聚类对数据的要求
1.数据不能均匀分布
2.霍普金斯统计量,空间统计量,检验空间随机性,在给定的数据集D,它可以看作随机变量o的一个样本,我们想要确定o在多大的程度上,不同于数据空间中的均匀分布。
霍普金斯统计量的操作步骤
1.均匀的从D的空间中抽取n个点p1…pn,也就是说D中的每个样本点都以相同的概率包含在这个样本中,对于每个样本pi(1<=i<=n),我们找出pi在D中的最邻近,并令xi为Pi与它在D中的最邻近之间的距离。
2.均匀的从D的空间中抽取n个点q1…qn,也就是说D中的每个样本点都以相同的概率包含在这个样本中,对于每个样本qi(1<=i<=n),我们找出qi在D-{qi }中的最邻近,并令yi为qi与它在D-{ qi}中的最邻近之间的距离。
3.计算霍普金斯统计量
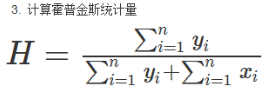
霍普金斯统计量解读
霍普金斯统计量告诉我们数据集D多大可能遵循数据空间的均匀分布
如果D是均匀分布,则霍普金斯统计量的分母中的两部分会很接近,从而导致得到的H值接近于0.5,然而,如果D是高度倾斜的,则上式中的第一项的值会显著小于第二项,因而H将接近于0。
聚类的簇数制定
1.经验判断的方法,列如样本点的数目是n,则取k=sqrt(n/2)
2.肘方法
3.PSF或者PST2这类统计量 伪F统计量 伪T2统计量
4.信息论方法与信息准则
5.交叉验证
肘方法
基于如下的观察 增加簇数,有助于降低每个簇的簇内方差之和。这是因为更多簇的出现,可以捕获更细的数据对象簇,簇中对象之间更为相似,然鹅形成太多的簇,则降低簇内方差和的边缘效应可能下降,因为吧一个凝聚的簇分裂成两个只引起cuneiform方差和的稍微降低,因此一种正确的簇数的启发方式是,使用cuneiform方差和关于簇数的曲线的拐点。严格的说,给定k>0,我么们可以使用一种像K-均值这样的算法对数据集聚类,并计算簇内方差和Var(k)。然后,我们绘制Var关于k的曲线,曲线的第一个拐点,暗示着正确的簇数。
总体离差平方和
簇内离差平方和

内在方法,簇的分离情况和簇的紧凑情况

模糊聚类
EM算法
最大期望算法 是一种迭代算法,用于含有隐含变量的概率参数模型的最大似然估计或极大后验概率估计
通常包含两个交替步骤进行
E步骤 估计未知参数的期望值,给出当前参数估计
M步骤 重新估计分布参数,以使得数据的似然性最大,给出未知变量的的期望估计
M步上找到参数估计值被用于下一个E步计算中,这个过程不断交替进行,重复直到收敛。
基于概率模型的聚类
聚类分析的目的是发现隐藏的类别,作为聚类的分析主题的数据集可以看作隐藏的类别的可能实例的一个样本,但是没有
类别号。由聚类分析导出的簇使用数据集推断,并且旨在逼近隐藏的类别。
从统计学上讲,我们可以假定隐藏的类别是一个数据空间上的分布,可以使用概率密度函数精确的表示,我们称这种隐藏的类别我i概率簇,对于一个概率簇C,它的密度函数f和数据空间点o,f(o)是C的一个实例在o上出现的相对似然。
离群值的检测
又称为异常值检测,孤立点检测
检测离群值的方法
基于统计学的方法
按照标准差和分布原则,来检测数据的分布异常
箱线图识别离群值
一元离群值检验Grubb检验

马氏距离,主要可以消除数据之间不同的量纲之间的差异,进行排除异常的数据值。

基于邻近性的方法
基于聚类的方法
