CUDA学习笔记(1)——简介
必备工具:
NVIDIA显卡
CUDA编译器NVCC
windwos可去NVIDIA官网下载
linux(测试为manjiaro)
sudo pacman -Ss cuda //查找
sudo pacman -S //安装
简介:
CUDA,Compute Unified Device Architecture的简称,是由NVIDIA公司创立的基于他们公司生产的图形处理器GPUs(Graphics Processing Units,可以通俗的理解为显卡)的一个并行计算平台和编程模型。
CPU和GPU:
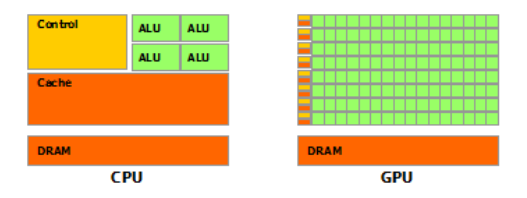
GPU(图像处理器,Graphics Processing Unit):更多的运算单元(图中绿色的ALU),而Control和Cache单元不如CPU多,因为GPU在进行并行计算的时候每个运算单元都是执行相同的程序,不需要太多的控制。
CPU(中央处理器,Central Processing Unit):Cache单元用来做数据缓存,CPU可以通过Cache来减少存取主内存的次数,也就是减少内存延迟(memory latency)。
GPU中Cache很小或者没有,因为GPU可以通过并行计算的方式来减少内存延迟。CPU的Cahce设计主要是实现低延迟,Control主要是通用性,复杂的逻辑控制单元可以保证CPU高效分发任务和指令。所以CPU擅长逻辑控制,是串行计算,而GPU擅长高强度计算,是并行计算。
通过CUDA,GPU可以很方便地被用来进行通用计算。在没有CUDA之前,GPU一般只用来进行图形渲染。
GPU更适用于计算强度高,多并行的计算中。
使用显示芯片来进行运算工作,和使用 CPU 相比,主要有几个好处:
(1)显示芯片通常具有更大的内存带宽。例如,NVIDIA 的 GeForce 8800GTX 具有超过50GB/s 的内存带宽,而目前高阶 CPU 的内存带宽则在 10GB/s 左右。
(2)显示芯片具有更大量的执行单元。例如 GeForce 8800GTX 具有 128 个 “stream processors”,频率为 1.35GHz。CPU 频率通常较高,但是执行单元的数目则要少得多。
(3)和高阶 CPU 相比,显卡的价格较为低廉。例如一张 GeForce 8800GT 包括512MB 内存的价格,和一颗 2.4GHz 四核心 CPU 的价格相若。
CUDA在NVIDIA的GPU上运行,而且只有当要解决的计算问题是可以大量并行计算的时候才能发挥CUDA的作用。
术语:
Host:CPU and its memory (host memory)
Device: GPU and its memory (device memory)
代码中,一般用h_前缀表示host memory,d_表示device memory。
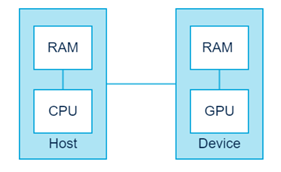
CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 “kernel”。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
CPU 存取显卡内存时只能透过 PCI Express 接口,因此速度较慢(PCI Express x16 的理论带宽是双向各 4GB/s),因此不能太常进行这类动作,以免降低效率
kernel是CUDA编程中的关键,它是跑在GPU的代码,用标示符__global__注明。
当一个kernel启动后,控制权会立刻返还给CPU来执行其他额外的任务。所以,CUDA编程是异步的。一个典型的CUDA程序包含由并行代码补足的串行代码,串行代码由host执行,并行代码在device中执行。host端代码是标准C,device是CUDA C代码。NVIDIA C编译器(nvcc)可以编译host和device生成可执行程序。
CUDA程序的处理流程:
(1)从CPU拷贝数据到GPU。
(2)调用kernel来操作存储在GPU的数据。
(3)将操作结果从GPU拷贝至CPU。
Memory操作:
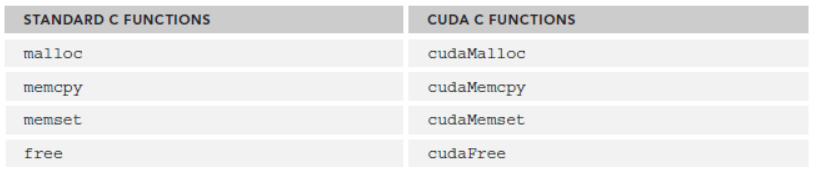
cuda程序将系统区分成host和device,二者有各自的memory。kernel可以操作device memory,为了能很好的控制device端内存,CUDA提供了几个内存操作函数:
CUDA C 的风格跟C很接近,比如 cudaError_t cudaMalloc ( void** devPtr, size_t size )
看cudaMencpy函数,其函数原型为:
cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count,cudaMemcpyKind kind )
其中cudaMemcpykind的可选类型有:
(1)cudaMemcpyHostToHost
(2)cudaMemcpyHossToDevice
(3)cudaMemcpyDeviceToHost
(4)cudaMemcpuDeviceToDevice
CUDA架构:(thread-block-grid)
CUDA线程分成Grid和Block两个层次,CUDA 架构下,显示芯片执行时的最小单位是thread。数个 thread 可以组成一个block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。
每一个 block 所能包含的 thread 数目是有限的。不过,执行相同程序的 block,可以组成grid。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
执行方式:
由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般 CPU 是不同的。主要的特点包括:
(1)内存存取 latency 的问题:CPU 通常使用 cache 来减少存取主内存的次数,以避免内存 latency 影响到执行效率。显示芯片则多半没有 cache(或很小),而利用并行化执行的方式来隐藏内存的 latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个 thread,依此类推)。
(2)分支指令的问题:CPU 通常利用分支预测等方式来减少分支指令造成的 pipeline bubble。显示芯片则多半使用类似处理内存 latency 的方式。不过,通常显示芯片处理分支的效率会比较差。
因此,最适合利用 CUDA 处理的问题,是可以大量并行化的问题,才能有效隐藏内存的latency,并有效利用显示芯片上的大量执行单元。使用 CUDA 时,同时有上千个 thread 在执行是很正常的。因此,如果不能大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。
主要概念与名称
线程(Thread)
一般通过GPU的一个核进行处理。(可以表示成一维,二维,三维)。
线程块(Block)
(1)由多个线程组成(一维,二维,三维)。
(2)各block是并行执行的,block间无法通信,也没有执行顺序。
(3)注意线程块的数量限制为不超过65535(硬件限制)。
线程格(Grid)
由多个线程块组成(一维,二维,三维)

Kernel上的两层线程组织结构(2-dim)
要深刻理解kernel,必须要对kernel的线程层次结构有一个清晰的认识。首先GPU上很多并行化的轻量级线程。kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。线程两层组织结构如上图所示,这是一个gird和block均为2-dim的线程组织。grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执行配置<<<grid, block>>>来指定kernel所使用的线程数及结构。
一个grid由许多block组成,block由许多Thread(线程)组成,grid和block都可以是一维二维或者三维,上图是一个二维grid和二维block。
几个CUDA内置变量:
threadIdx,获取线程thread的ID索引;如果线程是一维的那么就取threadIdx.x,二维的还可以多取到一个值threadIdx.y,以此类推到三维threadIdx.z。
blockIdx,线程块的ID索引;同样有blockIdx.x,blockIdx.y,blockIdx.z。
blockDim,线程块(block)的维度,同样有blockDim.x,blockDim.y,blockDim.z。
gridDim,线程格(grid)的维度,同样有gridDim.x,gridDim.y,gridDim.z。
一般会把grid组织成2D,block为3D。grid和block都使用dim3作为声明
dim3 block(3);
dim3 grid((nElem+block.x-1)/block.x);
dim3仅为host端可见,其对应的device端类型为uint3。
dim3结构类型
1. dim3是基于uint3定义的矢量类型,相当于由3个unsigned int型组成的结构体。uint3类 型有三个数据成员unsigned int x; unsigned int y; unsigned int z;
2. 可使用一维、二维或三维的索引来标识线程,构成一维、二维或三维线程块。
3. dim3结构类型变量用在核函数调用的<<<,>>>中。
4. 对于一维的block,线程的threadID=threadIdx.x。
5. 对于大小为(blockDim.x, blockDim.y)的 二维 block,线程的threadID=threadIdx.x+threadIdx.yblockDim.x。
6. 对于大小为(blockDim.x, blockDim.y, blockDim.z)的 三维 block,线程的threadID=threadIdx.x+threadIdx.yblockDim.x+threadIdx.zblockDim.xblockDim.y。
7. 对于计算线程索引偏移增量为已启动线程的总数。如stride = blockDim.x * gridDim.x; threadId += stride。
CUDA kernel
CUDA kernel的调用格式为:
kernel_name<<<grid, block>>>(argument list);
其中grid和block即为上文中介绍的类型为dim3的变量。通过这两个变量可以配置一个kernel的线程总和,以及线程的组织形式。例如:
kernel_name<<<4, 8>>>(argumentt list);
该行代码表明有grid为一维,有4个block,block为一维,每个block有8个线程,故此共有4*8=32个线程。

不同于c函数的调用,所有CUDA kernel的启动都是异步的,当CUDA kernel被调用时,控制权会立即返回给CPU。
核函数(Kernel)
1. 在GPU上执行的函数通常称为核函数。
2. 一般通过标识符__global__修饰,调用通过<<<参数1,参数2>>>,用于说明内核函数中的线程数量,以及线程是如何组织的。
3. 以线程格(Grid)的形式组织,每个线程格由若干个线程块(block)组成,而每个线程块又由若干个线程(thread)组成。
4. 是以block为单位执行的。
5. 叧能在主机端代码中调用。
6. 调用时必须声明内核函数的执行参数。
7. 在编程时,必须先为kernel函数中用到的数组或变量分配好足够的空间,再调用kernel函数,否则在GPU计算时会发生错误,例如越界或报错,甚至导致蓝屏和死机。
函数类型标示符

__device__和__host__可以组合使用。
kernel的限制:
(1)仅能获取device memory 。
(2)必须返回void类型。
(3)不支持可变数目参数。
(4)不支持静态变量。
(5)不支持函数指针。
(6)异步。
有“global”或者“device”前缀的函数,都是在GPU上运行的设备程序,不同的是__global__设备程序可被主机程序调用,而__device__设备程序则只能被设备程序调用。
常用的GPU内存函数
cudaMalloc()
(1)函数原型: cudaError_t cudaMalloc (void **devPtr, size_t size)。
(2)函数用处:与C语言中的malloc函数一样,只是此函数在GPU的内存你分配内存。
(3)注意事项:
可以将cudaMalloc()分配的指针传递给在设备上执行的函数;
可以在设备代码中使用cudaMalloc()分配的指针进行设备内存读写操作;
可以将cudaMalloc()分配的指针传递给在主机上执行的函数;
不可以在主机代码中使用cudaMalloc()分配的指针进行主机内存读写操作(即不能进行解引用)。
cudaMemcpy()
(1)函数原型:cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)。
(2)函数作用:与c语言中的memcpy函数一样,只是此函数可以在主机内存和GPU内存之间互相拷贝数据。
(3)函数参数:cudaMemcpyKind kind表示数据拷贝方向,如果kind赋值为cudaMemcpyDeviceToHost表示数据从设备内存拷贝到主机内存。
(4)与C中的memcpy()一样,以同步方式执行,即当函数返回时,复制操作就已经完成了,并且在输出缓冲区中包含了复制进去的内容。
(5)相应的有个异步方式执行的函数cudaMemcpyAsync(),这个函数详解请看下面的流一节有关内容。
cudaFree()
(1)函数原型:cudaError_t cudaFree ( void* devPtr )。
(2)函数作用:与c语言中的free()函数一样,只是此函数释放的是cudaMalloc()分配的内存。
代码示例
#include <stdio.h>
#include <cuda_runtime.h>
__global__ void add( int a, int b, int *c ) {
*c = a + b;
}
int main( void ) {
int c;
int *dev_c;
//cudaMalloc()
cudaMalloc( (void**)&dev_c, sizeof(int) );
//核函数执行
add<<<1,1>>>( 2, 7, dev_c );
//cudaMemcpy()
cudaMemcpy( &c, dev_c, sizeof(int),cudaMemcpyDeviceToHost ) ;
printf( "2 + 7 = %d\n", c );
//cudaFree()
cudaFree( dev_c );
return 0;
}
