如何在AidLearning中快速开发人脸识别APP
双击Examples进入案例中心,点击FaceID进入人脸识别代码编辑状态。
- 提示:案例中的代码不要随意改动,因为AID默认运行前会保存代码文件,如果修改测试,可以先复制一下代码文件。

接下来我们详细介绍下AID Learning中的人脸识别代码是如何实现的。
#导入cvs图形控件的库
from cvs import *
#导入人脸识别的库
import facerecognition
#导入开源的数值科学计算库,别名为np
import numpy as np
#定义一个名为MyApp的类,用于构建程序的图形化APP
class MyApp(App):
#初始化函数,self表示创建实例本身,*args传递可变参数,__init__()的第一个参数永远是self.
def __init__(self, *args):
super(MyApp, self).__init__(*args)
def main(self):
#creating a container VBox type, vertical (you can use also HBox or Widget)
#定义变量main_container,它的作用是整个APP的主框架,用于包含其他APP中的控件,相当于容器
#在手机上画出一个宽度为360px,高度为680px的程序主框架范围,style是它的样式。
main_container = gui.VBox(width=360, height=680, style={'margin':'0px auto'})
'''
OpencvVideoWidget函数是在手机中画一个用于显示调用手机摄像头拍摄图像的框,宽度340px,
高度480px,将它赋值给self.aidcam,aidcam是摄像头控件。
'''
self.aidcam = OpencvVideoWidget(self, width=340, height=480)
#摄像头框架的边界和主框架相隔10px。
self.aidcam.style['margin'] = '10px'
#给aidcam设置一个别名
self.aidcam.set_identifier("myimage_receiver")
#将设置好的摄像头显示框添加到APP主框架中。
main_container.append(self.aidcam)
#设置一个宽度200px,高度30px,边界为10px的文本框,将它赋值给 self.txt, self.txt是文本框控件
self.txt = gui.TextInput(width=200, height=30, margin='10px')
#文本框初始化值为“usename”
self.txt.set_text('usename')
#用于监听文本框中的内容是否改变
self.txt.onchange.do(self.on_text_area_change)
'''
设置一个宽度为200px,高度为30px,边界为10px的按钮控件,按钮上的文字为“Add Person!”,
将它赋值给 self.bt按钮控件
'''
self.bt = gui.Button('Add Person!', width=200, height=30, margin='10px')
#用于监听按钮是否被点击
self.bt.onclick.do(self.on_button_pressed)
#将设置好的文本框添加到APP主框架中
main_container.append(self.txt)
#将设置好的按钮添加到APP主框架中
main_container.append(self.bt)
# returning the root widget,返回APP主框架
return main_container
'''
如果监听到文本框中的内容发生改变,我们用print函数将这段'Text Area value changed!'
这段文字写入日志文件
'''
def on_text_area_change(self, widget, newValue):
print('Text Area value changed!')
#如果监听到按钮被点击则触发事件
def on_button_pressed(self, widget):
#将文本框的内容存储到userId中
userId = self.txt.get_text()
#将文本框内容存储到cvs下面的一个全局变量中
cvs.setLbs(userId)
#将按钮的文字内容改为'success!'
self.bt.set_text('success!')
#读取摄像头图像,并且进行人脸识别
def process():
#1是调用手机前置摄像头,如果是cvs.VideoCapture(0)就是调用手机后置摄像头
cap=cvs.VideoCapture(1)
'''
加载人脸识别的学习模型,第一个参数路径,第二个是阈值,0.73是默认值,阈值的范围是0-1,
阈值约高,识别越严格,通过率约低,例如如果一个人的头发乱了,或者脸上有一些遮挡等,一般建议不要设定太高
'''
facerecog = facerecognition.FaceRecognition("./models", 0.73)
#定义了一个while循环,作用是将人脸图像添加到数据库
while True:
#是让程序休眠30毫秒,避免卡死
sleep(30)
#读取当前摄像头下拍摄的图像
img =cap.read()
#如果图像为空,则重复该循环
if img is None :
continue
#将图像转为unint8的格式再转化为一组字符串格式
image_char = img.astype(np.uint8).tostring()
#获得刚刚的全局变量cvs.setLbs的值,也就是文本框中输入的文字
userId=cvs.getLbs()
if userId!='':
'''
#当文本框不为空的时候,将文本框中的值,img.shape[0]是图像的宽,img.shape[1]是图像的高,
image_char是图像转化成的字符串数据,添加到人脸数据库feature.db中
'''
ret=facerecog.add_person(userId, img.shape[0], img.shape[1], image_char)
#如果返回的值是0,表示添加成功,否则添加失败,并用print函数写入一段文字到日志文件
if ret==0:
print ('you add_person is success!')
# cvs.setMsg_status(1)
else :
print ('you add_person is failed!')
#编程的一个必要动作,将全局变量重新设置为空,避免后面出现不必要的错误
userId=''
cvs.setLbs(userId)
continue
#是将当前摄像头中的人脸数据和数据库feature.db中的数据进行对比
rets = facerecog.recognize(img.shape[0], img.shape[1], image_char)
#print 'rets:',rets
#如果数据库中的人脸图像和当前摄像头中的人脸一致,则用print将一段文字写入日志文件
for ret in rets:
#for ret in each:
print ('draw bounding box for the face')
#提取人脸绿色框的位置
rect = ret['rect']
#左上角x坐标,rect[1]左上角y坐标。
p1 = (int(rect[0]), int(rect[1]))
#人脸范围的宽度,p2则是右下角坐标
p2 = (int(rect[0]+rect[2]), int(rect[1]+rect[2]))
'''
#draw rect,names of faces
#img是图像,p1左上角,p2右上角,(0, 255, 0)外框的颜色,3是指线的宽度,1是指线的类型,
可以改变使线更平滑,作用是在摄像头中的人脸图像上画框
'''
cv2.rectangle(img, p1,p2, (0, 255, 0) , 3, 1)
'''
#img是图像, ret['name']是该人脸对应的名字,(int(rect[0]), int(rect[1])-30)是文字的位置,
cv2.FONT_ITALIC是字体,2是字体的大小,(77, 255, 9)文字的颜色,最后的2是线的类型。
作用是在绿色框上面写出该人脸的名字
'''
cv2.putText(img, ret['name'], (int(rect[0]), int(rect[1])-30),cv2.FONT_ITALIC, 2, (77, 255, 9), 2)
#将画好的框和名字显示出来
cvs.imshow(img)
if __name__ == '__main__':
#设置线程启动
initcv(process)
#启动APP
startcv(MyApp)
重点提示
- rets = facerecog.recognize(img.shape[0], img.shape[1],
image_char),返回了多个值,是因为摄像头中可能有两个以上的头像,所以分别与数据库中的人脸特征值对比。
- 同一个人脸显示多个名字是因为每个人脸特征赋是一个单独元素。而却录入了不同的名字,可以给同一个人赋值同一个名字,问题解决。
- 另外文本框中只能录入英文,facerecog.add_person的第一个参数只能接受英文字符

可视化控件
AID OS中的Wizard可以可视化拖动这些控件。
这里面有之前用到的Textarea,Button,Webcam,还有Label,ListView等大量控件。
使用拖拽的方式就可以来快速的布局你的APP程序,减少大量重复性的代码工作。
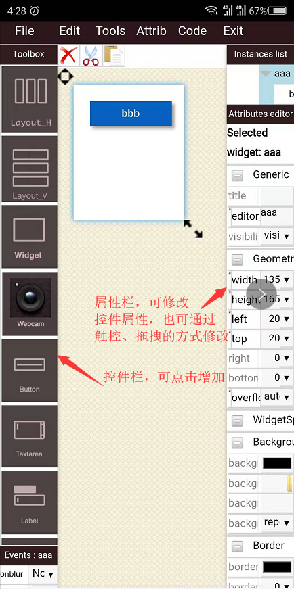
文中用到的控件含义

总结:

