索引与完整性
索引
什么是索引?
当查阅书中某些内容时,为了提高查阅速度,并不是从书的第一页开始顺序查找,而是首页查看书的目录索引,为了找到需要的内容在目录中所列的页码,然后根据这一页码直接找打需要的内容。在SQL Server中,为了从数据库的大量数据中迅速找到需要的内容,也采用了类似于书目录的这样的索引技术,通过它能迅速的查到所需要的内容
索引的优点
索引的优点是根据表中一列或者若干列按照一定的顺序而建立的列值与记录行之间的对应关系表。在数据库建立索引主要有一下作用:
- 快速存取数据
- 保证数据记录的唯一性
- 实现表与表之间的参照完整性
- 在使用
order by/group by字句进行检索时,利用索引可以减少排序和分组的时间
索引的分类
SQL server支持在表中的任何列(包括计算列)上定义索引。按照索引的组织方式可将SQLserver分为聚集索引和非聚集索引两种类型
如果一个表没有创建索引,则数据行不按任何特定的顺序储存,这种结构称为堆集
聚集索引
聚集索引使得数据表物理顺序与索引一致。不论聚集索引里有表的哪个(或那些)字段,这些字段都会按顺序保存在表中。由于存在这种排序,所以每个表只会有一个聚集索引
由于数据记录按聚集索引键的次序储存,所以聚集索引对查找记录很有帮助
非聚集索引
在非聚集索引内,从索引指向数据行的指针成为行定位器。行定位的结构取决与数据页的存储方式是堆集还是聚集。对于堆集,行定位器是指向行的指针。对于有聚集索引的表,行定位器是聚集索引键。如果一个表只有非聚集索引,则它的数据行将按无序的堆集方式存储
一个表中可有一个或者多个非聚集索引
当在一个表中既要创建聚集索引又要创建非聚集索引时,应当先创建聚集索引,然后再创建非聚集索引,因为创建聚集索引时将改变数据记录的物理存放顺序
当在SQL server上创建索引时,可指定是升序还是降序储存
索引的创建
利用SQL命令建立索引
语法格式如下
create[unique][clustered|nonclustered]index 索引名
on 表名或视图名
(列名[,...][asc|desc])
where 字句
| 语句 | 说明 |
|---|---|
| unique | 表示为表或者视图创建一个唯一索引(即不允许存在索引值相同的两行)。例如对student表的学号列创建unique索引,即表示不允许有两个相同的学号出现。索引可以是唯一的,这意味着不会有两行相同的索引键值,这样的索引称为唯一索引。索引也可以不是唯一索引的,即多个行可以共享一个键值。如何索引是根据多列组合创建的,则这样的索引称为复合索引。注意:对于视图创建的聚集索引必须是unique索引。如果对已存在的数据表列创建唯一索引,则必须保证索引项对应的值无重复值 |
| clustered与nonclusterd | clustered表示创建聚集索引,nonclustered表示创建非聚集索引。一个表或者视图只允许有一个聚集索引,并且必须先为表或者视图创建唯一聚集索引,然后才能创建非聚集索引。默认为nonclustered |
| 索引名 | 索引名在表或者视图必须是唯一的,但是在数据库不必是唯一的;“表或者视图名”用于指定包含索引字段的表面或或者视图名;指定表名,视图名时可包含数据库和所属架构 |
| 列 | 指定建立索引的字段,可以为索引指定多个字段。指定索引字段时,注意表或者视图索引字段类型不能为ntext,text,image。通过指定多个索引字段可创建组合索引,但组合索引的所有字段必须取自统一表 |
| asc与desc | asc表示索引文件按照升序建立,desc表示索引文件按降序建立,默认为asc |
示例
表示索引文件按降序建立为kcb表的“课程名”列创建索引列,为“课程号”列创建唯一聚集索引
create unique clustered index kc_name
on
kcb(课程号)
同样,如果课程名已经创建了索引,只要索引名不同任然可以在该列创建索引
例子根据cjb表的“学号”列和“课程列”创建复合索引

create clustered index cjb_ind
on cjb
(学号,课程列)
with(drop_existing=on)
其中,drop_existing指定删除已存在的同名聚集或者非聚集索引。设为on表示删除并且重新生成现有索引;为off表示如果指定的索引已存在则显示一条错误信息:默认为off
重建索引
索引使用一段时间后,可能需要重新创建。这时,可以使用alter index语句来重新生成原来的索引
语法格式:
alter index {索引名|ALL}
on 表名或视图名
{rebuild
........
}
例子例如重建kcb表上的所有索引
alter index all
on kcb rebuild
例子重建kcb表上的kc_name索引
alter index kc_name on kcb rebuild
索引的删除
语法格式
drop index 索引名
on 表名或视图名
1.drop index可以一次删除一个或多个索引。
2.drop index不适合删除通过定义primary key或者unique约束的索引,若要删除primary key或unique约束创建的索引,必须通过删除约束实现
3.不能再系统表的索引上不能进行drop index操作
数据的完整性(约束)
出现的意义
数据库的数据是从外界输入的,由于种种原因,数据的输入会发生输入无效或者错误信息。为保证输入的数据符合规定,数据的完整性就此引出
数据完整性的分类定义
数据完整性是指数据库中的数据在逻辑上的一支性和准确性。数据完整性一般包括实体完整性,域完整性和参照完整性
实体完整性
实体完整性又称行的完整性,要求表中有个主键,其值不能为空且能唯一地标识对应的记录。可通过primary key约束和unique约束或者identity属性可实现实体完整性
primary key与unique约束
primary key
- 表中应有一个列或者列的组合,其值能唯一地标识表中的每一行,选择这样的一列或者多列作为为主键,可实现表的实体完整性,通过定义primary key约束来创建主键
- 一个表只能有一个primary key约束,而且primary key约束中的列不能取空值。由于primary key 约束能确保数据的唯一性,所以经常用来定义标识列。当为表定义primary key约束时,SQL server为主键列创建唯一索引,实现数据的唯一性。在查询中使用主键时,该索引可用来对数据进行快速访问
- 如果primary key约束是由多列组合定义的,则某一列的值可以重复,单primary key约束定义中所以列的组合值必须唯一
unique
- 如果要确保一个表中的非主键列不输入重复值,则应该在该列上定义唯一约束unique约束
primary key约束与unique约束的区别
- 一个数据表只能创建一个primary key约束,但一个表中可根据需要对表中不同的列创建若干的unique约束
- primary key字段的值不允许为null,而unique字段的值可取值为null
- 一般创建primary key约束时,系统会自动产生索引,索引的默认类型为簇索引。创建unique约束时,系统会自动产生一个unique约束,索引的默认类型为非簇索引
primary key约束与unique约束的相同之处
- primary key约束和unique约束的相同是:二者均不允许表中对应字段存在重复值
域完整性
- 域完整性又称为列完整性,指给列输入的有效性。实现域完整性的方法有:通过check约束,数据类型,default定义,not null定义和规则等
参照完整性
参照完整性又称为引用完整性。参照完整性保证主表中的数据与从表中的数据(被参照表)中的数据的一致性。在SQL server2014中,参照完整性的实现是通过定义外键与主键之间或外键与唯一键之间的对应关系来实现的。参照完整性确保键值在索引表中一致
码 :也称为“键”,是唯一标识表中记录的字段或者字段组合,通常一个表中有多个码,可选其中一个作为主键(主码),其余皆称为候选键
外码 :也就是外键,如果一个表中的一个字段或若干个字段的组合是另一个表的码,则称该字段或者字段组合为该表的外码(外键)
如果定义了两个表之间的参照完整性,则要求
1.从表不能引用不存在的键值
2.如果主表中的键值更改了,那么整个数据库中,对从表该键值的所有引用要进行一致的更改
3.如果主表中没有关联的记录,则不能将记录添加到从表。如果要删除主表中的某一记录,则应该先删除从表与该记录匹配的相关记录
实体完整性的创建,修改,删除
创建
利用T-SQL命令可以使用两种方式定义约束:作为列的约束或者表的约束,可以在创建表或者修改表时定义
1.在创建表的同时创建主键约束或者唯一性约束
语法格式:
create table 表名
(
{<列定义><列约束>}[,...]
[<表约束>][,...]
)
其中,<列约束>和<表约束>的具体格式如下:
<列约束>
[constraint 约束名]
{
{primary key|unique} /*定义主键与unique键*/
[clustered|nonclustered] /*定义约束的类型索引*/
[with<索引选项>[,...]]
[on {分区架构名(分区列名)|文件组|"default"}]
|[foreign key]<参照定义> /*定义外键*/
|check[not for replication](逻辑表达式) /*定义check约束*/
}
<表约束>
[constraint 约束名]
{
{primary key|unique}
[clustered|nonclustered]
(列[asc|desc][,....])
[with<索引选项>[,...]]
[on {分区架构名(分区列名)|文件组|"default"}]
|[foreign key]<参照定义>
|check[not for replication](逻辑表达式)
}
例子1
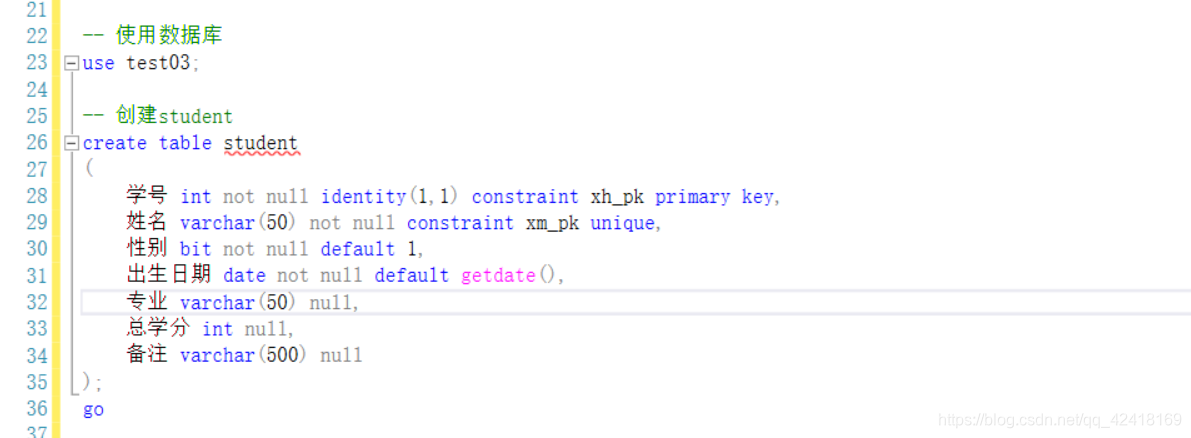
通过修改表结构创建主键约束或者唯一约束
使用alter table语句中的add字句可以为表中已经存在的列或者新列重新定义约束,语法格式:
-- 新增
alter table xsb3
add 身份证号码 char(20) constraint sf_pk unique nonclustered(身份证号码)
go
-- 修改
alter table xsb3
add 出生日期 date not null constraint xs_pk unique nonclustered
删除主键约束或者唯一约束
语法格式:
alter table 表名
drop constraint 约束名[,...]
示例
alter table xsb3
drop constraint sf_uk,xm_uk
go
域完整性 check/check rule
域完整性可以通过,数据类型,default,not null,check 约束/规则,实现。其中数据类型,default,not null,我们已经了解过,当前主要介绍check约束和规则实现域完整性
以命令的方式在创建表的时候创建check约束
check [not for replication](逻辑表达式)
- 关键字
check标识定义check约束。如果指定了not for replication选项,则当复制代理执行插入,更新或者删除操作时,将不会强制执行此约束。其后的逻辑表达式称为check约束表达式,返回值为true/false,该表达式只能为标量表达式 - check约束可定义为列约束,也可以定义为表约束。可同时定义多个check约束,中间用逗号隔开
实例在数据库中创建student表,要求学生的出生日期必须大于1994年1月1日
-- use test03
use test03;
go
-- create a new table the name is 'student_s'
create table student_s
(
学号 char(8) not null primary key,
姓名 char(8) not null,
性别 bit not null default 1,
出生日期 date not null check(出生日期>'1994-1-1'),
专业 char(12) not null default '计算机',
总学分 int null default 0,
备注 varchar(500) null,
constraint cs check(left(学号,2)='19' and 专业='计算机' or left(学号,2)='22' and 专业='通信工程')
);
go
定义后,在xsb1表中输入学号’22001’中的“22”与“计算机专业”不一致会显示错误
以命令方式在修改表时创建check约束
alter table 表名
[with{check|nocheck}]add
[<列定义>]
[constraint 约束名]check(逻辑表达式)
说明
- with字句:指定表中的数据是否用新添加的或重新启用foregin key或者check约束进行验证。如果未指定,则默认with check;如果不想根据现有数据验证新的check或者foreign key约束,则使用with nocheck(建议不要进行这样的操作)
- constraint 关键字:为check约束定义一个约束名
实例 通过修改pxscj数据库的cjb表,增加“成绩”字段的check约束
use pxscj;
go
alter table cjb
add constraint cj_constraint check(成绩>=0 and 成绩<=100);
以命令方式删除check约束
语法格式:
alter table 表名
drop constraint 约束名
参照完整性foreign key
在表创建时实现参照完整性
语法格式
create table 表名
(
<列定义>
[constraint 约束名]
[foreign key][(列名[,...])]<参照定义>
)
说明:
和主键一样,外键也可以定义为列的约束或者表的约束。如果定义为列的约束,则直接在列定义后使用foreign key关键字定义该字段为外键。如果定义为表的约束,则需要在foreign key关键字后面指定由哪些字段名组成外键,"列"为字段名,可以是一个字段或者多个字段
参照定义
references 参照表名[(参照列[,...])]
[on delete{no action|cascade|set null|set default}]
[on update{no action|cascade|set null|set default}]
[not for replication]
- on action:no action 意味着不采取动作,但是如果由一个相关的外键值在子表中,那么删除或者更新父表中主要键值的企图不被允许
- cascade:从父表删除或者更新行时自动删除或者更新子表中匹配的行
- set null:从父表删除或者更新行时,设置子表中与对应的外键列为null。如果外键列没有指定not null限定值,这就是合法的
- set default:作用与set null一样。但是不是指定为null,是指定为默认值
- 没有指定任何动作,默认no action
注意 如果指定not for relication选项,则当复制代理执行插入,更新或者删除时,将不会强制执行此约束
例子创建stu表,要求stu表中的所有学生学号都必须出现xsb表中,假设已经使用“学号”列作为主键创建了xsb表
use test;
go
create table stu
(
学号 char(8) not null foreign key(学号) references xsb(学号),
姓名 char(6) not null,
出生时间 datetime null
);
通过修改表定义外键约束
语法格式
alter table
add constraint 约束名
foreign key(列名[,''']) references 参照表名(参照列[,...])
以命令方式删除表间的参照关系
说明 删除表间的参照关系,实际上删除从表的外键约束即可
alter table 表名
drop constraint 参照名
