1.缓存的收益和成本
1.收益 加速读写 cpu l1,l2,l3 cache,linux page cache加锁硬盘读写,浏览器缓存mehcache缓存数据库结果 降低后端负载端 后端服务器通过前端缓存降低负载:业务端使用redis降低后端mysql负载 2.成本 数据不一致 缓存层和数据层有时间窗口不一致,和更新策略有关(数据库更新了,但是缓存层没有更新) 代码维护成本变高了 多了一层缓存逻辑 运维成本 例如redis cluster 3.使用场景 降低后端负载 对高消耗的sql:join结果集/分组统计结果优化 加速请求响应 利用redis/memcachey优化io响应时间 大量写合并成批量写 如计数器先redis累加在批量写
2.缓存更细策略
1.lru/lfu/fifo算法剔除 例如:maxmemory-policy(最大内存对应策略) # mysql的缓冲区也是使用的lru列表的算法来切换冷数据和热数据 2.超时剔除 例如:expire 3.主动更新 开发控制生命周期,达到最终一致性
两条建议
1.低一致性:
最大内存淘汰策略
2.高一致性
超时剔除和主动更新结合,最大内存和淘汰策略兜底

3.缓存的粒度控制
1.通用性 全量属性更好 2.占用空间 部分属性更好 3.代码维护上 表面上全量属性最好(按照缓存数据来分,要综合考虑)
4.缓存穿透问题
缓存穿透
现象:大量请求不命中(cache不存在数据或者存储层不存在真实的数据)
缺点:
cahce层对存储层的保护作用消失了,因为每次访问都需要走redis在走存储层,浪费性能。
产生原因:
1.业务代码字自身问题
2.恶意攻击或者爬虫(会导致redis数据进行更新)
如何发现
1.业务响应时间
2.业务本身问题
3.监控redis集群:总调用树,缓存层中命中数,存储层命中数
解决办法(1) 1.缓存空对象 在数据库层真的没有对应数据的话,就直接在redis里面设置空对象。缓解对存储曾带来的危害

2.缓存空对象的问题
1.需要更多的键
2.缓存层和存储层数据的"短期"不一致
3.缓存空对象代码实现

解决办法(2)
1.布隆过滤器拦截
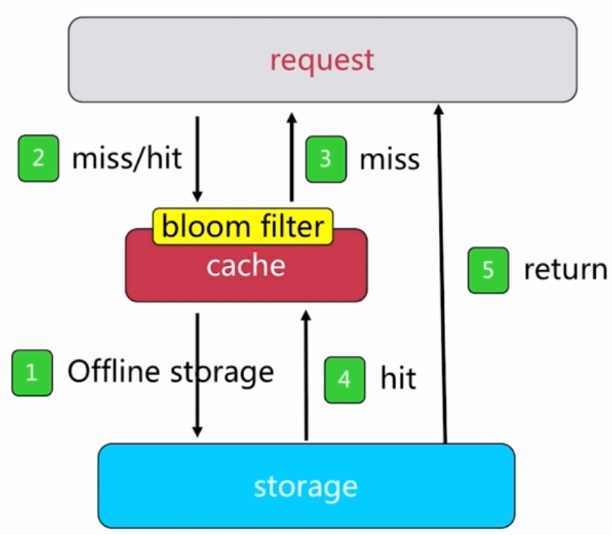
缓存穿透案例
案例一
5.缓存无底洞问题
6.缓存雪崩的问题
7.热点key重建优化