SortedSet 应该是 Redis 里最复杂的一个数据结构,也是面试中被问及最多的~
先看下最简单的应用:
redis 127.0.0.1:6379> ZADD todayScoreRank 100 张三
redis 127.0.0.1:6379> ZADD todayScoreRank 90 李四
redis 127.0.0.1:6379> ZADD todayScoreRank 80 王五
redis 127.0.0.1:6379> ZADD todayScoreRank 70 赵六
redis 127.0.0.1:6379> ZADD todayScoreRank 60 李七
redis 127.0.0.1:6379> ZRANGE todayScoreRank 80 100 WITHSCORES通过给每个元素(张三、李四)增加分数(score:100,90)来实现有序。
在了解 SortedSet 实现原理前,有一点不得不提,那就是:
Redis 是靠内存工作的,而内存成本也是很高的,所以,如何高效利用内存就成了 Redis 设计的一个主线
这个论点对于理解 Redis 实现原理非常有帮助,那就是在时间允许的情况下会采取节约内存的方案,如果时间不允许了再使用占用更多内存的方案。
首先,我们来看几个参数:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64在理解这两个参数前,我们先简单了解下 ziplist 这种数据结构,顾名思义:压缩列表,怎么个压缩法,简单来说就是对于大的数据会用比较多点字节来存储,对于小的数据就用比较少的字节来存储,具体会在另一篇文章中聊。
if (
field-value对的数量 > ziplist.entries.size ||
任意一个filed或value长度 > zset-max-ziplist-value
) {
// 使用 zset 进行存储
} else {
// 使用 ziplist 进行存储
}这样,在数据量相对比较少时,对 ziplist 的遍历及查找时间可控,同时可以节省内存空间
知道了何时会选用 zset 后,下面有请主角登场:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;zset 结构体里有两个元素,一个是 dict,用来维护 数据 到 分数 的关系,一个是 zskiplist,用来维护 分数 到 数据的关系

dict 里通过维护 哈希表 存储了 张三=>100,李四=>90 的分数关系,这里不做过多介绍。
接下来有请 zset 圈的主角 zskiplist(z跳表,注意:不是常规的跳表):
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;zskiplist 结构体中有四个元素:分别是指向 头 和 尾 的指针,整个链表的长度,以及最大的 跳表层数。
什么是跳表呢 ?我们先来看下它的由来:
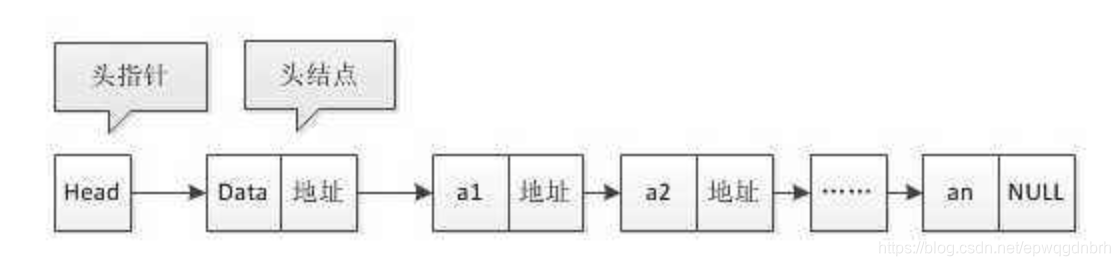
我们知道链表的一个特性是只能 顺序遍历 不能进行随机访问,如果有 100 个节点,要找到中间的节点 需要 遍历 一半的节点才能拿到对应的值(张三、李四),为了解决这个问题,跳表应运而生(有人会问为什么不用平衡树,原因是跳表实现比他们要简单很多)
这就是常规的跳表,即在原有的基础上往链表上层增加一层跨越部分节点的新链表,一层一层增加,越向上元素越少。查找元素 5 时会从最上层的链表开始查找,如果发现当前节点 4 小于目标 5 且下一个节点 6 > 5,则进入下一层链表,以此类推。这样在元素比较多的情况下,可以大大缩短查找一个元素的时间。
但普通跳表有很多限制和问题,如下:
(1)分数不允许重复
(2)第一层链表为单向链表,不够灵活
于是,Redis 改良版的 zskiplist 被发明了,如下:
允许重复分数;第一层链表改为了双线链表,方便进行倒序范围查找;增加span(跨度)概念,方便计算正向和反向排名
到此,彻底搞明白了 Sorted Set 数据结构的实现原理。
我认为学习这些底层原理并不只是为了找工作面试用,更多的是拓宽了我们的眼界,在遇到问题时多了一种可供选择的方案,不断拓展我们的知识面,才能在解决问题的时候做到厚积薄发 !
