目录
搞了一天终于知道目标检测精确度是个什么东西,以及如何测试,代码如何操作(附代码)
写篇笔记记录一下!!
本文参考了以下大佬的博客进行整合和加上个人观点,感兴趣的可以看看哦:
https://blog.csdn.net/weixin_44791964/article/details/104695264
https://blog.csdn.net/plSong_CSDN/article/details/85194719
https://blog.csdn.net/weixin_41243159/article/details/103748428
知识储备
1、IOU的概念
IOU的概念应该比较简单,就是衡量预测框和真实框的重合程度。下图是一个示例:图中绿色框为实际框(好像不是很绿……),红色框为预测框,当我们需要判断两个框之间的关系时,主要就是判断两个框的重合程度。

计算IOU的公式为:
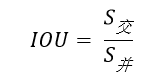
可以看到IOU是一个比值,即交并比。
在分子部分,值为预测框和实际框之间的重叠区域;
在分母部分,值为预测框和实际框所占有的总区域。
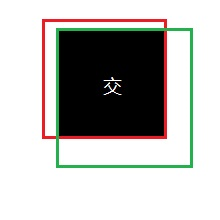

交区域和并区域的比值,就是IOU。
2、TP TN FP FN的概念
TP TN FP FN里面一共出现了4个字母,分别是T F P N。
T是True;
F是False;
P是Positive;
N是Negative。
T或者F代表的是该样本 是否被正确分类。
P或者N代表的是该样本 原本是正样本还是负样本。
TP(True Positives)意思就是被分为了正样本,而且分对了。
TN(True Negatives)意思就是被分为了负样本,而且分对了,
FP(False Positives)意思就是被分为了正样本,但是分错了(事实上这个样本是负样本)。
FN(False Negatives)意思就是被分为了负样本,但是分错了(事实上这个样本是正样本)。
在mAP计算的过程中主要用到了,TP、FP、FN这三个概念。
3、precision(精确度)和recall(召回率)
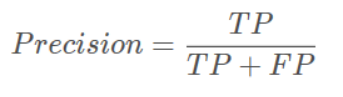
TP是分类器认为是正样本而且确实是正样本的例子,FP是分类器认为是正样本但实际上不是正样本的例子,Precision翻译成中文就是“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”。
即精确度是正样本中真正是正样本的比例。
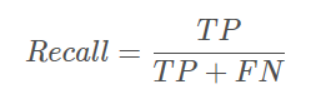
TP是分类器认为是正样本而且确实是正样本的例子,FN是分类器认为是负样本但实际上不是负样本的例子,Recall翻译成中文就是**“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”**。
即召回率是正样本中被认为是正样本的比例。
4、概念举例

如图所示,蓝色的框是 真实框。绿色和红色的框是 预测框,绿色的框是正样本(预测框跟实际框重合程度高),红色的框是负样本(预测框跟实际框重合程度低)。
一般来讲,当预测框和真实框IOU>=0.5(即把置信度设置为0.5)时,被认为是正样本。
因此对于这幅图来讲。真实框一共有3个,正样本一共有2个,负样本一共有2个。
此时

5、单个指标的局限性
在目标检测算法里面有一个非常重要的概念是置信度,如果(Confidence)置信度设置的高的话,预测的结果和实际情况就很符合,如果置信度低的话,就会有很多误检测。
假设一幅图里面总共有3个正样本,目标检测对这幅图的预测结果有10个,其中3个实际上是正样本,7个实际上是负样本。对应置信度如下。
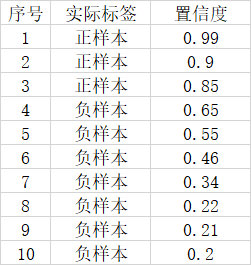
如果我们将可以接受的置信度设置为0.95的话,那么目标检测算法就会将序号为1的样本作为正样本,其它的都是负样本。此时TP = 1,FP = 0,FN = 2。

此时Precision非常高,但是事实上我们只检测出一个正样本,还有两个没有检测出来,因此只用Precision就不合适。
这个时候如果我们将可以接受的置信度设置为0.35的话,那么目标检测算法就会将序号为1的样本作为正样本,其它的都是负样本。此时TP = 3,FP = 3,FN = 0。

此时Recall非常高,但是事实上目标检测算法认为是正样本的样本里面,有3个样本确实是正样本,但有三个是负样本,存在非常严重的误检测,因此只用Recall就不合适。
二者进行结合才是评价的正确方法。
什么是AP
单纯用 precision 和 recall 都不科学。于是人们想到,哎嘛为何不把 PR曲线下的面积 当做衡量尺度呢?于是就有了 AP值 这一概念。这里的 average,等于是对 precision 进行 取平均 。AP事实上指的是,利用不同的Precision和Recall的点的组合,画出来的曲线下面的面积。
如下面这幅图所示。

当我们取不同的置信度,可以获得不同的Precision和不同的Recall,
当我们取得置信度够密集的时候,就可以获得非常多的Precision和Recall。
此时Precision和Recall可以在图片上画出一条线,这条线下部分的面积就是某个类的AP值。
什么是MAP
Mean Average Precision,即平均AP值 。
mAP就是所有的类的AP值求平均。
是对多个验证集个体求平均AP值。如下图:

作为 object dection 中衡量检测精度的指标。计算公式为:mAP =所有类别的平均精度求和除以所有类别。
AP衡量的是学出来的模型在每个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏,得到AP后mAP的计算就变得很简单了,就是取所有AP的平均值。
绘制mAP
主要分为下面几个部分
(1)准备文件
YOLOV3keras实现地址:https://github.com/qqwweee/keras-yolo3
训练好自己的权重文件(.h5),
将其放入\model_data
新建test文件夹,将测试图片放入
测试并将测试结果保存下来(yolo_test.py),改coco_classes.txt为自己训练的类别
(2)准备计算MAP需要detection-results,ground-truth、images-optional
(3)运行main.py即可(mAP项目)
1 下载mAP压缩包
下载地址 mAP代码下载https://github.com/Cartucho/mAP
若要计算自己的数据,可以把压缩包里mAP-master/input下的三个文件夹(detection_results, ground_truth, images-optional)里的内容清空,以便后续放入自己的数据。(如果不清空,新的数据会加到文件夹里,原来的数据不会被覆盖)
实现mAP的计算主要就是把相应的文件放入到 detection_results, ground_truth, images-optional 这三个文件夹中,然后根据压缩包里的main.py 文件直接生成结果。
2 images-optional文件夹
先从最简单的开始吧,images-optional文件夹主要是放你要测试(test)的图像数据的。
第一种方法是,你只需要把你准备的测试图片粘进去
(这里我准备了188张检测口罩的测试图片)
第二种方法是,你可以在main.py 文件中把IMG_PATH的路径引到放测试图片的文件夹。下面是main.py 文件中的部分代码,修改即可。
GT_PATH = os.path.join(os.getcwd(), 'input', 'ground-truth')
DR_PATH = os.path.join(os.getcwd(), 'input', 'detection-results')
# if there are no images then no animation can be shown
# IMG_PATH = os.path.join(os.getcwd(), 'input', 'images-optional') 默认是images-optionalIMG_PATH = '/home/bu807/Downloads/keras-yolo3-master2/keras-yolo3-master2/test'
#也可以引到自己的test路径粘完图片,或者改完路径后,images-optional文件夹就搞定了。最简单。
3 ground_truth文件夹
ground_truth用来放真实值,就是你当初标的框的位置大小,如下:一张图里,眼睛 鼻子 嘴巴 的类型、位置和大小。
格式是:classname left top right bottom
eye 86 274 146 305
eye 214 273 282 303
nose 138 334 220 385
mouth 139 404 220 437这里需要放入原始值的txt文件,我们可以根据xml文件生成。首先,需要将xml导入到ground_truth文件夹;然后,通过covert_gt_xml.py转成txt文件。
3.1 将xml导入到ground_truth文件夹
第一种方法,你的测试图片少的话,可以直接把相应的xml文件粘到ground_truth文件夹。
第二种方法,你的测试图片很多/一个一个找不好找,原博主简单写了一个代码(如下:findxml.py,你可以把它放在mAP-master/scripts/extra下 ),可以从你的Annotations文件夹中找到相应的xml文件,然后粘到ground_truth文件夹。
import os
import shutil
testfilepath='/home/bu807/Downloads/keras-yolo3-master2/keras-yolo3-master2/test'
xmlfilepath = '/home/bu807/Downloads/keras-yolo3-master2/keras-yolo3-master2/VOCdevkit/VOC2007/Annotations/'
xmlsavepath = '/home/bu807/Downloads/keras-yolo3-master2/keras-yolo3-master2/mAP-master/input/ground-truth/'
test_jpg = os.listdir(testfilepath)
num = len(test_jpg)
list = range(num)
L=[]
for i in list:
name = test_jpg[i][:-4] + '.xml' L.append(name)
for filename in L:
shutil.copy(os.path.join(xmlfilepath,filename),xmlsavepath)3.2 将xml转成txt文件
执行自带的mAP-master/scripts/extra/covert_gt_xml.py 文件。执行后,你的xml文件自动放进了ground_truth/backup中,然后在ground_truth下生成了txt文件。
4 detection-results文件夹
4.1 保存模型测试结果
采用yolo_test.py 文件(https://github.com/qqwweee/keras-yolo3),将该.py文件放入keras-yolo3工程下,可以实现批量测试并保存测试结果。
执行后会在主目录下生成result文件夹及下属文件。对其进行改进后,才能用于我们mAP的计算。
修改如下
1 )注释掉两个file.write
# 保存框检测出的框的个数
# file.write('find ' + str(len(out_boxes)) + ' target(s) \n') 这里注释掉
time_sum = time.time() - t1
# file.write('time sum: ' + str(time_sum) + 's') 这里注释掉
print('time sum:', time_sum)file.close()
yolo.close_session() 2)修改2个file.write
# 写入检测位置
# file.write(
# predicted_class + ' score: ' + str(score) + ' \nlocation: top: ' + str(top) + '、 bottom: ' + str(
# bottom) + '、 left: ' + str(left) + '、 right: ' + str(right) + '\n')
file.write( predicted_class + ' ' + str(score) + ' ' + str(left) + ' ' + str( top) + ' ' + str(right) + ' ' + str(bottom) + ';')
# file.write(portion[1] + ' detect_result:\n') 这个在最后
file.write(portion[1]+' ') # 这里要有一个空格 然后执行yolo_test.py,生成result/result.txt
**
4.2 执行py文件得到txt文件
原来的result.txt是把所有测试图片的预测结果写在一个文件里,这里将其分为一张图对应一个txt
新建了make_dr.py 文件,如下:
f=open('/home/bu807/Downloads/keras-yolo3-master2/keras-yolo3-master2/result/result.txt',encoding='utf8')
s=f.readlines()
result_path='/home/bu807/Downloads/keras-yolo3-master2/keras-yolo3-master2/mAP-master/input/detection-results/'
for i in range(len(s)): # 中按行存放的检测内容,为列表的形式
r = s[i].split('.jpg ')
file = open(result_path + r[0] + '.txt', 'w')
if len(r[1]) > 5:
t = r[1].split(';')
# print('len(t):',len(t))
if len(t) == 3:
file.write(t[0] + '\n' + t[1] + '\n') # 有两个对象被检测出
elif len(t) == 4:
file.write(t[0] + '\n' + t[1] + '\n' + t[2] + '\n') # 有三个对象被检测出
elif len(t) == 5:
file.write(t[0] + '\n' + t[1] + '\n' + t[2] + '\n' + t[3] + '\n') # 有四个对象被检测出
elif len(t) == 6:
file.write(t[0] + '\n' + t[1] + '\n' + t[2] + '\n' + t[3] + '\n' + t[4] + '\n') # 有五个对象被检测出
elif len(t) == 7:
file.write(t[0] + '\n' + t[1] + '\n' + t[2] + '\n' + t[3] + '\n' + t[4] + '\n' + t[5] + '\n') # 有六个对象被检测出
else:
file.write(t[0] + '\n') # 有一个对象
else:
file.write('') # 没有检测出来对象,创建一个空白的对象创建文件后执行,得到detection-results文件夹下的txt文件。将生成的txt文件复制到mAP工程中的对应位置。
到这里,三个文件夹就搞定了!大功告成!
5 执行 main.py 文件
最后,执行 main.py 文件,在mAP-master/results下就可以看到自己的mAP啦!!!
结果如下:

生成目录

标识出的测试框和真实框

Mask类的AP

NO类的AP

预测结果的正确和错误数目

真实结果

平均错误率

所有类的mAP值
