Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象、直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句。
Python支持命令式程序设计、面向对象程序设计、函数式编程、面向切面编程、泛型编程多种编程范式。与Scheme、Ruby、Perl、Tcl等动态语言一样,Python具备垃圾回收功能,能够自动管理存储器使用。它经常被当作脚本语言用于处理系统管理任务和网络程序编写,然而它也非常适合完成各种高级任务。Python虚拟机本身几乎可以在所有的作业系统中运行。使用一些诸如py2exe、PyPy、PyInstaller之类的工具可以将Python源代码转换成可以脱离Python解释器运行的程序。
本期用到json,requests库来爬取网页信息,这次爬的是一个特殊多页式网站,普通多页式网站只需分析不同页面的url,找出其中的不同点,用for in来循环即可,但是斗鱼的L中不同页面都是相同的url,这就需要去“F12”来寻找其中的区别。
工具.环境:Python3.6.5,Pycharm,windows10,Firefox
python
1.首先来寻找不同页面的区别
以斗鱼的LOL板块为例:尝试切换不同页面都是相同的url,那怎么办呢??????????按F12呼出开发者工具(在这推荐使用Firefox或chrome浏览器,我用的是Firefox)
开发者工具
要详细学习开发者工具的请自行百度,这里直接选择网络,会看到很多数据,数据发送方法分两种,为“post”and“get”。再选择XHR,点击左上角的删除键,再重新载入网页,就会看到电脑又向服务器发送了多个请求。
网络-XHR。
再重复多换几个页面,发现每次换的页码都与其中一个请求名相同

发现不同
点击该条信息,在右边显示该条信息的消息头,有一个请求网址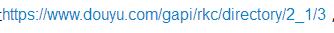

python学习路线分三大阶段:基础-进阶-框架-项目实战
基础第一阶段:基础Python的理解。基础第二阶段面对对象编程(注重编程能力)
基础第三阶段面向对象“设计思想”-封装-继承。基础第四阶段python高级专题。
进阶班第一阶段:linux基础。第二:python web工具。第三python部署工具。
第四关系型数据库。第五Python web框架基础原理。
框架阶段.python web开发第一阶段web.py。基础第二Django基础。
第三flask基础。第四tornado基础,
项目实战:个人博客系统-微信开发-企业OA系统=网盘系统
2.get页面信息
打开1中get到的网址
JSON
发现里面有我想要爬取的斗鱼房间信息,那么就是它了,接下来要对它进行解剖。
(1)运用requests来get该网页的信息
import requestsimport jsonurls = ['https://www.douyu.com/gapi/rkc/directory/2_1/{}'.format(page) for page in range(1, 5)]for url in urls: res = requests.get(url) print(res.text) # 可以想先看看get到的是个什么东西
这里运用for in循环来get到1-5页的网页信息for page in range(1, 5),具体见上面代码
(2)运用json库来将已编码的 JSON 字符串解码为 Python 对象
import requestsimport jsonurls = ['https://www.douyu.com/gapi/rkc/directory/2_1/{}'.format(page) for page in range(1, 5)]for url in urls: res = requests.get(url) j = json.loads(res.text) print(j) # 可以看到已解码的对象
json.dumps:将 Python 对象编码成 JSON 字符串json.loads:将已编码的 JSON 字符串解码为 Python 对象
3.处理对象数据
对象数据
看到了一堆糊糊,这时Firefox的优势就体现出来了
json
可以看到各层的所属关系,便于接下来的提取数据,下面是完整代码:
import requestsimport jsonurls = ['https://www.douyu.com/gapi/rkc/directory/2_1/{}'.format(page) for page in range(1, 5)]for url in urls: res = requests.get(url) j = json.loads(res.text) l1 = j['data'] # 通过观察可以发现要的数据在data下 l2 = l1['rl'] #在观察发现在data的rl中 tplt = '{0:{4}<20}\t{1:<12}\t{2:{4}<25}\t{3:<12}' print(tplt.format('主播', '房间号', '房间名', '热度', chr({{12288:0}}))) for i in range(len(l2)): # 这里用到for循环来处理一个列表下多个字典的数据 zhubo = l2[i]['nn'] room = l2[i]['rid'] redu = l2[i]['ol'] roomname = l2[i]['rn'] print(tplt.format(zhubo, room, roomname, redu, chr({{12288:0}})))
4.结果
运行程序
斗鱼LOL板块房间数据
遇到的问题:在名字中出现中英文混合的字符,会出现对不了齐的问题,有解决方法的可以在评论区分享!谢谢

Python可以做什么?
web开发和 爬虫是比较适合 零基础的
自动化运维 运维开发 和 自动化测试 是适合 已经在做运维和测试的人员
大数据 数据分析 这方面 是很需要专业的 专业性相对而言比较强
科学计算 一般都是科研人员 在用
机器学习 和 人工智能 首先 学历 要求高 其次 高数要求高 难度很大
我有一个微信公众号,经常会分享一些python技术相关的干货;如果你喜欢我的分享,可以用微信搜索“python语言学习”关注。
欢迎大家加入千人交流答疑群:588+090+942