目标检测基础
- 目标检测算法用于预测出输入目标的真实边界框
锚框
- 中心思想:以每个像素为中心生成多个大小和高宽比不同的边界框。当中心位置给定时,已知宽高的锚框也确定了。
- 过程:在目标检测时,生成多个锚框,对锚框预测类别和偏移量,根据预测值调整锚框位置从而得到预测边界框,最后经过筛选得到输出的预测边界框
def MultiBoxPrior(feature_map,sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5]):
pairs = []
for r in ratios:
pairs.append([sizes[0], math.sqrt(r)])
for s in sizes[1:]:
pairs.append([s, math.sqrt(ratios[0])])
pairs = np.array(pairs)
# 生成相对于坐标中心点的框(x,y,x,y)
ss1 = pairs[:, 0] * pairs[:, 1]
ss2 = pairs[:, 0] / pairs[:, 1]
base_anchors = np.stack([-ss1, -ss2, ss1, ss2], axis=1) / 2
#将坐标点和anchor组合起来生成hw(n+m-1)个框输出
h, w = feature_map.shape[-2:]
shifts_x = np.arange(0, w) / w
shifts_y = np.arange(0, h) / h
shift_x, shift_y = np.meshgrid(shifts_x, shifts_y)
shift_x = shift_x.reshape(-1)
shift_y = shift_y.reshape(-1)
shifts = np.stack((shift_x, shift_y, shift_x, shift_y), axis=1)
anchors = shifts.reshape((-1, 1, 4)) + base_anchors.reshape((1, -1, 4))
return torch.tensor(anchors, dtype=torch.float32).view(1, -1, 4)
# 显示
def show_bboxes(axes, bboxes, labels=None, colors=None):
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.detach().cpu().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center', fontsize=6, color=text_color,
bbox=dict(facecolor=color, lw=0)) 1.交并比(loU)
- 量化锚框与真实边界框的相似度:Jaccard系数(称为交并比loU),
def compute_intersection(set_1, set_2):
lower_bounds = torch.max(set_1[:, :2].unsqueeze(1), set_2[:, :2].unsqueeze(0)) # (n1, n2, 2)
upper_bounds = torch.min(set_1[:, 2:].unsqueeze(1), set_2[:, 2:].unsqueeze(0)) # (n1, n2, 2)
intersection_dims = torch.clamp(upper_bounds - lower_bounds, min=0) # (n1, n2, 2)
return intersection_dims[:, :, 0] * intersection_dims[:, :, 1] # (n1, n2)
def compute_jaccard(set_1, set_2):
intersection = compute_intersection(set_1, set_2)
areas_set_1 = (set_1[:, 2] - set_1[:, 0]) * (set_1[:, 3] - set_1[:, 1]) # (n1)
areas_set_2 = (set_2[:, 2] - set_2[:, 0]) * (set_2[:, 3] - set_2[:, 1]) # (n2)
union = areas_set_1.unsqueeze(1) + areas_set_2.unsqueeze(0) - intersection
return intersection / union 2.标注锚框
- 锚框需要有两类标签:锚框圈中目标的类别和锚框与真实边界框的偏移量。
- 通过锚框与不同类别的交并比的最大值来标注锚框,此外,将交并比未达设置的阈值的锚框标注为背景
- 若锚框
与被分配的真实边界框B的中心坐标为
,宽高为
,那么
的偏移量标注为
3.预测边界框
- 当锚框数量过多导致输出较多相似预测边界框时,可以使用非极大值抑制(NMS:non-maximum suppression)移除相似的预测边界框。
- 非极大值抑制:以置信度最高的预测边界框 (非背景)作为基准,移除所有与 的交并比大于设置的阈值的预测边界框。再以移除后置信度第二高的预测边界框 为基准,移除与 的交并比大于阈值的预测边界框,重复该过程直至所有与预测边界框都曾当过基准。
- 置信度:将预测边界框对于所有类别的预测概率中最大的概率作为置信度,该概率对应的类别即该边界框的预测类别。
图像风格迁移
样式迁移:将某图像中的样式应用在另一图像上。输入图像分为内容图像和样式图像。
- 过程:首先初始化合成图像为内容图像,合成图像即需要迭代的模型参数。
- 用训练好的卷积神经网络抽取图像特征,利用某些层的输出作为内容特征或样式特征。
一般情况下,靠近输入层的输出更容易抽取细节,反之更容易抽取全局信息,所以将靠近输出的层用作内容层,其他选择不同层输出作为样式层。
样式迁移的损失函数由内容损失、样式损失和总变差损失组成,是这三者的加权和。
- 内容损失:合成图像与内容图像的平方误差
- 样式损失:平
在这里插入代码片方误差,用Gram矩阵表现不同通道上样式特征的相关性。 - 总变差损失:通过降低总变差损失可以减少高频噪点。
GAN(Generative Adversarial Networks)
机器学习可以进行区别性任务(discriminative learning),也可以进行生成式建模(generative modeling)。深度神经网络为识别学习开辟了新的可能性,如递归神经网络训练后可以作为生成模型
- discriminative learning:从数据点到标签的映射,如分类器和回归器。
- generative modeling:给定一个庞大的数据集,无标签,可以学习一个能够精确捕获数据特征的模型,从而通过模型可以生成一个相似的合成数据。
2014年,一篇论文介绍了一个新模型:生成式对抗网络(GANs),它利用识别模型来获得效果良好的生成模型。其核心思想是:如果我们不能分辨出真实数据和生成的数据,那么这个生成模型就是好的。
- 检验方法:统计学的双样本检验。通过检验真实数据集和生成数据集是否来自于一个分布来判断是否能分辨出两者。根据这一检验方法,GAN改进生成模型,直到欺骗分类器到认为两者来自于一个数据集。
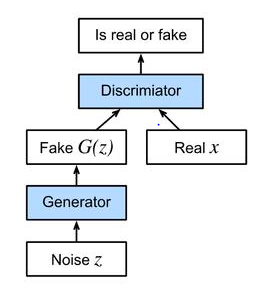
GAN 结构如图所示,首先由一个生成器网络生成一些类似于真实数据的数据(或是图像、语音等)。再经过一个判别器网络对真实数据和生成数据进行区分,此时,判别器在视图辨别真伪,生成器在视图欺骗,两者相互竞争。
- 判别器是一个二分类器,区分输入是true(来自真实数据: )还是false(来自生成器: )。一般情况下,判别器输出一个标量预测 ,再利用sigmoid函数得到预测概率 。得到判别器的交叉熵损失函数:
- 对于生成器,先从某个分布(如正态分布)随机生成一些参数 ,通过一个函数得到生成值 。因为生成器的目标是欺骗判别器,所以生成器要根据给定的判别器更新生成器的参数,使其在 时的交叉熵损失最大,即
- 若判别器能清楚分辨两者区别,那么 ,上面的损失函数也接近于0,造成梯度太小,不能很好的更新生成器。所以在将 输入到判别器中而给出标签为 时需要尽量减小下面的损失:
- 综上,生成器和判别器的综合式为:
DCGAN(Deep Convolutional Generative Adversarial Networks)
2015年提出了GAN的升级版本:DCGAN,深层卷积生成对抗网络。它将借用卷积网络的结构,将GAN更深层的运用在一些问题上。尤其是在计算机视觉识别问题上,DCGAN非常成功。
