目录
Python基础(五)--函数
1 函数的作用
1.1 函数定义与调用
函数的概念:函数是具有一定功能的代码块,该代码块可以重复的执行。
函数的定义方式如下:
def 函数名(参数列表):
函数体
函数的调用:当定义了一个函数即定义了一个功能后,我们使用该功能就称之为函数的调用。当调用函数时,程序会跳转到函数定义处执行函数体,当函数体执行完毕后程序流程会返回给函数的调用端,继续执行调用后的语句。
# 函数的定义
def print_triangle():
for i in range(9):
for j in range(i+1,9):
print("*",end=" ")
print()
# 函数的调用
print_triangle()
1.2 函数的作用
(1)避免代码重复,实现代码的复用
(2)对功能进行详细的划分,在需要使用功能时,就可以调用该函数。
1.3 空语句
在程序设计时,我们就可以先把程序划分成若干个功能,具体的实现可以后续再完成。此时,我们就可以使用pass来进行占位。pass表示空语句,用在函数中用来进行占位。pass也可以放在选择与循环体中。
# 空函数
def vacancy():
pass2 参数与返回值
2.1 函数的参数
在函数定义时提供的参数,称为形式参数;在函数调用是提供的参数称为实参;在函数调用的过程中,实际参数会赋值给形式参数。
参数的作用:功能是由函数本身所决定的,但是功能具有一定的细节,具体的细节通过参数进行调整控制。
# 函数的定义
def print_triangle(length):
for i in range(length+1):
for j in range(i+1,length+1):
print("*",end=" ")
print()
# 函数的调用
print_triangle(2)
print_triangle(3)
2.2 函数的返回值
函数也是可以具有返回值,该返回值会返回给函数的调用端。语法上,使用return来实现。遇到return,函数就会终止执行,同时将return后的值返回给调用端
当调用函数时,可以近似的认为是函数的返回值替换掉了函数的调用。
如果在函数内没有显式使用return返回值,则返回值为None。
def add(x,y):
return x + y
print("不会执行")
# 函数的返回值替换掉了函数的调用
result = add(1,1)
print(result)
# 函数总有一个返回值,如果没有显示调用return,默认为None
def add1(x,y):
sum = x + y
result1 = add(1,1)
print(result1)
2.3 返回多个值
在函数中,当执行到return语句时,函数就会终止执行,返回给函数的调用端,这就是说,return之后的语句不会再执行。因此,函数体中不能通过执行多个return,返回多个值。可以通过将多个值放入元组(列表或字典)中,从而返回多个值。
# 返回多个值。可以通过将多个值放入元组(列表或字典)中,元组比较合适,因为元组不能修改
def operation(x,y):
return (x + y,x - y,x * y,x / y)
print(operation(2,2))![]()
3 参数的默认值
3.1 可选参数
如果一个参数含有默认值,则该参数就称为一个可选参数,可有可无。
如果显式传递了该函数,则该参数的值就是我们传递的值,如果没有则是该参数的默认值
3.2 参数的默认值
(1)参数默认值的要求
如果形参含有默认值,则在函数定义时,含有默认值的形参一定要定义在不含默认值的形参之后。
这是因为,如果形参含有默认值,则意味着,该参数是一个可选参数,在函数调用时,可以选择性的进行传值。如果允许含有默认值的形参定义在不含默认值的形参前面,就会造成混淆。
# 函数的定义
def print_triangle(length,char="*"):
for i in range(length+1):
for j in range(i+1,length+1):
print(char,end=" ")
print()
# 函数的调用
print_triangle(3)
print_triangle(3,"@")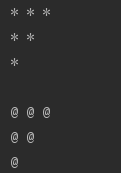
(2)含有默认值的意义
①可以另函数的功能变得简单;
②可以兼容之前的程序
(3)注意事项
形参默认值,其只是在声明的一刻进行求值,并且仅求值一次。因此,当使用可变类型作为参数默认值时,可能会带来意外的结果。
在Python中,函数也是对象,我们给形参增加的默认值,也是保存在函数中。我们可以通过函数对象的__defaults__属性来获取函数形参的默认值。__defaults__返回的是一个元组类型,包含函数定义时,形参所有的默认值。
# 注意:函数的形式参数的默认值是在函数定义的时候解析器计算,不是调用的时候计算,因此参数的默认值只计算1次
num = 6
def add(a,b=num):
print(a+b)
num = 10
add(6)
# 当默认值是可变对象时,要特别注意,每次调用都会改变
def fun(a=[]):
a.append(10)
print(a)
fun()
fun()
# 获取函数的默认值,返回的是一个元组
print(fun.__defaults__)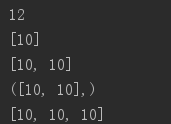
4 位置参数与关键字参数
位置参数与关键字参数是针对实际参数而言的。
在调用函数时,如果函数定义了形式参数,则我们需要在调用时,传递相应的实际参数(如果形参具有默认值可不传递),形式为按顺序,一一对应的方式。即第一个实参传递给第一个形参,第二个实参传递给第二个形参……,这种对位传递的实际参数为位置参数。
除了位置参数之外,我们还可以使用关键字参数。所谓关键字参数,就是在调用函数时,显式指定“参数名=参数值”的形式,即指定要给哪一个形参传递值。
在调用函数时,可以混合使用位置参数与关键字参数。
4.1 关键词做参数
优点:(1)增加程序的可读性
(2)可以不考虑传递的顺序
(3)当多个形参存在默认值时,关键字参数能够指定赋值给哪个形参。
注意:
(1)位置参数必须在关键字参数前面
(2)同一个参数不能传递多次
(3)关键字参数的顺序可以颠倒,但是提供的参数名必须存在
def add(a,b,c):
pass
# 位置参数传递值
add(1,2,3)
# 关键字参数传递值
add(a=1,b=2,c=3)
# 同一个参数只能传递一次,否则出错
# add(1,2,c=3,b=5) 报错
# 位置参数必须位于关键字参数前
# add(b=2,2,3) 报错强制使用关键字参数:
了能够增强程序的可读性,同时实现编程风格的一致性,函数的定义者可以使用“*”语法,来限制“*”后面的所有参数必须都是以关键字参数的形式传递。强制使用关键字往往针对的是具有默认值的参数,但从语法的角度讲,对于不含默认值的参数,也是可以的。
# 强制使用关键字参数 ,使用*
def add(a,*,b=5):
pass
# add(1,2) TypeError: add() takes 1 positional argument but 2 were given
# 正确写法为
add(1,b=2)5 可变参数
5.1 两种可变参数
(1)两种可变参数
在定义函数时,我们可以定义可变参数(形式参数),所谓可变参数,即可以接收不定数量的实际参数。可变参数有两种形式:①位置可变参数(*);②关键字可变参数(**)
(2)参数打包
函数调用时,位置可变参数(形参)可以用来接收所有未匹配的位置参数(实参),而关键字可变参数(形参)可以用来接收所有未匹配的关键字参数(实参)。在函数调用过程中,所有未匹配的位置参数会打包成一个元组,而所有未匹配的关键字参数会打包成一个字典。
# *v位置可变参数,**kv关键字可变参数
def fun(*v, **kv):
print(type(v))
print(v)
print(type(kv))
print(kv)
fun(1,2,3,a=11,b=22)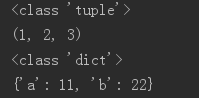
注意:
①可变参数只能接收未匹配的(剩下的)实际参数,如果实际参数已经匹配某形式参数,则不会由可变参数接收。
②在参数位置上,关键字可变参数必须位于函数参数列表的最后。
③在位置可变参数后面定义的参数,将自动成为关键字参数。
④位置可变参数与关键字可变参数各自最多只能定义一个。
(3)位置可变参数
def sum(*value):
(4)关键字可变参数
在接收一些可选的选项,设置时,对于选项较多时,如果将每个选项都用一个关键字参数来接收时,会显得函数定义特别庞大,此时,就可以使用一个关键字可变参数来实现。
# 位置可变参数,可以用来接收任意数量的位置参数,在参数前面加*
# 在函数调用过程中,会执行打包操作,位置可变参数是一个元组类型
def sum(*a):
print(type(a))
sum = 0
for i in a:
sum += i
return sum
result = sum(1,2,3)
print(result)
# 关键字可变参数,可以用来接收任意数量的关键字参数,在参数前面加上**
# 在函数调用过程中,会执行打包操作,关键字参数打包成字典类型
def sum(**kv):
print(type(kv))
print(kv)
sum(a=1,b="abc",c=[1,2,3])
# 万能参数列表,可变关键字参数必须位于参数列表最后
def omnipotent(*a,**kv):
pass
5.2 打包与拆包
拆包:将序列类型拆分为多个位置参数,或者将字典类型拆分成多个关键字参数。
其实,在进行平时赋值时,也会隐式发生元组的打包与拆包操作。
# 拆包
def sum(a,b,c):
print(a,b,c)
# 序列拆包
param = (1,2,3)
sum(*param)
# 字典拆包,分解为若干关键字参数的形式
param2 = {"a":"aaa","b":"bbb","c":"ccc"}
sum(**param2)
6 参数传递
同过参数传递,我们可以使形式参数与实参绑定相同的对象,通过形参可以改变实参所绑定的数据对象。
注意:不能通过改变形参所绑定的对象,进而影响实参。实参所绑定的对象不会进行更改,即在函数调用前,实参绑定到哪个对象,在函数调用之后,实参依然会绑定原来的对象。
def fun(a):
a.append(100)
li = [1,2,3]
fun(li)
print(li)
def fun(a):
a = []
li = [1,2,3]
fun(li)
print(li)
7 命名空间与作用域
7.1 命名空间
命名空间:可以认为是保存命名的一个容器,当定义变量,函数,类等结构时,相关的名称就保存在相应的命名空间中。根据名称在当前模块(文件)中定义的位置,根据命名可以将名称分为两类:局部命名空间(定义在函数内的名称(函数的参数,变量,嵌套函数等))和全局命名空间(定义在函数、类外的名称(处于当前模块的顶级)。)
命名空间可以有多个,不同的命名空间可以保存相同的名称,彼此之间不会受到干扰
命名空间可以分为如下几类:
①内建命名空间:保存内建的名称。例如,print,sum等内建函数。内建命名空间在Python解释器启动时就会创建,直到程序运行结束。
②全局命名空间:保存当前模块(文件)中出现在顶层位置的名称。例如:全局变量,顶层函数等。全局命名空间与模块相关,在读取模块定义时创建,直到程序运行结束。
③局部命名空间:保存局部名称。例如,局部变量,函数参数,嵌套函数等。局部命名空间在函数执行时创建,在函数执行结束后销毁。
所以我们定义的函数,变量等其名称属于哪个命名空间,由其定义的位置决定。对于变量,定义的位置就是变量第一次赋值的位置。对于函数,定义的位置就是def出现的时刻。
# 全局变量
x = 6
# 全局函数
def overall():
# 局部变量
y = 1
# python函数可以嵌套
# 局部函数
def inner():
pass7.2 作用域
作用域,就是命名空间的有效区域。在作用域内,我们可以直接访问命名空间中的名称。
①内建命名空间,作用域为所有模块(文件)。在任何模块(文件)中均可直接访问内建命名空间内的名称。
②全局命名空间,作用域为当前模块(文件)。在当前模块(文件)中可直接访问全局命名空间内的名称,在其他模块(文件)中,需要先导入该模块,然后才能访问(模块导入的内容后面介绍)。
③局部命名空间,作用域为当前函数,在函数内可访问局部命名空间内的名称,在函数外则无法访问。
7.3 LEGB原则
在访问名称时,会根据LEGB的顺序来搜索名称,即搜索顺序为L -> E -> G -> B。描述如下:
①L(Local):本地作用域,即包含所访问名称的最小作用域(当前函数的局部命名空间)。
②E(Enclosing)外围作用域,当函数嵌套时会存在这种情况,即访问外层函数的作用域,如果没有找到,并且外层函数依然还有外层函数(函数多层嵌套),则会继续搜索更外层的函数,直到顶层函数位置(对应外层函数的局部命名空间)
③G(Global)全局作用域,当前模块的作用域(全局命名空间)。
④B(Build-in)内建作用域,所有内建的名称(内建命名空间)。
在读取名称值时:如果该变量在当前作用域没有发现,则会按照LEGB的方式依次进行查找,以先找到的为准。如果到最后也没有找到,则会产生NameError错误。
为名称赋值时:会在程序执行处的最小作用域内寻找变量,如果变量存在,则修改该变量的绑定,如果该变量不存在,则不会再按照LEGB的顺序查找,而是在当前作用域的命名空间中,新建名称,并绑定所赋予的值。这也就是说,我们无法修改其他命名空间中名称的绑定。
注意:命名空间有什么在函数解析的时候已经确定下来了,尽管命名空间是在调用的时候才创建但是该有什么没有什么在函数解析的时候已经能够决定好的,不会等到一步步执行的时候才确定下来
# 全局变量
x = 6
# 全局函数
def overall():
x = 8
print(x)
overall()
print(x)
def overall2():
# 命名空间中存在哪些名称不是在执行的时候一点一点创建出来的,是在解析编译的时候已经能够决定有哪些。在解析的时候已经发现有x了,那就认为会在当前的这个命名空间中去创建这个x,所以在print的时候就认为是这个局部的命名空间,而不是全局的命名空间x。因为print访问x的时候发现还没有被赋值(没有绑定任何有效的对象),所以报错
# print(x) 报错:UnboundLocalError: local variable 'x' referenced before assignment
x = 8
overall2()
def overall3():
# x = x + 1 报错:UnboundLocalError: local variable 'x' referenced before assignment 原因如上访问x的时候x还没有被赋值
pass
overall3()![]()
删除命名空间是:当删除名称时,其表现行为与为名称赋值是一致的。即只能删除当前作用域的名称,而不能删除外层作用域的名称。
nonlocal与global:当期望对外部作用域的名称进行修改时,可以使用nonlocal或者global。
注意:nonlocal指定的名称不存在,会产生错误,而global指定的名称不存在则不会产生错误,但是该名称也不会自动创建,如果访问该名称,依然会产生错误。
# 内建命名空间的优先级最低,所以我们自己定义的名称一定会覆盖命名空间的名称
id = 6
print(id)
# 在当前命名空间下无法修改或删除其他命名空间的名称,如果希望修改其他命名空间的
# 名称,可以借助global或nonlocal
del id
print(id(8))
# 全局命名空间
def overall():
# 进行声明,表示我们要操作的是全局命名空间,而不是当前命名空间
global a
a = 66
overall()
print(a)
def overall2():
b = 88
def inner():
# 进行声明,表示我们要操作的是外围命名空间中的名称,而不是当前局部命名空间中的名称
nonlocal b
b = 99
inner()
print(b)
overall2()
# 注意:global指定的名称如果不存在,不会产生错误,而nonlocal指定的名称不存在会产生错误
def fun():
global no_exist
def inner():
# nonlocal no_exist 指定的命名空间不存在报错
pass
inner()
fun()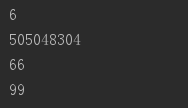
8 Lamabda表达式
对于函数而言,函数名也是一个名称,该名称绑定函数对象。因此,我们也可以像变量那样,对函数名进行相应操作,如:①将函数名赋值给一个变量②将函数名作为实际参数传递给其他函数③函数名可以作为另外一个函数的返回值
可以使用Lambda表达式来创建函数,Lambda表达式的语法为:
lambda [参数]: 表达式
参数是可选的,表达式的结果值,就是函数的返回值。lambda表达式的函数体仅能存在一条语句,故lambda表达式适用于功能简单的函数。也因为lambda表达式创建的函数没有名字,因此也称为匿名函数。
# 变量与函数都是一个名称,函数名可以像变量名那样操作
def print_hello():
print("hello")
print_hello()
# 函数名可以进行赋值,赋值给一个变量
a = print_hello
# 通过a调用函数
a()
def fun(b):
return abs(b)
li = [-5,-2,6]
# 将函数名作为实际参数传递给其他函数
li.sort(key=fun)
print(li)
# 函数名可以作为另外一个函数的返回值
def outer():
c= 6
def inner():
pass
return inner
d = outer()
# lambda表达式用来定义匿名函数,lambda [参数]:返回值表达式
li.sort(key=lambda x : abs(x))
print(li)
def lam():
return lambda x : x + 2
9 递归
9.1 什么是递归
递归,就是一个函数直接或者间接调用自身的过程。
函数如果无条件的调用自身,这是没有意义的,最终也会导致超过最大递归深度而产生错误。因此,我们必须能够找出,让递归终止的条件。
递归,可以分为递推与回归。递推:就是解决问题,逐层的进行推理,得出递归的终止点。回归:则是利用刚才递推取得终止点的条件,再一层层返回,最终取得答案的过程。
9.2 循环与递归
循环与递归具有一定的相似度,二者往往可以实现相同的效果。理论上,能够通过循环解决的问题,使用递归也能够实现。
从思想的角度看,循环是重复性的执行一件相同或者相似的事情,进而得出结果。而递归则是将问题分解为更小的问题,直到该问题能够解决,然后再由最小问题的答案,逐步回归,从而解决更大的问题,最终解决整个问题的过程。
递归的默认深度为1000。
# 循环求和
def loop(a):
sum = 0
for i in range(1,a+1):
sum += i
return sum
print(loop(10))
# 递归求和
def recur(b):
if b == 1:
return 1
else:
return b + recur(b-1)
print(recur(10))![]()
9.3 递归的深度
递归的默认深度为1000。递归的默认深度,应该将其理解为最大函数调用限制。
# 递归的深度
import sys
# 返回递归的最大深度
print(sys.getrecursionlimit())
# 设置递归的最大深度
sys.setrecursionlimit(3)
def first():
two()
def two():
third()
def third():
four()
def four():
pass
first()
10 高阶函数
如果一个函数的接收另外一个函数作为参数,或者该函数将另外一个函数作为返回值,则这样的函数称为高阶函数。
常用的高阶函数有:
(1)map(func, *iterables)
def sum(a):
return a + a
# map的第一个参数为一个函数,第二个参数为一个可迭代的对象
# 对可迭代对象中的每一个元素,调用一次函数(即第一个参数),将该元素传入获得返回值,将所有返回值作为一个可迭代对象返回
m = map(sum,[6,8,10])
print(m)
for i in m:
print(i,end=" ")
print()
# 上面的函数可以用lambda
m1 = map(lambda a : a+a, [6,8,10])
for i in m1:
print(i,end=" ")
print()
# map可用列表推导式代替,所以使用频率较低
li = [6,8,10]
print([i + i for i in li])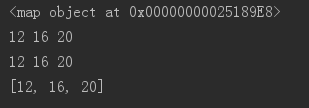
(2)filter(function or None, iterable)
# filter,第一个参数为一个函数,该函数具有一个参数,第二个参数为可迭代对象
# 对可迭代对象中的每一个元素,调用一次函数,将元素传入,获得返回值,将所有返回值为True的元素保留,返回一个可迭代对象
f = filter(lambda a : a > 3,[1,2,3,4,5,6])
for i in f:
print(i,end=" ")
print()
# filter也可用列表推导式代替,所以使用频率较低
li=[1,2,3,4,5,6]
print([i for i in li if i>3])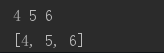
(3)reduce(function, sequence[, initial]) -> value
从Python3.0起,reduce不在是内置函数(Python2是内置函数),而是将其迁移到了functools模块中。
# reduce,第一个参数为一个函数,具有两个参数,第二个参数为可迭代对象,第三个参数为初始值(可选)
import functools
li = list(range(1,6))
print(functools.reduce(lambda x,y:x+y,li))![]()
11 函数描述
11.1 函数说明文档
说明文档,就相当于是函数的使用说明书,在文档中可以用来说明函数的功能,参数,返回值类型以及相关注意事项,使用示例等。要为函数编写说明文档,可以在函数体的上方,使用字符串进行标记。按照惯例,作为说明文档的字符串使用三个双引号界定,并且第一行为函数的一个简要说明,接下来是一个空行,然后是函数的具体说明。
def fun():
"""这里是函数的简要说明。
这是是函数的具体功能说明。(注意存在一个空行)
"""
# 函数语句
注释内容,则解释器会忽略,但是,作为函数文档,我们可以通过函数的__doc__属性获取这些说明,方便我们进行查看。同时,我们使用help函数来获取帮助时,返回的就是函数的说明文档信息。
11.2 函数注解
在Python中,变量是没有类型的,对于函数来说,无法像C或Java语言那样,只要观看函数的定义,就可以轻松的确定函数的参数与返回值类型。为了弥补这种不足,使代码更具有可读性与易用性,我们可以使用函数注解来进行标注,显式指定函数参数或返回值的类型。
def add(a: int, b: int=3) ->int:
参数的说明是在参数后面加上一个:然后给出参数的类型。根据惯例,:与其后的类型使用一个空格分隔。返回值说明是在参数列表的)后,使用->指出。
可以使用函数对象的__annotations__属性获取函数的注解信息。该属性是一个字典类型。
