消息的保存路径
消息发送端发送消息到 broker 上以后,消息是如何持久化的呢?那么接下来去分析下消息的存储,首先我们需要了解的是,kafka 是使用日志文件的方式来保存生产者和发送者的消息,每条消息都有一个 offset 值来表示它在分区中的偏移量。Kafka 中存储的一般都是海量的消息数据,为了避免日志文件过大,Log 并不是直接对应在一个磁盘上的日志文件,而是对应磁盘上的一个目录,这个目录的明明规则是_比如创建一个名为 firstTopic 的 topic,其中有 3 个 partition,那么在 kafka 的数据目录(/tmp/kafka-log)中就有 3 个目录,firstTopic-0~3
多个分区在集群中的分配
如果我们对于一个 topic,在集群中创建多个 partition,那么 partition 是如何分布的呢? 1.将所有 N Broker 和待分配的 i 个 Partition 排序 2.将第 i 个 Partition 分配到第(i mod n)个 Broker 上
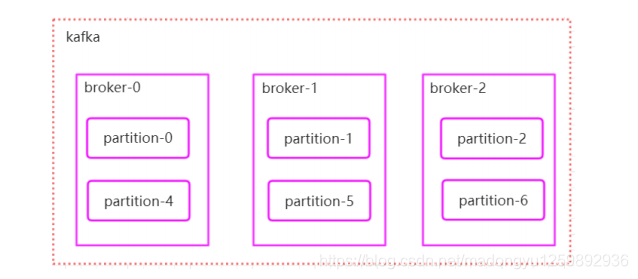
了解到这里的时候,大家再结合前面讲的消息分发策略,就应该能明白消息发送到 broker 上,消息会保存到哪个分区中,并且消费端应该消费哪些分区的数据了。
消息写入的性能
我们现在大部分企业仍然用的是机械结构的磁盘,如果把消息以随机的方式写入到磁盘,那么磁盘首先要做的就是 寻址,也就是定位到数据所在的物理地址,在磁盘上就要找到对应的柱面、磁头以及对应的扇区;这个过程相对内 存来说会消耗大量时间,为了规避随机读写带来的时间消耗,kafka 采用顺序写的方式存储数据。即使是这样,但是频繁的 I/O 操作仍然会造成磁盘的性能瓶颈,所以 kafka还有一个性能策略
零拷贝
消息从发送到落地保存,broker 维护的消息日志本身就是文件目录,每个文件都是二进制保存,生产者和消费者使用相同的格式来处理。在消费者获取消息时,服务器先从硬盘读取数据到内存,然后把内存中的数据原封不动的通过 socket 发送给消费者。虽然这个操作描述起来很简单,但实际上经历了很多步骤。
如下图:
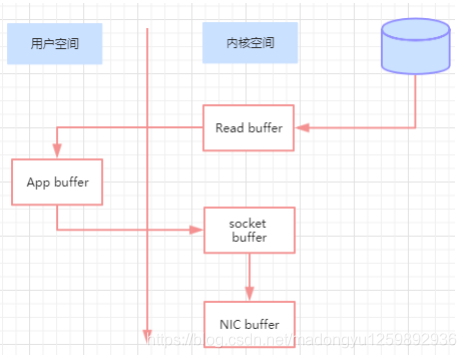
▪ 操作系统将数据从磁盘读入到内核空间的页缓存
▪ 应用程序将数据从内核空间读入到用户空间缓存中
▪ 应用程序将数据写回到内核空间到 socket 缓存中
▪ 操作系统将数据从 socket 缓冲区复制到网卡缓冲区,以便将数据经过网络发出
这个过程涉及到 4 次上下文切换以及 4 次数据复制,并且有两次复制操作是由 CPU 完成。但是这个过程中,数据完全没有进行变化,仅仅是从磁盘复制到网卡缓冲区。
通过“零拷贝”技术,可以去掉这些没必要的数据复制操作,同时也会减少上下文切换次数。现代的 unix 操作系统提供一个优化的代码路径,用于将数据从页缓存传输到 socket;在 Linux 中,是通过 sendfile 系统调用来完成的。Java 提供了访问这个系统调用的方法:FileChannel.transferTo API
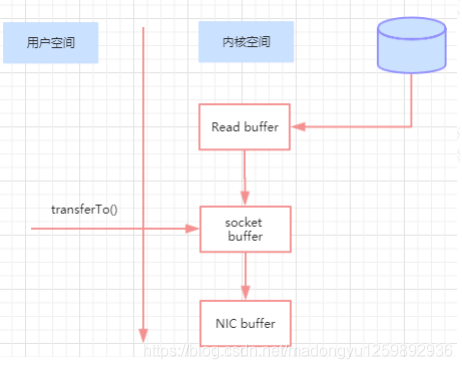
使用 sendfile,只需要一次拷贝就行,允许操作系统将数据直接从页缓存发送到网络上。所以在这个优化的路径中,只有最后一步将数据拷贝到网卡缓存中是需要的。
