一.环境
JDK1.8+Sprinboot2.2+Spring5.x+RPC,微服务
二.问题描述
抛出的异常:
java.lang.OutOfMemoryError: GC overheadlimit exceeded
描述:这个异常是指超过98%的时间用来做GC并且回收 了不到2%的堆内存。
出现这个问题大概率是,某块代码长时间占用大块空间,最终导致频繁GC,服务崩了。
场景:配置服务通过yaml文件给其他服务提供配置数据,但是客户端服务的配置数据过大,导出时间长占用空间大导致问题。
三.问题分析
看到OutOfMemoryError,怎么定位到是哪块代码出问题?
1.这个问题的解决方案,网上有很多,通过在启动的时候加-XX:+PrintGCDetails参数,可以在控制台看到具体的代码信息。现在服务都有监控,我们看一下日志就可以定位到问题了。要谈经验的话,直接去看这个服务上操作文件有IO的地方。
2.如果本地能还原问题,就使用JDK自带的虚拟机工具查看,windows+R打开控制台 输入:jvisualvm
启动服务后,在图上“本地“菜单下中找到自己的服务,就可以打开监控页面了。
正常的服务监控状态是如图下:

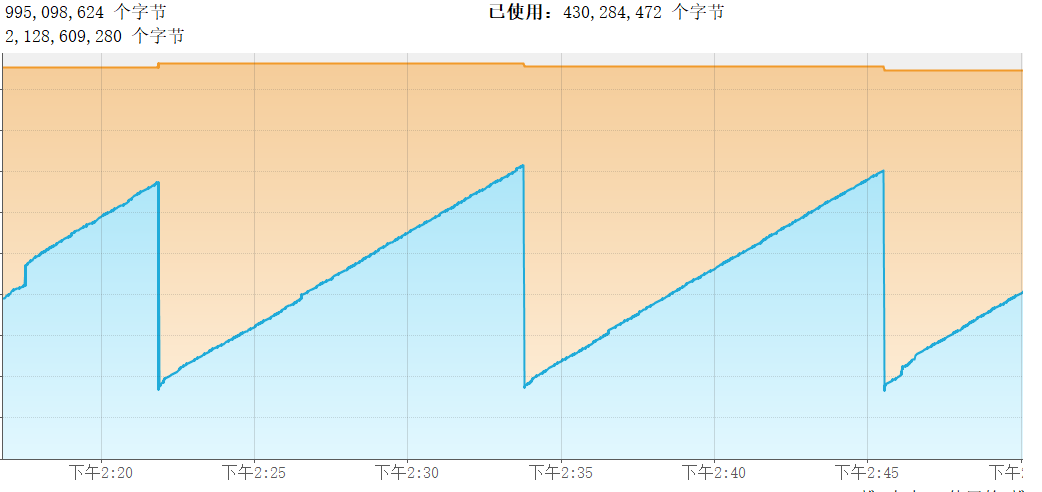
左边是程序CPU的使用率和GC操作的占CPU使用的比率,右边是堆内存的已使用和最大空间,蓝色块是已使用的空间大小,橙色块是未使用的
在还原OOM的操作后,你会明显感觉到堆空间和GC的不正常
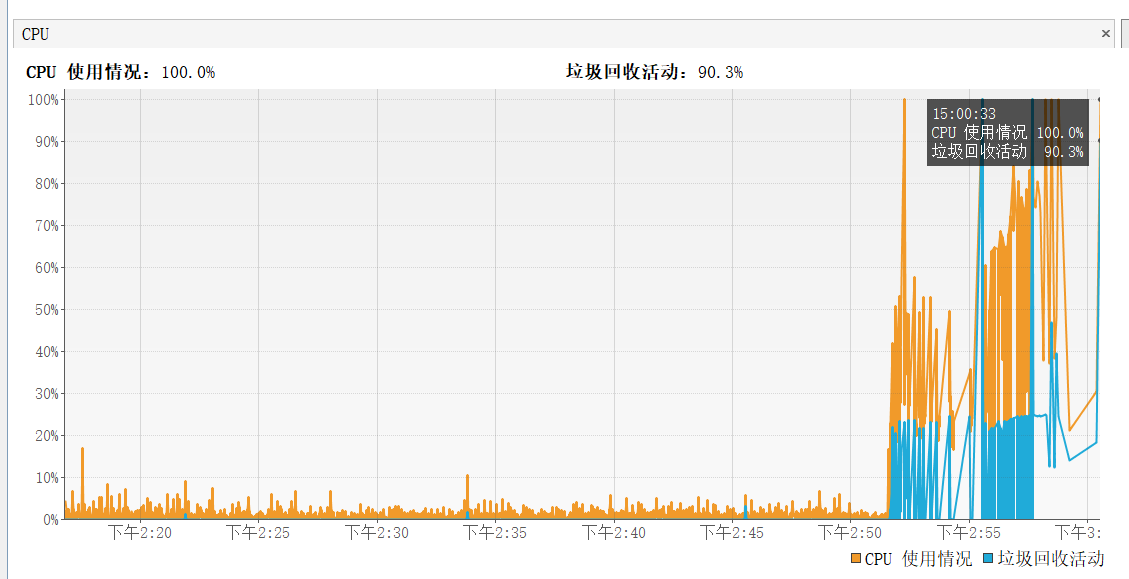

我是在下午2点52的时候开始操作一个35M大小的Yaml从A目录导出到B目录的过程
操作开始后,CPU开始飚升,内存膨胀也直接接近一个G了。明明就一个35M的文件咋会膨胀这么多倍?
通过dump出当时的堆空间,我们去看是哪些对象撑爆了。
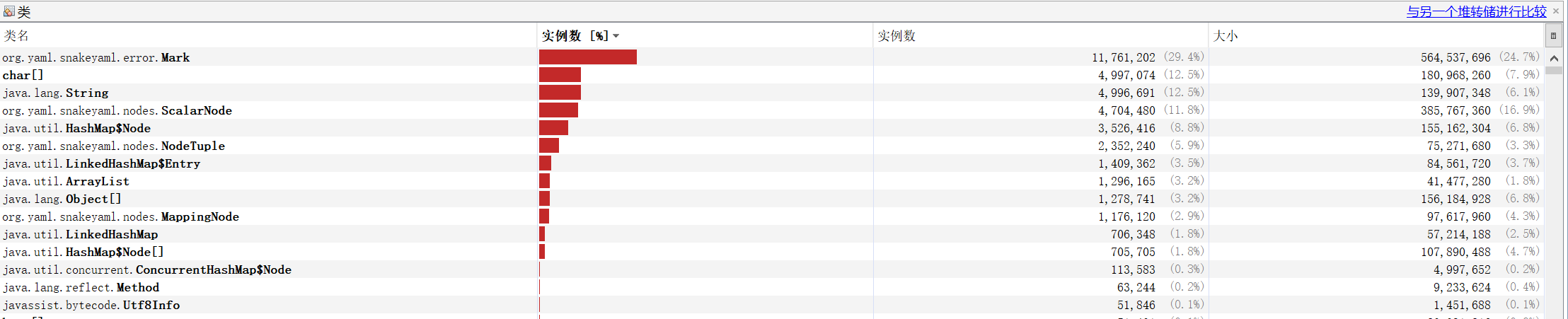
大部头都是来自snakeyaml中的节点对象,而且一个node对象对应两个Mark对象
public abstract class Node { private Tag tag; private Mark startMark; protected Mark endMark; private Class<? extends Object> type; private boolean twoStepsConstruction; private String anchor; }
下列是原代码,到此查看的代码知道了在dump的过程中,snakeyaml在读数据的过程中对每行记录创建一个node对象接收。产生了大量的node和mark对象没有释放,导致35M的数据膨胀到了近1G。
private int writeYamlToMfs(Object data, String savePath) throws Exception { long startTime = System.currentTimeMillis(); Yaml yaml = new Yaml(); String str = yaml.dump(data); logger.warn("yaml file's length {}", str.getBytes().length); Files.write(Paths.get(savePath), str.getBytes()); long endTime = System.currentTimeMillis(); logger.info("【{}】{}", savePath, (endTime - startTime)); return str.getBytes().length; }
这源于snakeyaml要对每行数据进行校验,判断是否符合格式,并对格式不对的数据哪行哪列进行提示。如果改成流的方式实现,不去校验数据,就不会有这个问题了。
下面就进行代码修改。
private int writeYamlToXX(FileInputStream fis, String savePath) throws Exception { long startTime = System.currentTimeMillis(); // Yaml yaml = new Yaml(); // String str = yaml.dump(data); FileOutputStream fos = new FileOutputStream(savePath); byte[] bytes = new byte[2048]; int temp = 0; int length = 0; try{ while((temp = fis.read(bytes)) != -1) { length+=temp; fos.write(bytes, 0, temp); fos.flush(); } }catch (Exception e){ logger.error("导出写入到xxxs的时候失败,{}",savePath,e); }finally { fis.close(); fos.close(); } logger.warn("yaml file's length {}", length); // Files.write(Paths.get(savePath), fis.); long endTime = System.currentTimeMillis(); logger.info("【{}】{}", savePath, (endTime - startTime)); return length; }
至此问题顺利解决了。
四.总结
看了一眼这个yaml的数据量,有一百万个了。其实这种数据就不适合使用Yaml了,当初设计这个文件内存缓存的时候,也就是给配置服务使用的,大多数的配置数据都是比较少的量的。
下一步改造的时候,这样数据量比较大的数据,要使用分页把100w分成每1w或者5000每次追加,然后立马释放这些数据的堆空间,保证堆不会撑爆。