, Size ksize, double sigmaX, double sigmaY=0, int borderType=BORDER_DEFAULT)
# 函数第一个参数为输入图像,第二个参数为输出图像, 第三个参数为该死内核的大小,
# 第四个参数表示高斯核函数在水平方向的标准差, 第五个参数表示高斯核函数在垂直方向的标准差
# 若sigmaY为零,就将它设为sigmaX,如果sigmaX和sigmaY都是0,那么就由ksize.width和ksize.height计算出来。
gauss = cv2.GaussianBlur(gray_img, (5, 5), 0)
canny = cv2.Canny(gauss, 75, 200)
# 检测轮廓
# 轮廓检测使用的模型是RETR_LIST,检测所有轮廓, 并将其保存在一条链表中
cnts = cv2.findContours(canny.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
# 根据面积大小, 对前五个轮廓进行排序
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5]
screen_five = cv2.drawContours(image.copy(), cnts, -1, (236, 0, 0), 1)
# 遍历轮廓,做轮廓近似
for c in cnts:
peri = cv2.arcLength(c, True)
# c表示输入的点集, epsilon表示从原始轮廓到近似轮廓的最大距离,它是一个准确度参数
# True表示是封闭的
approx = cv2.approxPolyDP(c, 0.02*peri, True)
# 当确定了四个点,就确定了轮廓
if len(approx) == 4:
screenCnt = approx
break
print("approx\n", approx)
# 不加括号的轮廓是指单独的点
img_four = cv2.drawContours(image.copy(), screenCnt, -1, (0, 0, 255), 5)
# 加括号的轮廓是指一个整体的轮廓
screen_img = cv2.drawContours(image.copy(), [screenCnt], -1, (0, 89, 255), 2)
# 透视变换
def order_points(pts):
# 一共4个坐标点
# 给定了四个坐标点,因为变换矩阵有8个未知数。
rect = np.zeros((4, 2), dtype = "float32")
# 按顺序找到对应坐标0123分别是 左上,右上,右下,左下
# 计算左上,右下
s = pts.sum(axis=1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
# 计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def four_point_transform(image, pts):
# 获取输入坐标点
# 原始坐标点
rect = order_points(pts)
# 4 3
# 1 2
(bl, br, tr, tl) = rect
# 计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
# 变换后对应坐标位置
# 变换后的坐标点
# dst对应的是与原图像中轮廓大小相同,只是进行了坐标变换的图像。左上角坐标点为(0,0),图像的长、宽分别为四边形轮廓长、宽最大值的轮廓
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
# 计算变换矩阵
# 计算从原始坐标到变换后坐标点的变换矩阵
# 原始图像为一个二维的歪歪扭扭的轮廓,先转化为三维矩阵,再转化成二维的位置纠正后的矩阵
# 透视变换(Perspective Transformation)是将成像投影到一个新的视平面(Viewing Plane)
# getPerspectiveTransform第一个参数是原始坐标点,第二个参数是变换之后的坐标点
# 给定了四个坐标点,变换矩阵M有8个未知数
M = cv2.getPerspectiveTransform(rect, dst)
# 利用四组坐标点能够求出变换矩阵M
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
# 返回变换后结果
return warped
# 一共有4个点,每个点都有x, y坐标,所以是(4, 2)
# 第一个参数是原图,第二个参数是取resize之后的四个轮廓点再乘以ratio就是又变换为原图的轮廓点的坐标
# 因为之前做的一系列图像处理操作(最后得到了近似轮廓的四个定位点)都是在resize后的图像上进行的。还记得resize函数是怎么做的吗,参数中给定width或者height的值
# 按照与原图像相同的比例对图像进行缩放。那么图像中每一个点的坐标都发生了相应的变化(不是面积大小,而是点的坐标发生了变化)
# 用plt显示图片验证一下
# 所以我们在程序一开始就把原图坐标和变化后图像的坐标的比例ratio记录下来。
# 我们刚刚说是图片上的每个像素点坐标发生了相应的变化,那么我们轮廓近似的四个定位点当然不例外就在其中。
# 所以相当于是吧原图像上的卡片四角的点坐标透视变换到与原图像相同大小的平面上,而four_point_transform函数的第二个参数scrrnCnt
# 中存储的坐标点应该与第一个参数中图像大小保持一致(都是原图或者都是resize变换后的)
# warped = four_point_transform(image, screenCnt.reshape(4, 2))
warped = four_point_transform(orig, screenCnt.reshape(4, 2)*ratio)
# 二值处理
warped_gray = cv2.cvtColor(warped, cv2.COLOR_BGR2GRAY)
img_thresh = cv2.threshold(warped_gray, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# img_thresh = cv2.threshold(warped_gray, 0, 255, cv2.THRESH_BINARY)[1]
cv2.imwrite('scan.jpg', img_thresh)
cv2.imshow("original_image", img)
cv2.imshow("reshape_image", image)
cv2.imshow("gaussBlur", gauss)
cv2.imshow("canny_img", canny)
cv2.imshow("screen_five", screen_five)
cv2.imshow("img_four", img_four)
cv2.imshow("screen_img", screen_img)
cv2.imshow("warped", warped)
cv2.imshow("warped_gray", warped_gray)
cv2.imshow("img_thresh", img_thresh)
cv2.waitKey(0)
cv2.destroyAllwindows()
至此图像预处理部分完成。并且保存了预处理的结果, scan.jpg
3 调用pytesseract进行OCR文本识别
接着在test.py中 import pytesseract 进行OCR识别
# https://digi.bib.uni-mannheim.de/tesseract/
# 配置环境变量如E:\Program Files (x86)\Tesseract-OCR
# tesseract -v进行测试
# tesseract XXX.png 得到结果
# pip install pytesseract
# anaconda lib site-packges pytesseract pytesseract.py
# tesseract_cmd 修改为绝对路径即可
from PIL import Image
import pytesseract
import cv2
import os
preprocess = 'blur' #thresh
image = cv2.imread('scan.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
if preprocess == "thresh":
gray = cv2.threshold(gray, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# 进行中值滤波
if preprocess == "blur":
gray = cv2.medianBlur(gray, 3)
# 获取当前进程id
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
text = pytesseract.image_to_string(Image.open(filename))
print(text)
os.remove(filename)
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
首先对图像进行灰度化处理, 然后进行均值滤波。
gray = cv2.medianBlur(gray, 3)
调用pytesseract.image_to_string()函数
pytesseract.image_to_string(Image.open(filename))
最后输出识别的文本

感谢所有应用的资源,谢谢你们的辛勤耕耘,受益匪浅。
https://blog.csdn.net/yangxuelian_lucky/article/details/90443367
https://www.cnblogs.com/mmmmc/p/10524640.html
