开篇
这篇博客主要讲的是关于英文的一些处理,关于中文的一些nlp处理后续有机会补上。本文主要有以下几个内容:
- 基于规则的预处理
- 常规预处理
- spaCy库的常规使用
- pointer-generator
关于预处理
预处理是很多NLP任务的基础,一个好的预处理对后续的NLP结果有很重要的影响。首先是关于分词的一些问题,中文分词是老大难问题,不太好分,英文就简单得多了,但是英文还是会出现一些问题的,比如what’s,can’t这种基本的分词器就很难分好,有些带有否定语义的后期对整句的语义理解就会带来很大的问题。所以这边希望能够通过一些常规的正则化手段去替换掉这些能以分词成功的缩写,下面的代码就展示了这样的功能预处理,希望能够给予大家一点启发。
基于规则的预处理
一些缩写的替换和符号的替换
def clean_text(text):
"""
Clean text
:param text: the string of text
:return: text string after cleaning
"""
# unit
text = re.sub(r"(\d+)kgs ", lambda m: m.group(1) + ' kg ', text) # e.g. 4kgs => 4 kg
text = re.sub(r"(\d+)kg ", lambda m: m.group(1) + ' kg ', text) # e.g. 4kg => 4 kg
text = re.sub(r"(\d+)k ", lambda m: m.group(1) + '000 ', text) # e.g. 4k => 4000
text = re.sub(r"\$(\d+)", lambda m: m.group(1) + ' dollar ', text)
text = re.sub(r"(\d+)\$", lambda m: m.group(1) + ' dollar ', text)
# acronym
text = re.sub(r"can\'t", "can not", text)
text = re.sub(r"cannot", "can not ", text)
text = re.sub(r"what\'s", "what is", text)
text = re.sub(r"What\'s", "what is", text)
text = re.sub(r"\'ve ", " have ", text)
text = re.sub(r"n\'t", " not ", text)
text = re.sub(r"i\'m", "i am ", text)
text = re.sub(r"I\'m", "i am ", text)
text = re.sub(r"\'re", " are ", text)
text = re.sub(r"\'d", " would ", text)
text = re.sub(r"\'ll", " will ", text)
text = re.sub(r"c\+\+", "cplusplus", text)
text = re.sub(r"c \+\+", "cplusplus", text)
text = re.sub(r"c \+ \+", "cplusplus", text)
text = re.sub(r"c#", "csharp", text)
text = re.sub(r"f#", "fsharp", text)
text = re.sub(r"g#", "gsharp", text)
text = re.sub(r" e mail ", " email ", text)
text = re.sub(r" e \- mail ", " email ", text)
text = re.sub(r" e\-mail ", " email ", text)
text = re.sub(r",000", '000', text)
text = re.sub(r"\'s", " ", text)
# spelling correction
text = re.sub(r"ph\.d", "phd", text)
text = re.sub(r"PhD", "phd", text)
text = re.sub(r"pokemons", "pokemon", text)
text = re.sub(r"pokémon", "pokemon", text)
text = re.sub(r"pokemon go ", "pokemon-go ", text)
text = re.sub(r" e g ", " eg ", text)
text = re.sub(r" b g ", " bg ", text)
text = re.sub(r" 9 11 ", " 911 ", text)
text = re.sub(r" j k ", " jk ", text)
text = re.sub(r" fb ", " facebook ", text)
text = re.sub(r"facebooks", " facebook ", text)
text = re.sub(r"facebooking", " facebook ", text)
text = re.sub(r"insidefacebook", "inside facebook", text)
text = re.sub(r"donald trump", "trump", text)
text = re.sub(r"the big bang", "big-bang", text)
text = re.sub(r"the european union", "eu", text)
text = re.sub(r" usa ", " america ", text)
text = re.sub(r" us ", " america ", text)
text = re.sub(r" u s ", " america ", text)
text = re.sub(r" U\.S\. ", " america ", text)
text = re.sub(r" US ", " america ", text)
text = re.sub(r" American ", " america ", text)
text = re.sub(r" America ", " america ", text)
text = re.sub(r" quaro ", " quora ", text)
text = re.sub(r" mbp ", " macbook-pro ", text)
text = re.sub(r" mac ", " macbook ", text)
text = re.sub(r"macbook pro", "macbook-pro", text)
text = re.sub(r"macbook-pros", "macbook-pro", text)
text = re.sub(r" 1 ", " one ", text)
text = re.sub(r" 2 ", " two ", text)
text = re.sub(r" 3 ", " three ", text)
text = re.sub(r" 4 ", " four ", text)
text = re.sub(r" 5 ", " five ", text)
text = re.sub(r" 6 ", " six ", text)
text = re.sub(r" 7 ", " seven ", text)
text = re.sub(r" 8 ", " eight ", text)
text = re.sub(r" 9 ", " nine ", text)
text = re.sub(r"googling", " google ", text)
text = re.sub(r"googled", " google ", text)
text = re.sub(r"googleable", " google ", text)
text = re.sub(r"googles", " google ", text)
text = re.sub(r" rs(\d+)", lambda m: ' rs ' + m.group(1), text)
text = re.sub(r"(\d+)rs", lambda m: ' rs ' + m.group(1), text)
text = re.sub(r"the european union", " eu ", text)
text = re.sub(r"dollars", " dollar ", text)
# punctuation
text = re.sub(r"\+", " + ", text)
text = re.sub(r"'", " ", text)
text = re.sub(r"-", " - ", text)
text = re.sub(r"/", " / ", text)
text = re.sub(r"\\", " \ ", text)
text = re.sub(r"=", " = ", text)
text = re.sub(r"\^", " ^ ", text)
text = re.sub(r":", " : ", text)
text = re.sub(r"\.", " . ", text)
text = re.sub(r",", " , ", text)
text = re.sub(r"\?", " ? ", text)
text = re.sub(r"!", " ! ", text)
text = re.sub(r"\"", " \" ", text)
text = re.sub(r"&", " & ", text)
text = re.sub(r"\|", " | ", text)
text = re.sub(r";", " ; ", text)
text = re.sub(r"\(", " ( ", text)
text = re.sub(r"\)", " ( ", text)
# symbol replacement
text = re.sub(r"&", " and ", text)
text = re.sub(r"\|", " or ", text)
text = re.sub(r"=", " equal ", text)
text = re.sub(r"\+", " plus ", text)
text = re.sub(r"₹", " rs ", text) # 测试!
text = re.sub(r"\$", " dollar ", text)
# remove extra space
text = ' '.join(text.split())
return text
不要小看这些小小的处理,它们会对后期的NLP有着很大的影响,尤其是你在处理句子粒度的任务的时候,一个单词出现分词错误都会对整句话的语义产生巨大的影响。
词粒度的分析
这边先引入spaCy库的使用,很多时候我们要分析一些词的词性来完成我们文本的预处理,实际操作中,关于预处理,我使用nltk会比较多一些,但是spaCy确实是一个强大而且生命力旺盛的商业级开源库,这边先给出一个示例代码,讲一下它的常规使用,具体的细节希望大家能够访问它的官网spaCy。
下面的代码是有关于语言特征的分析:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(u'Apple is looking at buying U.K. startup for $1 billion')
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)使用spaCy的重要三步(前三行代码),第一步导入spacy库,第二步加载它的语言和模型包,这些语言和模型包是需要下载的,不同的模型和语言支持的功能是不一样的。
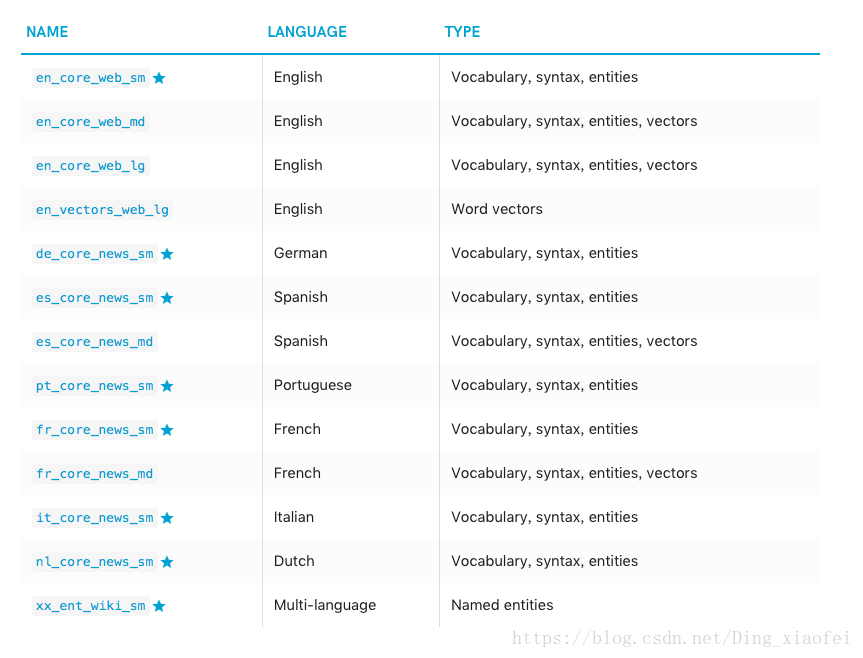
英文的第二个包和第三个包会比较大,也比较难下载,其实它和第一个包最大的区别就是它是内置训练好的词向量的,这个后面的相似度任务中会具体用到。
关于上面的代码,我们有以下的结果
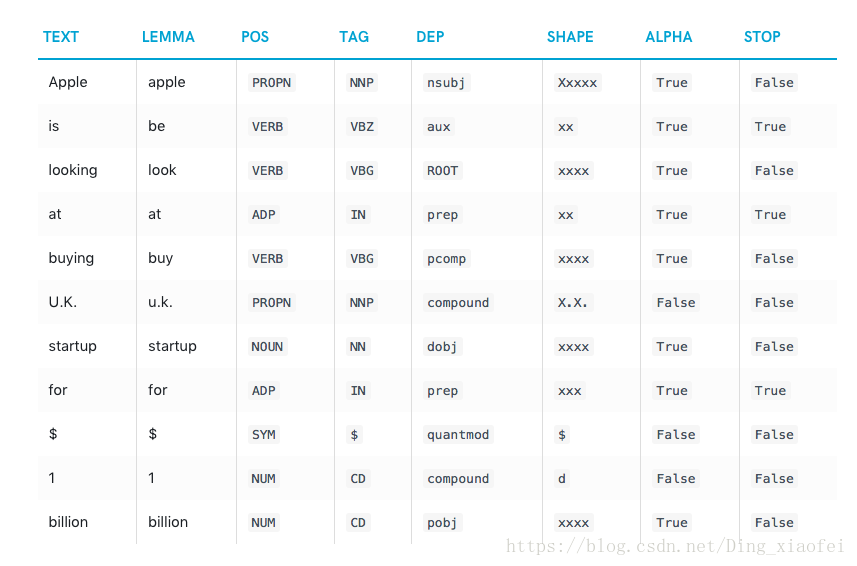
它是逐词分析的
Text: The original word text.
Lemma: The base form of the word.
POS: The simple part-of-speech tag.
Tag: The detailed part-of-speech tag.
Dep: Syntactic dependency, i.e. the relation between tokens.
Shape: The word shape – capitalisation, punctuation, digits.
is alpha: Is the token an alpha character?
is stop: Is the token part of a stop list, i.e. the most common words of the language?有了这些词性的结果,我们是很容易是去除停用词,提取相应词性的单词的。
常规预处理
下面是我常使用的预处理,主要使用NLTK库,常规的预处理是建立在规则处理之上的,规则处理是细粒度语言处理的代表。
下面先放出我的代码
#分词
#获取名词短语
#去除停用词
import json
import string
import nltk
from my_method import noun_chunk
from nltk.corpus import stopwords
from my_method import get_lemma
from my_method import get_tokens
#read data
with open('data/cristic_consensus.json','r') as f:
consensus = json.load(f)
with open('data/cristic.json','r') as f:
cristic = json.load(f)
#tokenize(rmove stopwords)
cristic_token = []
for item in cristic:
temp = []
for item_01 in item:
temp_01 = get_lemma(item_01)
temp_01 = get_tokens(item_01)
temp.append(temp_01)
cristic_token.append(temp)
with open('data/cristic_token.json','w') as f:
json.dump(cristic_token, f)
consensus_token = []
for item in consensus:
temp = get_lemma(item)
temp = get_tokens()
consensus_token.append(temp)
with open('data/consensus_token.json','w') as f:
json.dump(consensus_token, f)
#remove stopword
critics_temp = []
critics = [[x.lower() for x in c] for c in cristic]
for item in critics:
temp = [''.join(c for c in item_01 if c not in string.punctuation) for item_01 in item]
critics_temp.append(temp)
critics = critics_temp
critics = [[nltk.word_tokenize(x) for x in item] for item in critics]
critics = [[' '.join(c for c in item if c not in stopwords.words('english')) for item in item_01] for item_01 in critics]
with open('data/cristic_no_stop.json', 'w') as f:
json.dump(critics,f)
#get noun
consensus_noun_chunk = [noun_chunk(item) for item in consensus]
with open('data/consensus_noun_chunk.json','w') as f:
json.dump(consensus_noun_chunk, f)
cristic_noun_chunk = []
for _ in cristic:
temp_01 = [noun_chunk(item) for item in _]
cristic_noun_chunk.append(temp_01)
with open('data/cristic_noun_chunk.json','w') as f:
json.dump(cristic_noun_chunk, f)关于前几行导入的方法实现如下:
import nltk
import string
from nltk.corpus import stopwords
import spacy
import re
from nltk.stem.porter import *
nlp = spacy.load('en_core_web_lg')
#词性还原
def stem_tokens(tokens, stemmer):
stemmed = []
for item in tokens:
stemmed.append(stemmer.stem(item))
return stemmed
#注意啦,这边接受的就是一个字符串
def ie_process(document):
sentences = nltk.sent_tokenize(document)
sentences = [nltk.word_tokenize(sent) for sent in sentences]
sentences = [nltk.pos_tag(sent) for sent in sentences]
return sentences
def get_tokens(document):
document = document.lower()
document = ''.join(c for c in document if c not in string.punctuation)
document = nltk.word_tokenize(document)
document = [c for c in document if c not in stopwords.words('english')]
#stemmer = PorterStemmer()
#document = stem_tokens(document, stemmer)
return document
def get_lemma(document):
document = nlp(document)
document = ' '.join(token.lemma_ for token in document)
return document
def noun_chunk(document):
doc = nlp(document)
document = [item.text for item in doc.noun_chunks]
return document
def clean_title(document):
document = re.split(r'[_-]', document)
return document
如果大家需要相应的实验数据集可以在博客下面留言。这里面的主要操作包括词性还原,分词,提取句中的名词,当然你把这些方法写的更加通用一些,词性以参数的形式传入函数,这样你想提取什么词就提取什么词,nltk、spacy只是给了我们一些基本的词性分析,上层的提取任务就看大家怎么写啦。有问题欢迎大家留言提问。
情感分析和名词短语提取
既然是关于预处理的事情,这边就附带再讲两个我常用的NLP操作,算是附带讲一下另一个NLP库,一个不常使用的库,主要是在情感分析领域才会出现的库,但是专业做情感分析任务的人基本是不会使用的。细看的它的源码,其实就是一个训练好的有监督的分类器,没有什么高深的算法,训练语料就是评论,如果大家刚好也是要处理评论数据,那么就很合适啦。

情感分析和名词提取是textblob自带的两个函数,spacy中也有相关的名词提取函数,这两个库的提取结果还是有蛮大的区别的,textblob粒度比较粗。其实从源码的角度来看,它们也是使用的基于规则的方式来提取相应的短语,有兴趣的可以取读读它的源码实现,写出属于自己的提取函数。
下面是我们测试这两个函数的代码
import json
from textblob import TextBlob
sentiment_test = []
noun_phrases_test = []
with open('rottentomatoes.json', 'r') as f:
data_all = json.load(f)
data_test = data_all[0]
data_test = data_test['_critics']
data_test = list(data_test.values())
#print(data_test)
for review in data_test:
testimonial = TextBlob(review)
sentiment_test.append(testimonial.sentiment.polarity)
noun_phrases_test.append(testimonial.noun_phrases)
print(sentiment_test)
print(noun_phrases_test)
可能还不够明显,这边我放出官网的示例,textblob官网,不好意思官网好像有点卡,这边放一个我写的简单示例:
In [2]: from textblob import TextBlob
...: testimonial = TextBlob("Textblob is amazingly simple to use. What great
...: fun!")
...: print(testimonial.sentiment)
...:
Sentiment(polarity=0.39166666666666666, subjectivity=0.4357142857142857)使用TextBlob情感分析的结果,以元组的方式进行返回,形式如(polarity, subjectivity). 其中polarity的分数是一个范围为 [-1.0 , 1.0 ] 浮点数, 正数表示积极,负数表示消极。subjectivity 是一个 范围为 [0.0 , 1.0 ] 的浮点数,其中 0.0 表示 客观,1.0表示主观的。
名词短语的提取也是类似的,具体的使用参见官网吧,希望你看到这篇博客的时候,官网还能正常打开。
相似度的计算(spacy)
词的重叠度
让我们看一个很low但却有效的方法,计算词的重叠数,这个使用python的集合去做就可以啦。下面直接放出我的测试代码。
with open('data/cristic_token.json') as f:
cristic = json.load(f)
with open('data/consensus_token.json') as f:
consensus = json.load(f)
print(len(consensus))
overlap_total = []
for n in range(3731):
overlap = [list(set(consensus[n]).intersection(set(item))) for item in cristic[n]]
overlap_total.append(overlap)
print(n)ok,下面正式讲spacy中关于相似度的计算。
spacy
spacy中有这么几个概念,doc、span、token,它们代表的是不同文本的粒度,doc就是整句话或者整段话,而span就是片段啦,token就是词粒度了。在spacy中,它们都具有相似度计算的方法。一个简单的示例如下:
import spacy
nlp = spacy.load('en_core_web_md') # make sure to use larger model!
tokens = nlp(u'dog cat banana')
for token1 in tokens:
for token2 in tokens:
print(token1.text, token2.text, token1.similarity(token2))这边我们使用的是英文的第二个模型来计算我们的相似度,为什么要使用第二个模型呢,原因很简单,词粒度的相似度我们必须要使用词向量的cosine来计算,这点很重要,也能够体现出词向量的价值。spacy大的模型是自带词向量的。关于词向量的生成不多说,后期会有一篇博客讲如何用tensorflow去写一个词向量生成器,训练自己的词向量。
下面是上面代码的运行结果:
dog dog 1.0
dog cat 0.80168545
dog banana 0.24327646
cat dog 0.80168545
cat cat 1.0
cat banana 0.2815437
banana dog 0.24327646
banana cat 0.2815437
banana banana 1.0当然对于很多自己的应用,我们是不考虑使用spacy自带的词向量的,我们需要使用自己训练的词向量,这时候spacy也是支持你导入自己的词向量的
nlp = spacy.load('en')
nlp.vocab.vectors.from_glove('/path/to/vectors')spacy是可以训练自己模型的库,功能丰富,更多的信息请访问官网。
(未完待续)