一、影响执行效率的因数
1、超大数据量
2、中文检索
3、数据库的系统配置
二、查看执行效率方法
通过简单分析执行计划
1、找到消耗资源最多的点
2、减少全表扫table_access
3、走索引
三、sql执行的步骤
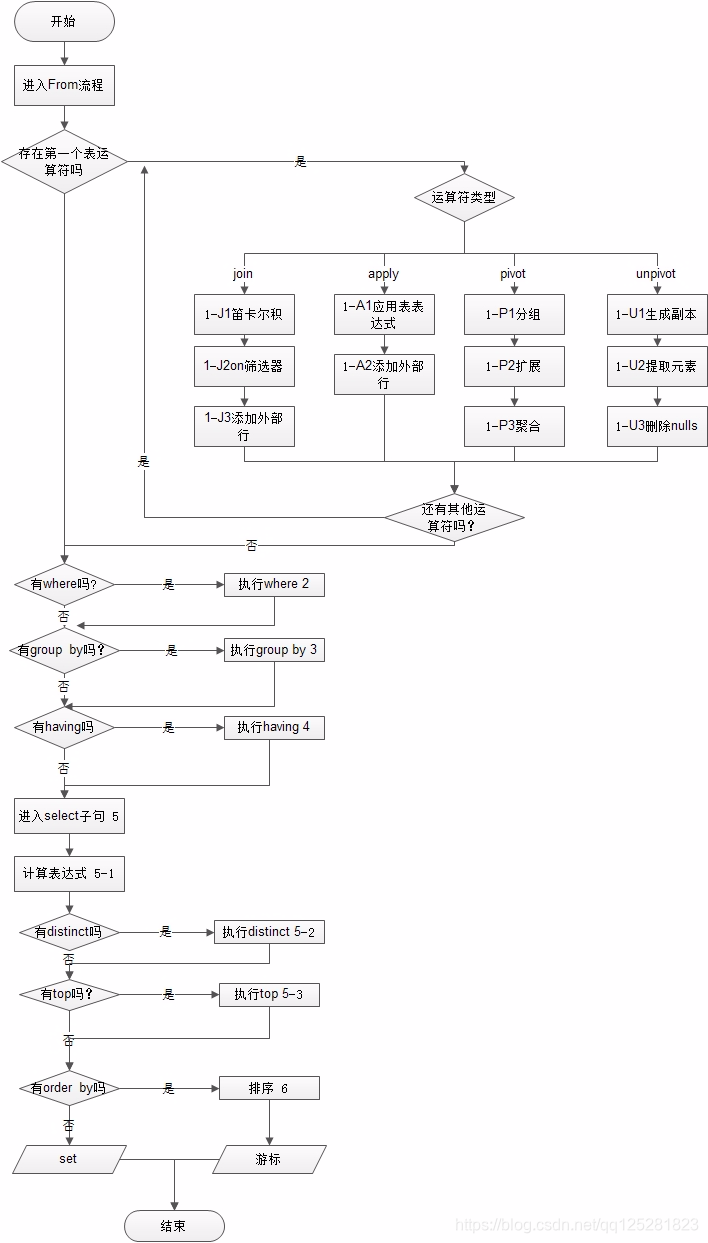
/*
顺序为有1-6,6个大步骤,然后细分,5-1,5-2,5-3,由小变大顺序,1-J,1-A,1-P,1-U,为并行次序
*/
--查询组合字段
(5)select (5-2) distinct(5-3) top(<top_specification>)(5-1)<select_list>
--连表
(1)from (1-J)<left_table><join_type> join <right_table> on <on_predicate>
(1-A)<left_table><apply_type> apply <right_table_expression> as <alias>
(1-P)<left_table> pivot (<pivot_specification>) as <alias>
(1-U)<left_table> unpivot (<unpivot_specification>) as <alias>
--查询条件
(2)where <where_pridicate>
--分组
(3)group by <group_by_specification>
--分组条件
(4)having<having_predicate>
--排序
(6)order by<order_by_list>
四、优化策略
1、抽取中间表,减少数据量
2、提前任务量,有一些计算和统计任务提前做
3、尽量避免在where条件中执行函数(任何函数)过虑
4、表关联条件走索引
5、尽量避免where条件中循环嵌套的出现
6、有条件减少数据量再进行表连接
五、优化措施
1、选择记录数量最少的表作为驱动表,from 是从前往后检索的,所以要最少记录的表放在最前面
2、WHERE子句采用由后而前的顺序检索,根据这个原理,表之间的连接必须写在其他WHERE条件之前, 那些
可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾,同时在链接的表中能过滤的就应该先进行过滤
3、SELECT子句中避免使用 ‘ * ‘
4、用Where子句替换HAVING子句
5、使用表的别名
6、用EXISTS替代IN,NOT EXISTS替代NOT IN
7、用表连接替换EXISTS
8、避免在索引列上使用计算,因为在索引列上计算会导致索引失效
9、避免在索引列上使用NOT(在索引列使用not会导致索引失效)
10、用UNION,IN替换OR ;UNION-ALL 替换UNION
11、注意组合索引,使用索引的第一列
12、避免在索引列上使用IS NULL和IS NOT NULL
13、ORDER BY 子句只在两种严格的条件下使用索引.
14、避免改变索引列的类型
15、避免使用耗费资源的操作(带有DISTINCT,UNION,MINUS,INTERSECT,ORDER BY)
案例:
1、IS NULL 与 IS NOT NULL
不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列这样的情况下,只要这些列中有一列含有null,该列就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。
任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
2、’!=’ 将不使用索引. 记住, 索引只能告诉你什么存在于表中, 而不能告诉你什么不存在于表中
不使用索引: select * from employee where salary<>3000;
使用索引: select account_name from transaction where amount >0;
使用索引: select * from employee where salary<3000 or salary>3000;
3、联接列,’||‘是字符连接函数. 就象其他函数那样, 停用了索引
不使用索引: select account_name,amount from transaction where account_name||account_type=‘AMEXA’;
使用索引: select account_name,amount from transaction where account_name = ‘AMEX’ and account_type=’ A’;
4、’+'是数学函数. 就象其他数学函数那样, 停用了索引
不使用索引: select account_name, amount from transaction where amount + 3000 >5000;
使用索引: select account_name, amount from transaction where amount > 2000 ;
5、相同的索引列不能互相比较,这将会启用全表扫描
不使用索引: select account_name, amount from transaction where account_name = nvl(:acc_name,account_name);
使用索引: select account_name, amount from transaction where account_name like nvl(:acc_name,’%’);
6、带通配符(%)的like语句
不使用索引: select * from employee where last_name like ‘%cliton%’;
使用索引: select * from employee where last_name like ‘c%’

7、IN和EXISTS
不使用索引: … where column in(select * from … where …);
使用索引: … where exists (select ‘X’ from …where …);
同时应尽可能使用NOT EXISTS来代替NOT IN,尽管二者都使用了NOT(不能使用索引而降低速度),NOT EXISTS要比NOT IN查询效率更高。
