BeautifulSoup是处理爬虫的一个强大工具,在HTML页面中,是由各种标签构成的,BeautifulSoup的功能就是从标签下手的,它是解析、遍历、维护“标签树”的功能库。
BeautifulSoup的基本元素如下:

1. 基本格式如下:
1 from bs4 import BeautifulSoup 2 import requests 3 4 url = "http://python123.io/ws/demo.html" 5 6 r = requests.get(url) 7 demo = r.text 8 soup = BeautifulSoup(demo, "html.parser") #将爬到的内容进行解析,demo就是内容,"html.parser"是解析器,按照html格式来进行解析 9 print(soup.prettify()) #输出解析得到的内容
解析效果如下:

2. 具体使用方法如下:
1 >>> from bs4 import BeautifulSoup 2 >>> import requests 3 >>> url = "http://python123.io/ws/demo.html" 4 >>> r = requests.get(url) 5 >>> demo = r.text 6 >>> soup = BeautifulSoup(demo, "html.parser") 7 >>> soup.title #显示标题 8 <title>This is a python demo page</title> 9 >>> soup.a #显示a标签内容 10 <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> 11 >>> soup.a.name #显示a标签名字 12 'a' 13 >>> soup.a.parent.name #显示a标签父标签名字 14 'p' 15 >>> soup.a.parent.parent.name #显示a标签父标签的父标签名字 16 'body' 17 >>> soup.a.attrs #获得a标签的属性 18 {'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'} 19 >>> soup.a.attrs["class"] #因为是字典,所以这里用字典形式可以获得各个属性的值 20 ['py1'] 21 >>> type(soup.a.attrs) 22 <class 'dict'> #字典类型 23 >>> soup.a.string #获得a标签中的字符内容 24 'Basic Python' 25 >>> soup #soup内容如下 26 <html><head><title>This is a python demo page</title></head> 27 <body> 28 <p class="title"><b>The demo python introduces several python courses.</b></p> 29 <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: 30 31 <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p> 32 </body></html> 33 >>>
3. 标签树的下行遍历
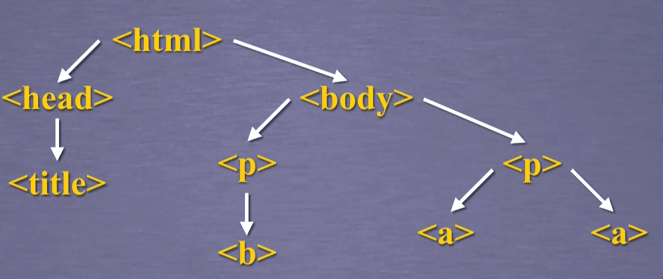

1 >>> soup.head #获取soup的head 2 <head><title>This is a python demo page</title></head> 3 >>> soup.head.contents #获取head的儿子结点 4 [<title>This is a python demo page</title>] 5 >>> soup.body.contents #获取body的儿子结点 6 ['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p 7 8 class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to 9 10 professional by tracking the following courses:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" 11 12 id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" 13 14 id="link2">Advanced Python</a>.</p>, '\n'] 15 >>> 16 >>> len(soup.body.contents) #获取儿子结点的个数 17 5 18 >>>
4. 标签树的上行遍历


5. 标签树的平行遍历

平行遍历发生在同一个父节点下的各节点间。