文章目录
一、简单分析一下需求
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
如在金融、电商、支付、等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,此时一个能够生成全局唯一ID的系统是非常必要的。
这就引出了分布式系统唯一ID的特点:
- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,这就会带来一场灾难。
二、常见生成策略的优缺点对比
方法一: 用数据库的 auto_increment 来生成
优点:
- 此方法使用数据库原有的功能,所以相对简单
- 能够保证唯一性
- 能够保证递增性
- id 之间的步长是固定且可自定义的
缺点:
- 可用性难以保证:数据库常见架构是 一主多从 + 读写分离,生成自增ID是写请求,主库挂了就玩不转了
- 扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且 难以扩展
改进方案
-
冗余主库,避免写入单点
-
数据水平切分,保证各主库生成的ID不重复
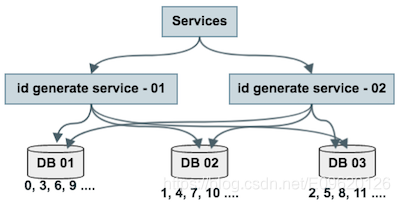 方法一改进方案的结构图
方法一改进方案的结构图如上图所述,由1个写库变成3个写库,
每个写库设置不同的 auto_increment 初始值,以及相同的增长步长
,以保证每个数据库生成的ID是不同的(上图中DB 01生成0,3,6,9…,DB 02生成1,4,7,10,DB 03生成2,5,8,11…)
改进后的架构保证了可用性,但缺点是
- 丧失了ID生成的“绝对递增性”:先访问DB 01生成0,3,再访问DB 02生成1,可能导致在非常短的时间内,ID生成不是绝对递增的(这个问题不大,目标是趋势递增,不是绝对递增
- 数据库的写压力依然很大,每次生成ID都要访问数据库
为了解决这些问题,引出了以下方法:
方法二:单点批量ID生成服务
分布式系统之所以难,很重要的原因之一是“没有一个全局时钟,难以保证绝对的时序”,要想保证绝对的时序,还是只能使用单点服务,用本地时钟保证“绝对时序”。
数据库写压力大,是因为每次生成ID都访问了数据库,可以使用批量的方式降低数据库写压力。
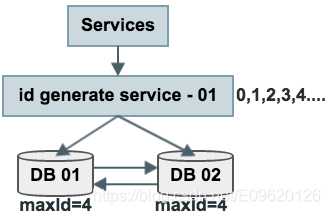 方法二的结构图
方法二的结构图
如上图所述,数据库使用双master保证可用性,数据库中只存储当前ID的最大值,例如4。
ID生成服务假设每次批量拉取5个ID,服务访问数据库,将当前ID的最大值修改为4,这样应用访问ID生成服务索要ID,ID生成服务不需要每次访问数据库,就能依次派发0,1,2,3,4这些ID了。
当ID发完后,再将ID的最大值修改为11,就能再次派发6,7,8,9,10,11这些ID了,于是数据库的压力就降低到原来的1/6。
优点:
- 保证了ID生成的绝对递增有序
- 大大的降低了数据库的压力,ID生成可以做到每秒生成几万几十万个
缺点:
- 服务仍然是单点
- 如果服务挂了,服务重启起来之后,继续生成ID可能会不连续,中间出现空洞(服务内存是保存着0,1,2,3,4,数据库中max-id是4,分配到3时,服务重启了,下次会从5开始分配,3和4就成了空洞,不过这个问题也不大)
- 虽然每秒可以生成几万几十万个ID,但毕竟还是有性能上限,无法进行水平扩展
改进方案
单点服务的常用高可用优化方案是“备用服务”,也叫“影子服务”,所以我们能用以下方法优化上述缺点:
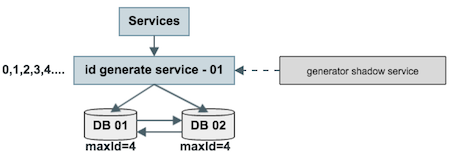 方法二改进方案的结构图
方法二改进方案的结构图
如上图,对外提供的服务是主服务,有一个影子服务时刻处于备用状态,当主服务挂了的时候影子服务顶上。这个切换的过程对调用方是透明的,可以自动完成,常用的技术是vip+keepalived。另外,id generate service 也可以进行水平扩展,以解决上述缺点,但会引发一致性问题。
方法三:uuid / guid
不管是通过数据库,还是通过服务来生成ID,业务方Application都需要进行一次远程调用,比较耗时。uuid是一种常见的本地生成ID的方法。
UUID uuid = UUID.randomUUID();
优点:
- 本地生成ID,不需要进行远程调用,时延低
- 扩展性好,基本可以认为没有性能上限
缺点:
- 无法保证趋势递增
- uuid过长,往往用字符串表示,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性)
- 信息不安全,基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
方法四:取当前毫秒数
uuid是一个本地算法,生成性能高,但无法保证趋势递增,且作为字符串ID检索效率低,有没有一种能保证递增的本地算法呢? - 取当前毫秒数是一种常见方案。
优点:
- 本地生成ID,不需要进行远程调用,时延低
- 生成的ID趋势递增
- 生成的ID是整数,建立索引后查询效率高
缺点:
- 如果并发量超过1000,会生成重复的ID
这个缺点要了命了,不能保证ID的唯一性。当然,使用微秒可以降低冲突概率,但每秒最多只能生成1000000个ID,再多的话就一定会冲突了,所以使用微秒并不从根本上解决问题。
方法五:使用Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR 和 INCRBY 来实现。
优点:
- 依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
- 需要编码和配置的工作量比较大。
方法六:Twitter 开源的 Snowflake 算法
Snowflake是Twitter开源的分布式ID生成算法,其核心思想为,一个long型的ID:
-
41 bit 作为毫秒数 - 41位的长度可以使用69年
-
10 bit 作为机器编号 (5个bit是数据中心,5个bit的机器ID) - 10位的长度最多支持部署1024个节点
-
12 bit 作为毫秒内序列号 - 12位的计数顺序号支持每个节点每毫秒产生4096个ID序号
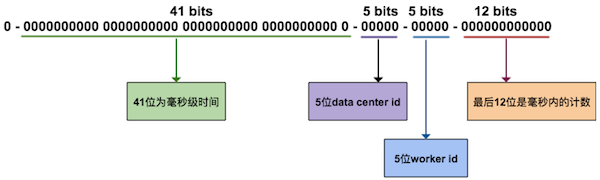 Snowflake图示
Snowflake图示
41-bit的时间可以表示(1 << 41) / (1000 * 3600 * 24 * 365) ≈ 69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的,完全能满足业务的需求。
优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
可以根据自身业务特性分配bit位,非常灵活。
缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
该算法 java 版本的实现代码如下:
public class SnowflakeIdGenerator {
//================================================Algorithm's Parameter=============================================
// 系统开始时间截 (UTC 2017-06-28 00:00:00)
private final long startTime = 1498608000000L;
// 机器id所占的位数
private final long workerIdBits = 5L;
// 数据标识id所占的位数
private final long dataCenterIdBits = 5L;
// 支持的最大机器id(十进制),结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
// -1L 左移 5位 (worker id 所占位数) 即 5位二进制所能获得的最大十进制数 - 31
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 支持的最大数据标识id - 31
private final long maxDataCenterId = -1L ^ (-1L << dataCenterIdBits);
// 序列在id中占的位数
private final long sequenceBits = 12L;
// 机器ID 左移位数 - 12 (即末 sequence 所占用的位数)
private final long workerIdMoveBits = sequenceBits;
// 数据标识id 左移位数 - 17(12+5)
private final long dataCenterIdMoveBits = sequenceBits + workerIdBits;
// 时间截向 左移位数 - 22(5+5+12)
private final long timestampMoveBits = sequenceBits + workerIdBits + dataCenterIdBits;
// 生成序列的掩码(12位所对应的最大整数值),这里为4095 (0b111111111111=0xfff=4095)
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
//=================================================Works's Parameter================================================
/**
* 工作机器ID(0~31)
*/
private long workerId;
/**
* 数据中心ID(0~31)
*/
private long dataCenterId;
/**
* 毫秒内序列(0~4095)
*/
private long sequence = 0L;
/**
* 上次生成ID的时间截
*/
private long lastTimestamp = -1L;
//===============================================Constructors=======================================================
/**
* 构造函数
*
* @param workerId 工作ID (0~31)
* @param dataCenterId 数据中心ID (0~31)
*/
public SnowflakeIdGenerator(long workerId, long dataCenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("Worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
throw new IllegalArgumentException(String.format("DataCenter Id can't be greater than %d or less than 0", maxDataCenterId));
}
this.workerId = workerId;
this.dataCenterId = dataCenterId;
}
// ==================================================Methods========================================================
// 线程安全的获得下一个 ID 的方法
public synchronized long nextId() {
long timestamp = currentTime();
//如果当前时间小于上一次ID生成的时间戳: 说明系统时钟回退过 - 这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出 即 序列 > 4095
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = blockTillNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - startTime) << timestampMoveBits) //
| (dataCenterId << dataCenterIdMoveBits) //
| (workerId << workerIdMoveBits) //
| sequence;
}
// 阻塞到下一个毫秒 即 直到获得新的时间戳
protected long blockTillNextMillis(long lastTimestamp) {
long timestamp = currentTime();
while (timestamp <= lastTimestamp) {
timestamp = currentTime();
}
return timestamp;
}
// 获得以毫秒为单位的当前时间
protected long currentTime() {
return System.currentTimeMillis();
}
//====================================================Test Case=====================================================
public static void main(String[] args) {
SnowflakeIdGenerator idWorker = new SnowflakeIdGenerator(0, 0);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}
应用举例Mongdb objectID
MongoDB官方文档 ObjectID可以算作是和snowflake类似方法,通过“时间+机器码+pid+inc”共12个字节,通过4+3+2+3的方式最终标识成一个24长度的十六进制字符。
