概述
以任务为例,如果我们需要进行分表,需要关注两点
1.数据增长量,决定了分表数量
2.查询以及数据更新场景,决定了按那种方式分表
数据分析
1. 表结构
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | long | 主键 |
| student_id | long | 学生id |
| teacher_id | long | 教师id |
| task_name | varchar | 任务名称 |
| create_time | datetiem | 创建时间 |
| … | … | … |
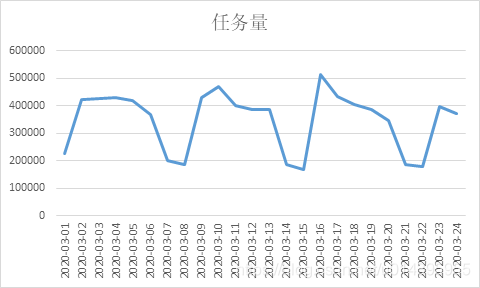
2. 日任务量
均值:347348
| 日期 | 任务量 | 日期 | 任务量 |
|---|---|---|---|
| 2020-03-01 | 225925 | 2020-03-13 | 387824 |
| 2020-03-02 | 424014 | 2020-03-14 | 184733 |
| 2020-03-03 | 428069 | 2020-03-15 | 168003 |
| 2020-03-04 | 428821 | 2020-03-16 | 515914 |
| 2020-03-05 | 420984 | 2020-03-17 | 434955 |
| 2020-03-06 | 367536 | 2020-03-18 | 406467 |
| 2020-03-07 | 202577 | 2020-03-19 | 385732 |
| 2020-03-08 | 184836 | 2020-03-20 | 347008 |
| 2020-03-09 | 430492 | 2020-03-21 | 186037 |
| 2020-03-10 | 471406 | 2020-03-22 | 179031 |
| 2020-03-11 | 401931 | 2020-03-23 | 396231 |
| 2020-03-12 | 387274 | 2020-03-24 | 370556 |
3.月任务量
月均任务数:7901876
| 月份 | 任务量 |
|---|---|
| 2019年10月 | 5971953 |
| 2019年11月 | 7248057 |
| 2019年12月 | 9418330 |
| 2020年1月 | 5297569 |
| 2020年2月 | 10926496 |
| 2020年3月 | 8548852 |

4.月活用户
月活用户:225534
用户月均任务:35
| 月份 | 活跃用户数 | 月增长量 | 用户平均增长量 |
|---|---|---|---|
| 2019-10 | 193368 | 5971953 | 31 |
| 2019-11 | 214237 | 7248057 | 34 |
| 2019-12 | 255763 | 9418330 | 37 |
| 2020-01 | 199287 | 5297569 | 27 |
| 2020-02 | 262315 | 10926496 | 42 |
| 2020-03 | 228235 | 8779162 | 38 |
场景分析
经过与产品确认,该表涉及的场景如下
教师端
1.教师布置任务
2.教师撤销任务
3.教师查看任务完成情况
学生端
1.学生查看任务列表
2.学生完成任务
通过使用场景可以看到对表的操作都可以获取到当前登录用户,显而易见根据用户id取模或者范围分表,但是用户id落到我们的任务表中确是两个字段(student_id,teacher_id),考虑到任务数据的高度聚合性,我们根据学校id分组。表中目前不存在学校id,所以需要教师端和学生端操作该表时根据当前用户获取到所属学校id,由于用户对应school_id相对不变,可以进行redis缓存,添加学校id对性能影响微乎其微。
