题目列表
- C/C++语言
- 1. 链表和数组的相同点和不同点
- 2. 静态链表及数组的实现
- 3.使用strcpy注意的问题
- 4. 链表反转
- 5. 判断含括号的表达式是否合法
- 6. Map的底层实现?为什么使用红黑树
- 7. 重载、重写(覆盖)和隐藏的定义与区别
- 8. virtual关键字是为了实现什么,具体怎么实现?
- 9. Hash表及底层实现机制
- 10. BSF(Breadth First Search)之中国象棋跳马问题
- 11.斐波那契数列之青蛙跳台阶的问题
- 12. 顶层const和底层const
- 13. 可以用memcmp比较两个struct吗?会有什么问题?
- 14. 堆、栈的区别
- 15. 堆排序和快排的区别?
- 16. 可变参数函数的定义及实现
- 17. 缓冲出溢出、内存泄漏、内存溢出
- 操作系统
- 1. 同步、死锁
- 2. 进程间常用的通信方式有哪些?
- 3. epoll和select/poll的区别
- 4. 进程与线程的区别
- 5. 系统调用与函数调用
- 6. Linux信号量
- 7.可重入函数,线程安全
- 8. 阻塞与非阻塞
- 9. 内存管理
- 网络知识
内容收集自网络
C/C++语言
1. 链表和数组的相同点和不同点
| 特点 | 优点 | 缺点 | |
|---|---|---|---|
| 数组 | 存储区域连续 需要预先分配空间,可能造成空间浪费或者不利于扩展 插入/删除效率低 随机读取效率高 |
随机访问性强 查找速度快 |
插入和删除效率低 可能浪费内存 内存空间要求高,必须有足够的连续内存空间 数组大小固定,不能动态拓展 |
| 链表 | 存储区域不要求连续,每个数据都保存了下一个数据的地址(如果有) 数据的增加/删除容易,易于扩展 数据查找效率低,只能顺序查找 |
插入删除速度快 内存利用率高,不会浪费内存 大小没有固定,拓展很灵活 |
不能随机查找,必须从第一个开始遍历,查找效率低 |
性能
| - | 数组 | 链表 |
|---|---|---|
| 读取 | O(1) | O(n) |
| 插入 | O(n) | O(1) |
| 删除 | O(n) | O(1) |
2. 静态链表及数组的实现
概念
对于没有指针的编程语言,可以用数组替代指针,来描述链表。让数组的每个元素由data和cur两部分组成,其中cur相当于链表的next指针,这种用数组描述的链表叫做静态链表,这种描述方法叫做游标实现法。
特点
这种储存结构仍需要预先分配一个较大的空间,但在作线性表的插入和删除操作是不需移动元素,仅需修改指针,故仍具有链式存储结构的主要有点。
优点
在插入和删除时候,只需要修改游标,不需要移动元素,从而改进了顺序存储结构中插入和删除操作需要移动大量元素的缺点。
缺点
没有解决连续存储分配带来的表长难以确定的问题;失去了顺序存储结构随机存取的特性。
3.使用strcpy注意的问题
来自MSDN的定义
char *strcpy(
char *strDestination,
const char *strSource
);
参数
strDestination:目标字符串。
strSource:null 终止的源字符串。
返回值
其中每个函数都会返回目标字符串。 没有保留任何返回值以指示错误。
说明
src和dst所指内存区域不可以重叠且dst必须有足够的空间来容纳src的字符串。
注意
因为strcpy不会检查strDestination是否有足够空间 ,它会直接复制strSource,很可能会造成缓冲区溢出。 因此,建议你使用 strcpy_s
strcpy_s的声明
// C定义
errno_t strcpy_s(
char *dest,
rsize_t dest_size,
const char *src
);
C++定义
errno_t strcpy_s(
char (&dest)[size],
const char *src
);
为了避免缓冲区溢出问题,我们也可以使用memcpy来完成的字符串的拷贝工作,memcpy是用来在内存中复制数据的,它会把指定长度的内存块复制到另一块内存中而不管内存的中存放的是什么数据
memcpy的声明
void *memcpy(
void *str1,
const void *str2,
size_t n
);
// 作用:从存储区 str2 复制 n 个字符到存储区 str1
返回值
该函数返回一个指向目标存储区 str1 的指针。
strcpy、memcpy、strncpy都会遇到内存重叠的问题
https://blog.csdn.net/magic_world_wow/article/details/79662257
https://blog.csdn.net/weibo1230123/article/details/80382614
4. 链表反转
链表相关问题总是涉及大量指针的操作,链表的反转关键就是调整指针的方向。以下图为例,(a)表示原链表,(b)表示在进行反转的链表。

假设i节点之前都已反转完毕,进行到i时,我们需要知道i的前一个节点h,i节点本身以及(原来)i节点的下一个节点j。相应的这里涉及到3个指针pPre、pNode、pNext,于是写下如下代码
struct ListNode
{// 定义链表节点
int m_nValue;
ListNode* m_pNext;
};
ListNode* ReverseList(ListNode* pHead)
{
ListNode* pReversedHead = nullptr; // 反转后的头指针
ListNode* pNode = pHead; // 从源链表的头结点开始
ListNode* pPrev = nullptr;
while(pNode != nullptr)
{
ListNode* pNext = pNode->m_pNext;
if(pNext == nullptr)
pReversedHead = pNode;
pNode->m_pNext = pPrev;
pPrev = pNode; // 跟新pPre
pNode = pNext; // 反转节点后移
}
return pReversedHead;
}
5. 判断含括号的表达式是否合法
这数与简单的符号匹配问题,使用栈来解决,遇到左括号就入栈,右括号出栈。主要分为四种情况:
- 左右括号数量相同且正确匹配;
- 左右括号数量相同但不能正确匹配;
- 左括号多余;
- 右括号多余。
每次出栈前将当前的右括号和栈顶元素比较,看是否匹配,这是正确匹配的第一个问题;如果还有右括号而栈已经空了,说明右括号多了,如果最后栈不空,说明左括号多了。C++代码实现如下。
//判断括号是否合法--C++
#include <iostream>
#include <string>
#include <stack>
using namespace std;
int Match(char ch1,char ch2)
{// 匹配函数
int t = 0;
if(ch1 == '(' && ch2 == ')') t = 1;
if(ch1 == '[' && ch2 == ']') t = 1;
if(ch1 == '{' && ch2 == '}') t = 1;
return t;
}
bool chkLegal(string A)
{// 检查函数
if(A.size() == 0) return false;
stack<char> Stack; // 定义一个栈容器
for(int i=0;i<A.size();i++){
if(A[i]=='['||A[i]=='('||A[i]=='{')
Stack.push(A[i]); // 左括号入栈
if(A[i]==']'||A[i]==')'||A[i]=='}')
{
if(Stack.empty()) return false; // 如果栈空还有右括号,不匹配
if(!Match(Stack.top(), A[i])) return false; // 如果没有对应匹配
Stack.pop();
}
}
if(Stack.empty()) return true; // 如果数量正确匹配
else return false;
}
int main(int argc, char *argv[])
{
string A = "[a+b*(5-4)]"; // 测试用例A,期望数出1
string B = "[a+b*{5-4)]"; // 测试用例B,期望数出0
string C = "{[())]}"; // 测试用例C,期望输出0
string D = "{[a+b*(5-4)]"; // 测试用例D,期望输出0
string E = ""; // 测试用例D,期望输出0
cout << "String A is: " << chkLegal(A) << endl;
cout << "String B is: " << chkLegal(B) << endl;
cout << "String C is: " << chkLegal(C) << endl;
cout << "String D is: " << chkLegal(D) << endl;
cout << "String E is: " << chkLegal(E) << endl;
return 0;
}
6. Map的底层实现?为什么使用红黑树
C++ STL底层实现
| Name | Description |
|---|---|
| vector | 底层数据结构为数组 ,支持快速随机访问 |
| list | 底层数据结构为双向链表,支持快速增删 |
| deque | 底层数据结构为一个中央控制器和多个缓冲区,详细见STL源码剖析P146,支持首尾(中间不能)快速增删,也支持随机访问 |
| stack | 底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时 |
| queue | 底层一般用list或deque实现,封闭头部即可,不用vector的原因应该是容量大小有限制,扩容耗时 |
| priority_queue | 底层数据结构一般为vector为底层容器,堆heap为处理规则来管理底层容器实现(优先队列) |
| set | 底层数据结构为红黑树,有序,不重复 |
| multiset | 底层数据结构为红黑树,有序,可重复 |
| map | 底层数据结构为红黑树,有序,不重复 |
| multimap | 底层数据结构为红黑树,有序,可重复 |
| hash_set | 底层数据结构为hash表,无序,不重复 |
| hash_multiset | 底层数据结构为hash表,无序,可重复 |
| hash_map | 底层数据结构为hash表,无序,不重复 |
| hash_multimap | 底层数据结构为hash表,无序,可重复 |
map是key:value键值对的组合,map类型通常被称为关联数组(associative array)。与之相对,set就是关键字的简单组合。
map的模板函数
template <class Key,
class Type,
class Traits = less<Key>,
class Allocator=allocator<pair <const Key, Type>>>
class map;
参数
- Key
要存储在映射中的键数据类型。 - Type
要存储在映射中的元素数据类型。 - Traits
一种提供函数对象的类型,该函数对象可将两个元素值作为排序键进行比较,以确定其在映射中的相对顺序。 此参数为可选自变量,默认值是二元谓词 less。
在 C++ 14 中可以通过指定没有类型参数的 std:: less <> 谓词来启用异类查找。 - Allocator
一种表示存储的分配器对象的类型,该分配器对象封装有关映射的内存分配和解除分配的详细信息。 此参数为可选参数,默认值为 allocator<pair<const Key, Type> >。
用法参考
https://www.w3cschool.cn/cpp/cpp-fu8l2ppt.html
https://blog.csdn.net/qq_38984851/article/details/81237993
https://www.jianshu.com/p/834cc223bb57
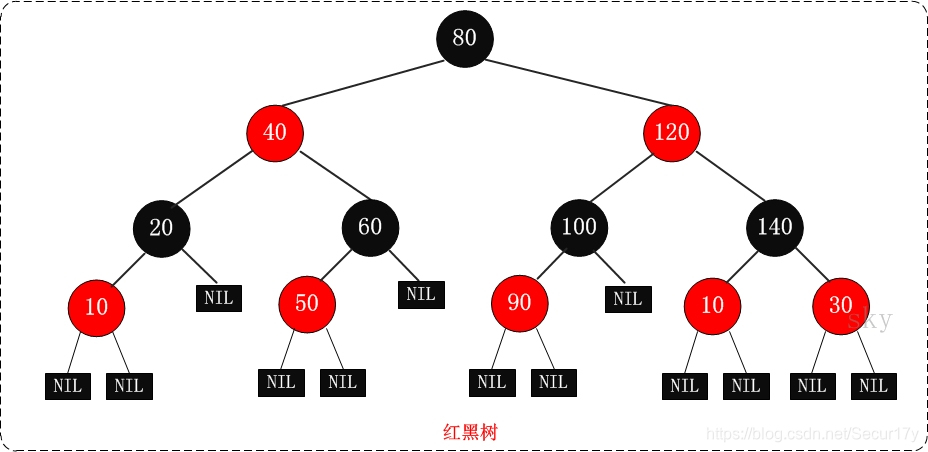
红黑树的特性
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
注意:
a. 特性(3)中的叶子节点,是只为空(NIL或null)的节点。
b. 特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。
红黑树示意图:
参考
https://www.cnblogs.com/xuxinstyle/p/9556998.html
https://www.jianshu.com/p/e136ec79235c
平衡二叉树
- 红黑树是在AVL树的基础上提出来的。
- 平衡二叉树又称为AVL树,是一种特殊的二叉排序树。其左右子树都是平衡二叉树,且左右子树高度之差的绝对值不超过1。
- AVL树中所有结点为根的树的左右子树高度之差的绝对值不超过1。
- 将二叉树上结点的左子树深度减去右子树深度的值称为平衡因子BF,那么平衡二叉树上的所有结点的平衡因子只可能是-1、0和1。只要二叉树上有一个结点的平衡因子的绝对值大于1,则该二叉树就是不平衡的。
红黑树较AVL树的优点
AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance,导致效率下降;红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
所以红黑树在查找,插入删除的性能都是O(logn),且性能稳定,所以STL里面很多结构包括map底层实现都是使用的红黑树。
7. 重载、重写(覆盖)和隐藏的定义与区别
定义
- 重载: 在同一作用域中,同名函数的形式参数(参数个数、类型或者顺序)不同时,构成函数重载
- 重写/覆盖(override): 派生类中与基类同返回值类型、同名和同参数的虚函数重定义,构成虚函数覆盖,也叫虚函数重写。
- 隐藏: 指不同作用域中定义的同名函数构成隐藏(不要求函数返回值和函数参数类型相同)。
override与final
使用override关键字来说明派生类中的虚函数。
把某个函数指点为 final ,意味着任何尝试覆盖该函数的操作都将引发错误。
区别
重载和重写的区别:
(1)范围区别:重写和被重写的函数在不同的类中,重载和被重载的函数在同一类中。
(2)参数区别:重写与被重写的函数参数列表一定相同,重载和被重载的函数参数列表一定不同。
(3)virtual的区别:重写的基类必须要有virtual修饰,重载函数和被重载函数可以被virtual修饰,也可以没有。
隐藏和重写,重载的区别:
(1)与重载范围不同:隐藏函数和被隐藏函数在不同类中。
(2)参数的区别:隐藏函数和被隐藏函数参数列表可以相同,也可以不同,但函数名一定同;当参数不同时,无论基类中的函数是否被virtual修饰,基类函数都是被隐藏,而不是被重写。
| 内容 | 作用域 | virtual | 函数名 | 形参列表 | 返回值类型 |
|---|---|---|---|---|---|
| 重载 | 相同 | 可有可无 | 相同 | 不同 | 可同可不同 |
| 隐藏 | 不同 | 可有可无 | 相同 | 可同可不同 | 可同可不同 |
| 重写/覆盖 | 不同 | 有 | 相同 | 不同 | 相同 |
参考
https://blog.csdn.net/weixin_39640298/article/details/88725073
https://www.cnblogs.com/zhangjxblog/p/8723291.html
8. virtual关键字是为了实现什么,具体怎么实现?
当一个方法声明包含virtual修饰符,这个方法就是虚方法。如果没有virtual修饰符,那么就不是虚方法。C++中的虚函数(Virtual Function)的作用主要是实现了多态的机制,虚函数是通过一张虚函数表(Virtual Table)来实现的。
9. Hash表及底层实现机制
在数组,线性表、树等数据结构中,记录的查找效率依赖与比较次数。如果能将关键字和储存位置建立一个映射关系,那么就可是实现不经过任何比较,一次便能得到所查记录。即,如果存在映射关系 能确定给定值 的位置,那么可以称这个映射关系 为哈希(Hash)函数,由这个思想建立的表为哈希表。
哈希函数构造方法
- 直接定址法
- 数字分析法
- 平方取中法
- 折叠法
- 除留取余法
- 随机法
冲突处理方法
- 开放定址法再哈希法
- 链地址法
- 建立一个公共溢出区
底层实现
数组+链表,用链表处理冲突。如果冲突元素较多,可将链表转换为红黑树来提高查找性能能
参考
https://blog.csdn.net/sinat_35866463/article/details/83316487
https://blog.csdn.net/ACmeinan/article/details/79595960
https://blog.csdn.net/qq_41891803/article/details/82787112
https://www.nowcoder.com/discuss/3098?pos=28&type=0&order=0
https://www.kanzhun.com/gsmsh10802673.html
https://www.nowcoder.com/discuss/116569?type=2
10. BSF(Breadth First Search)之中国象棋跳马问题
题目描述
现在棋盘的大小不一定,由p,q给出,并且在棋盘中将出现障碍物(限制马的行动,与象棋走法相同)
输入
第一行输入n表示有n组测试数据。
每组测试数据第一行输入2个整数p,q,表示棋盘的大小(1<=p,q<=100)。
每组测试数据第二行输入4个整数,表示马的起点位置与终点位置。(位置的取值范围同p,q)
第三行输入m表示图中有多少障碍。
接着跟着m行,表示障碍的坐标。
输出
马从起点走到终点所需的最小步数。
如果马走不到终点,则输入“can not reach!”
C++代码
//中国象棋中的跳马问题
#include <cstdio>
#include <cstring>
#include <string>
#include <iostream>
#include <queue>
#include <algorithm>
using namespace std;
struct position
{// 位置结构体
int x; // row
int y; // col
};
struct node
{// 节点属性
int x; // 节点位置信息
int y;
int sum; // 到达该节点的距离信息
};
int vis[109][109]; // 访问数组
int barrier[109][109]; // 障碍数组
// dir[]和cir[]目标位置信息和障碍信息是一个相对值,即将输入的起点作为原点考虑
position dir[8]={{-2,-1},{-2,1},{-1,2},{1,2},{2,1},{2,-1},{1,-2},{-1,-2}}; // 如果以马当前位置为坐标原点,则该数组表示可以到达的八个方向的点
position cir[8]={{-1,0},{-1,0},{0,1},{0,1},{1,0},{1,0},{0,-1},{0,-1}}; // 分别对应上述目标点的障碍
queue<node> que; // 辅助队列
int ans,n,m,sx,sy,ex,ey,flag; // ans:目标路径长度
// m,n确定期盼
// (sx,sy)即起点坐标
// (ex.ey)即要到达的终点坐标
// flag:能否到达的标记
int is_right(int a,int b)
{// 判断位置信息
if(a>0&&a<=n&&b>0&&b<=m)
return 1;
return 0;
}
int BFS()
{//广度优先搜索
int row,col,tx,ty;
ans=flag=0; // 距离和标记初始化
node t,m; // 定义两个节点,t为起始节点,m为遍历辅助节点
t.x=sx,t.y=sy,t.sum=ans; // t为起始节点
que.push(t); // 节点入队
vis[sx][sy]=1; // 标记已经走过的点
while(!que.empty())
{
t=que.front(); //队首节点
que.pop(); // 出队
row=t.x,col=t.y;// 当前队首节点的坐标信息
if(row==ex && col==ey)
{// 如果节点为终点
flag=1;
ans=t.sum;
return ans;
}
for(int i=0;i<8;i++)
{
tx=t.x+dir[i].x; // 遍历访问节点坐标信息
ty=t.y+dir[i].y;
if(!barrier[t.x+cir[i].x][t.y+cir[i].y])
{//没有障碍
if(is_right(tx,ty) &&!vis[tx][ty] && !barrier[tx][ty])
{// 节点合法,未被访问过且节点无障碍
m.x=tx; // 记录访问节点信息
m.y=ty;
m.sum=t.sum+1; // 距离增加
que.push(m); // 访问节点入队
vis[tx][ty]=1; // 访问标志数组置1,表示以访问
}
}
}
}
}
int main(void)
{
int t,ob,obx,oby; // t:测试组数
// ob障碍数
// (obx,oby)障碍坐标
cin>>t; // 输入测试数据组数t
while(t--)
{
while(!que.empty()) // 如果队列非空
que.pop();
memset(vis,0,sizeof(vis)); // 初始化访问数组为0,extern void *memset(void *buffer, int c, int count)
memset(barrier,0,sizeof(barrier)); // 初始化障碍数组为0
scanf("%d%d%d%d%d%d%d",&n,&m,&sx,&sy,&ex,&ey,&ob); // nm确定棋盘大小,1<=n,m<=100
// 起点坐标(sx,sy),终点坐标(ex,ey)
// 障碍数量ob
for(int i=0;i<ob;i++)
{
scanf("%d%d",&obx,&oby); // 输入障碍坐标
vis[obx][oby]=1; // 访问标记置1
barrier[obx][oby]=1; // 障碍标记置1
}
BFS(); // 调用算法,起点信息(sx,sy)已经输入
if(flag==1)
printf("%d",ans);
else
printf("can not reach!");
if(t)
printf("\n");
}
return 0;
}
代码的管关键是是BSF()实现部分,需要理解好访问标志数组vis[]和辅助队列que的作用
Reference:https://blog.csdn.net/qq_41759198/article/details/81510147
11.斐波那契数列之青蛙跳台阶的问题
题目描述
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法
这是典型属于求Fibonacci第n项的问题
方法一:递归
#include <iostream>
#include <cstdio>
using namespace std;
long long Fibonacci_Recursion(unsigned int n)
{
if(n <= 0)
return 0;
if(n == 1)
return 1;
return Fibonacci_Recursion(n - 1) + Fibonacci_Recursion(n - 2);
}
int main()
{
int n;
while(cin>>n)
cout << Fibonacci_Recursion(n) << endl;
return 0;
}
虽然教科书上多以递归的方式讲解,因为很直观,但在实际操作中递归会有大量重复的计算,导致算法时间效率很低
方法二:循环
#include <iostream>
#include <cstdio>
using namespace std;
long long Fibonacci_Loop(unsigned int n)
{
int result[2] = {0, 1}; // 0级和1级
if(n < 2)
return result[n];
long long fibNMinusOne = 1;
long long fibNMinusTwo = 0; // 青蛙问题此处设为 1
long long fibN = 0;
for(unsigned int i = 2; i <= n; ++ i)
{
fibN = fibNMinusOne + fibNMinusTwo;
fibNMinusTwo = fibNMinusOne;
fibNMinusOne = fibN;
}
return fibN;
}
int main()
{
int n;
while(cin>>n)
cout << Fibonacci_Recursion(n) << endl;
return 0;
}
以上两种得出的结果是斐波那契数列:1,1,2,3,5,8…,但是注意,实际在处理青蛙跳的时候1到n阶台阶应是 1,2,3,5,8…,所以处理是要具体考虑。
青蛙跳台阶的扩展
一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
数学推理
So
C++代码
#include <iostream>
#include <cstdio>
using namespace std;
long long Jump(int n)
{
if(n <= 0)
return 0;
else if(n == 1)
return 1;
else
return 2*Jump(n-1);
}
int main()
{
int n;
while(cin>>n)
cout << Jump(n) << endl;
return 0;
}
12. 顶层const和底层const
指针本身是一个对象,它又可以指向另外一个对象。因此,指针本身是不是常量以及指针所指的是不是一个常量就是两个相互独立的问题。用名词顶层const(top-level const)表示指针本身是常量,而用名词底层 const(low-level const)。
更一般的,顶层 const可以表示任意的对象是常量,这一点对任何数据类型都适用,如算术类型、类、指针等。指针类型既可以是顶层 const也可以是底层 const。
int i = 0;
int *const p1 = &i; // 不能改变p1的值,这是一个顶层 const
const int ci = 42; // 不能改变ci的值,这是一个顶层 const
const int *p2 = &ci; // 允许改变p2的值,这是一个底层 const
const int *const p3 = p2; // 靠右的是顶层 const,靠左的是底层 const
const int &r = ci; // 用于声明引用的 const都是底层 const
当执行对象拷贝操作时,常量是顶层const还是底层const区别明显。其中顶层const不受什么影响:
i = ci; // 正确:拷贝ci的值,ci是一个顶层const,对此操作无影响
p2 = p3; // 正确:p2和p3指向的对象类型相同,p3顶层 const的部分不受影响
另一方面,底层const的限制却不能忽视。当执行对象的拷贝操作时,拷入和拷出的对象必须具有相同的底层const资格,或者两个对象的数据类型必须能够相互转换。一般来说,非常量可一转换为常量,反之则不行:
int *p = p3; // 错误:p3包含底层 const的定义,而p没有
p2 = p3; // 正确:p2和p3都是底层 const
p2 = &i; // 正确:int*能转换成 const int*
int &r = ci; // 错误:普通的int&不能绑定到int常量上
const int &r2 = i; // 正确:const int& 可以绑定到int常量上
参考
《C++ Primer》
https://blog.csdn.net/qq_19528953/article/details/50922303
13. 可以用memcmp比较两个struct吗?会有什么问题?
memcmp()函数是逐个字节进行比较的,而struct存在字节对齐,字节对齐时补的字节内容是随机的,会产生垃圾值。所以在一下两个前提条件下比较是没有问题的
- 结构体成员都是同样字节长度的数据类型,即长度一致,不会由字节对齐而产生垃圾值;
- 如果结构体在赋值前调用memset进行了清零初始化操作,那么字节对齐是填充的内容均是0。
例1 直接使用memcmp()比较
#include <iostream>
#include <string.h>
using namespace std;
struct foo
{
short a;
int b;
};
int main()
{
foo c,d;
c.a = 1;c.b = 2;
d.a = 1;d.a = 2;
if (0 == memcmp(&c,&d,sizeof(c)))
{
cout<<"equal"<<endl;
}
else
cout<<"No-equal"<<endl;
return 0;
}
输出结果
No-equal
Press any key to continue.
例2 使用memset()初始化
#include <iostream>
#include <string.h>
using namespace std;
struct foo
{
short a;
int b;
};
int main()
{
foo c,d;
memset(&c,0,sizeof(c));
memset(&d,0,sizeof(d));
// c.a = 1;c.b = 2;
// d.a = 1;d.a = 2;
if (0 == memcmp(&c,&d,sizeof(c)))
{
cout<<"equal"<<endl;
}
else
cout<<"No-equal"<<endl;
return 0;
}
输出结果
equal
Press any key to continue.
因此,更好的建议方法是重载操作符==
#include <iostream>
using namespace std;
struct foo {
short a;
int b;
bool operator==(const foo& rhs) // 操作运算符重载
{
return( a == rhs.a) && (b == rhs.b);
}
};
int main(int argc,char* argv[])
{
foo a,b;
a.a = 1;a.b = 2;
b.a = 1;b.b = 2;
if (a == b)
{
cout<<"equal"<<endl;
}
else
cout<<"No-equal"<<endl;
return 0;
}
输出结果
equal
Press any key to continue.
14. 堆、栈的区别
堆(Heap)与栈(Stack)是开发人员必须面对的两个概念,在理解这两个概念时,需要放到具体的场景下,因为不同场景下,堆与栈代表不同的含义。一般情况下,有两层含义:
(1)程序内存布局场景下,堆与栈表示的是两种内存管理方式;
- 分配方式:堆是动态分配;栈是静态或动态分配
- 管理方式:堆由程序员来释放;栈有OS自动分配释放
- 存储内容:堆存放内容由程序员填充;栈存放函数返回地址、相关参数、局部变量和寄存器等
- 空间大小:每个进程拥有的栈的大小要远远小于堆的大小。
- 分配效率:堆由C/C++库函数支持,实现复杂;栈由操作系统自动分配,会在硬件层级对栈提供支持,效率高
- 生长方向:堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
(2)数据结构场景下,堆与栈表示两种常用的数据结构。
- 操作方式
15. 堆排序和快排的区别?
快速排序(Quick Sort)是对冒泡排序的一种改进,应用了分治的思想。通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序(递归),以达到整个序列有序。
C++代码
#include <cstdio>
#include<cstdlib>
void quickSort(int* arr,int low,int high);
int Partition(int* arr,int low,int high);
int main(int argc,char* argv[])
{
int i,a[]={4,2,6,9,1,3,5};
int length = sizeof(a)/sizeof(a[0]);
quickSort(a,0,length-1);
printf("After sorted: ");
for(i=0;i<length;i++)
printf("%d ",a[i]);
}
void quickSort(int* arr,int low,int high)
{
if(low<high)
{
int pivotloc = Partition(arr,low,high);
quickSort(arr,low,pivotloc-1);
quickSort(arr,pivotloc+1,high);
}
}
int Partition(int* arr,int low,int high)
{
int pivotkey = arr[low];
while(low<high)
{
while(low<high && arr[high] >= pivotkey)
--high;
arr[low] = arr[high];
while(low<high && arr[low] <= pivotkey)
++low;
arr[high] = arr[low];
}
arr[low] = pivotkey;
return low;
}
堆排序(Heap Sort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。
简单选择排序的基本思想:每一趟都是在(n-i+1),(i=1,2,3…n-1)个记录中选取关键字最小的记录作为有序序列的第i个记录。总的时间复杂度为
#include <stdio.h>
#include <stdlib.h>
void SimpleSelectSort(int *a,int n)
{
int i,j,mins,temp;
if(n <= 0) return -1;
for(i = 0; i < n; i++)
{
mins = i;
for(j = i+1; j < n; j++) // 从后面n-i+1个中找到最小的元素的下标
if(a[j] < a[mins])
mins = j;
if(i != mins)
{// 将最小元素进行交换
temp = a[i];
a[i] = a[mins];
a[mins] = temp;
}
}
}
int main(int argc,char* argv[])
{
int i,n = 8;
int a[] = {3,6,4,2,5,1,8,7}; // 测试代码
printf("Before Sorted order:\t");
for(i = 0; i < n;i++)
printf("%d ",a[i]);
SimpleSelectSort(a, n);
printf("\nAfter Sorted order:\t");
for(i = 0; i < n; i++)
printf("%d ",a[i]);
printf("\n");
return 0;
}
堆的定义:n个元素的序列
当且仅当满足如下关系时,称之为堆。
若将此序列所存储的向量
看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶子结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。(注意不要和二叉排序树混淆)
对于一个小顶堆,若在输出堆顶的最小值之后, 使剩余n-1个元素的序列再次筛选形成一个堆,再输出次小值,由此反复进行,便能得到一个有序的序列,这个过程就称之为堆排序。
从上面对于堆排序的叙述我们知道,进行一次堆排序,我们要解决两个问题:
- 如何初始化一个堆
- 如何在输出堆顶元素之后,调整堆内元素,使其再次形成一个堆。
下面给出一个c的参考代码
#include<stdio.h>
int c=0; // 用于记录排序进行的交换次数
/*heapadjust()函数的功能是实现从a[m]到a[n]的数据进行调整,使其满足大顶堆的特性*/
/*a[]是待处理的数组,m是起始坐标, n是终止坐标*/
void heapadjust(int a[], int m, int n)
{// 调整是从上往下调整
int i, temp;
temp=a[m]; // 想象一下从根节点开始调整,即m=1;
for(i=2*m;i<=n;i*=2)//从m开始,比较它的左孩子和右孩子
{
/*如果左孩子小于右孩子,则将i++,这样i(如果右孩子大,由于前面进行了i++的操作,
实际是 i+1,也就是右孩子的索引,反之不进行 i++ 操作, 也就是左孩子的索引)的值
就是最大孩子的下标值*/
if(i+1<=n && a[i]<a[i+1]) i++;
/*如果最大的孩子小于temp,则不做任何操作,退出循环;否则交换a[m]和
a[i]的值,将最大值放到a[i]处*/
if(a[i]<temp) break;
a[m]=a[i];
m=i;
}
a[m]=temp;
}
void crtheap(int a[], int n)//初始化create一个大顶堆
{
int i;
for(i=n/2; i>0; i--)//n/2为最后一个双亲节点,依次向前建立大顶堆
{
heapadjust(a, i, n); // 调整
}
}
/*swap()函数的作用是将a[i]和a[j]互换*/
void swap(int a[], int i, int j)
{
int temp;
temp=a[i];
a[i]=a[j];
a[j]=temp;
c++;
}
void heapsort(int a[], int n)
{
int i;
crtheap(a, n);
for(i=n; i>1; i--)
{
swap(a, 1, i);//将第一个数,也就是从a[1]到a[i]中的最大的数,放到a[i]的位置
heapadjust(a, 1, i-1);//对剩下的a[1]到a[i-1],再次进行堆排序,选出最大的值,放到a[1]的位置
}
}
int main(void)
{
int i;
int a[10]={-1,5,2,6,0,3,9,1,7,4};
printf("排序前:");
for(i=1;i<10;i++)
{
printf("%d ",a[i]);
}
heapsort(a, 9);
printf("\n\n共交换数据%d次\n\n", c);
printf("排序后:");
for(i=1;i<10;i++)
printf("%d ",a[i]);
printf("\n");
return 0;
}
堆排序的时间复杂度为
参考
https://blog.csdn.net/kuweicai/article/details/54710409
https://blog.csdn.net/yuzhihui_no1/article/details/44258297#
16. 可变参数函数的定义及实现
- 1)首先在函数里定义一个va_list型的变量,这里是arg_ptr,这个变量是指向参数的指针.
- 2)然后用va_start宏初始化变量arg_ptr,这个宏的第二个参数是第一个可变参数的前一个参数,是一个固定的参数.
- 3)然后用va_arg返回可变的参数,并赋值给整数j. va_arg的第二个参数是你要返回的参数的类型,这里是int型.
- 4)最后用va_end宏结束可变参数的获取.然后你就可以在函数里使用第二个参数了.如果函数有多个可变参数的,依次调用va_arg获取各个参数.
printf 函数的实现
C中的定义:
int printf(
const char *format [,
argument]...
);
stdio.h中的声明:
_Check_return_opt_
_CRT_STDIO_INLINE int __CRTDECL printf(
_In_z_ _Printf_format_string_ char const* const _Format,
...)
#if defined _NO_CRT_STDIO_INLINE
;
#else
{
int _Result;
va_list _ArgList;
__crt_va_start(_ArgList, _Format);
_Result = _vfprintf_l(stdout, _Format, NULL, _ArgList);
__crt_va_end(_ArgList);
return _Result;
}
#endif
通俗一点
int printf(char *fmt, ...)
{
int n;
va_list args;
va_start(args, fmt);
n = vsprintf(sprint_buf, fmt, args);
va_end(args);
return n;
//va_start(arg,format),初始化参数指针arg,将函数参数format右边第一个参数地址赋值给arg
//format必须是一个参数的指针,所以,此种类型函数至少要有一个普通的参数,
//从而提供给va_start ,这样va_start才能找到可变参数在栈上的位置。
//va_arg(arg,char),获得arg指向参数的值,同时使arg指向下一个参数,char用来指名当前参数型
//va_end 在有些实现中可能会把arg改成无效值,这里,是把arg指针指向了 NULL,避免出现野指针
}
参考
https://blog.csdn.net/weixin_34341229/article/details/92583270
https://blog.csdn.net/c1204611687/article/details/86133774
https://blog.csdn.net/huaweitman/article/details/38348655
https://wenku.baidu.com/view/c555861ea8114431b90dd85b.html
17. 缓冲出溢出、内存泄漏、内存溢出
顾名思义,缓冲区溢出的含义是为缓冲区提供了多于其存储容量的数据,就像往杯子里倒入了过量的水一样。
由于栈是低地址方向增长的,因此局部数组buffer的指针在缓冲区的下方。当把data的数据拷贝到buffer内时,超过缓冲区区域的高地址部分数据会“淹没”原本的其他栈帧数据,根据淹没数据的内容不同,可能会有产生以下情况:
-
淹没了其他的局部变量。如果被淹没的局部变量是条件变量,那么可能会改变函数原本的执行流程。这种方式可以用于破解简单的软件验证。
-
淹没了ebp的值。修改了函数执行结束后要恢复的栈指针,将会导致栈帧失去平衡。
-
淹没了返回地址。这是栈溢出原理的核心所在,通过淹没的方式修改函数的返回地址,使程序代码执行“意外”的流程!
-
淹没参数变量。修改函数的参数变量也可能改变当前函数的执行结果和流程。
-
淹没上级函数的栈帧,情况与上述4点类似,只不过影响的是上级函数的执行。当然这里的前提是保证函数能正常返回,即函数地址不能被随意修改(这可能很麻烦!)。
如果在data本身的数据内就保存了一系列的指令的二进制代码,一旦栈溢出修改了函数的返回地址,并将该地址指向这段二进制代码的其实位置,那么就完成了基本的溢出攻击行为。
参考
https://www.cnblogs.com/kexianting/p/8805591.html
https://blog.csdn.net/weixin_37749370/article/details/81662401
https://www.cnblogs.com/clingyu/p/8546626.html
内存泄露:程序在向系统申请分配内存空间后(new),在使用完毕后未释放。结果导致一直占据该内存单元,我们和程序都无法再使用该内存单元,直到程序结束,这是内存泄露。
内存溢出:程序向系统申请的内存空间超出了系统能给的。比如内存只能分配一个int类型,我却要塞给他一个long类型,系统就出现oom。
参考
https://blog.csdn.net/zkl99999/article/details/45486035
https://www.jianshu.com/p/86643b5afa6a
操作系统
1. 同步、死锁
| 同步机制规则 | 产生死锁的必要条件 | 处理死锁地方法 |
|---|---|---|
| 空闲让进 | 互斥条件 | 预防死锁 |
| 忙则等待 | 请求和保持条件 | 避免死锁 |
| 有限等待 | 不可抢占条件 | 检测死锁 |
| 让权等待 | 循环等待条件 | 接触死锁 |
2. 进程间常用的通信方式有哪些?
进程间通信(IPC,InterProcess Communication)是指在不同进程之间传播或交换信息。
IPC的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket、Streams等。其中 Socket和Streams支持不同主机上的两个进程IPC。
- 管道:通常指无名管道,是 UNIX 系统IPC最古老的形式,使用pipe文件。
- FIFO:也称为命名管道,它是一种文件类型。
- 消息队列:是消息的链接表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
- 信号量(semaphore):与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
- 共享内存(Shared Memory):指两个或多个进程共享一个给定的存储区。
- 套接字:包含基于文件型和基于网络型。其优势在于,它不仅适用于同一台计算机内部的进程通信,也适用与网络环境中不同计算机间的进程通信。
参考
https://blog.csdn.net/wangdd_199326/article/details/81321562
https://blog.csdn.net/wh_sjc/article/details/70283843
3. epoll和select/poll的区别
均为I/O复用的处理方法。
参考《Unix网络编程》
https://www.cnblogs.com/aspirant/p/9166944.html
https://blog.csdn.net/a1414345/article/details/73385556
4. 进程与线程的区别
进程的典型定义
(1) 进程是程序的一次执行。
(2) 进程是一个程序及其数据在处理及上顺序执行时所发生的活动。
(3) 进程是具有独立功能额程序在一个数据集合上运行的过程,踏实系统进行资源分配和调度的一个独立单位。(在引入线程的OS中,把线程作为独立调度和分派的单位)
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
参考
《计算机操作系统》
https://blog.csdn.net/kuangsonghan/article/details/80674777
https://blog.csdn.net/wsq119/article/details/82154305
线程,进程。多进程,多线程。并发,并行的区别
多进程和多线程的区别及适用场景
并发处理请求—多进程、多线程、异步
5. 系统调用与函数调用
系统调用:操作系统为用户提供了一系列接口,这些接口提供了对硬件设备的操作。举个例子我们用printf想终端打印hello world,程序中调用printf,而printf实际上调用的是write,从而打印信息到终端。
库函数:库函数是对系统调用的封装。系统调用作为内核提供给用户的接口,它执行的效率是比较高效和精简的,但有时候我们需要对获取的信息进行一些处理,我们把这些处理过程封装起来提供给程序员,有利于编码。
库函数有可能包含一个系统调用,有可能包含几个系统调用,也有可能不包含系统调用,一些简单的操作就涉及到内核的功能。
参考
https://blog.csdn.net/qq_31759205/article/details/80602357
https://blog.csdn.net/qq_41727218/article/details/88218308
6. Linux信号量
信号的名字和编号:
每个信号都有一个名字和编号,这些名字都以“SIG”开头,例如“SIGIO ”、“SIGCHLD”等等。
信号定义在signal.h头文件中,信号名都定义为正整数。
具体的信号名称可以使用kill -l来查看信号的名字以及序号,信号是从1开始编号的,不存在0号信号。kill对于信号0又特殊的应用。

常用的:
SIGKILL 9 TermKILL信号
SIGTERM 15 Term强制中止信号
信号的处理:
信号的处理有三种方法,分别是:忽略、捕捉和默认动作
7.可重入函数,线程安全
线程安全:一个函数被称为线程安全的(thread-safe),当且仅当被多个并发进程反复调用时,它会一直产生正确的结果。如果一个函数不是线程安全的,我们就说它是线程不安全的(thread-unsafe)。我们定义四类(有相交的)线程不安全函数。
可重入函数:可重入函数是线程安全函数的一种,其特点在于它们被多个线程调用时,不会引用任何共享数据。
参考
https://blog.csdn.net/ypt523/article/details/80380272
https://www.cnblogs.com/xiangshancuizhu/archive/2012/10/22/2734497.html
8. 阻塞与非阻塞
阻塞是指在函数执行时如果条件不满足,程序将永远停在那条函数那里不在往下执行,而非阻塞则是函数不管条件是否满足都会往下执行.
9. 内存管理
CPU三类总线
- 地址总线的宽度决定了CPU的寻址能力
- 数据总线的宽度决定了CPU与其他器件进行数据传送时的一次数据传送量
- 控制总线的宽度决定了CPU对系统中其他器件的控制能力
将各类存储器看作一个逻辑存储器
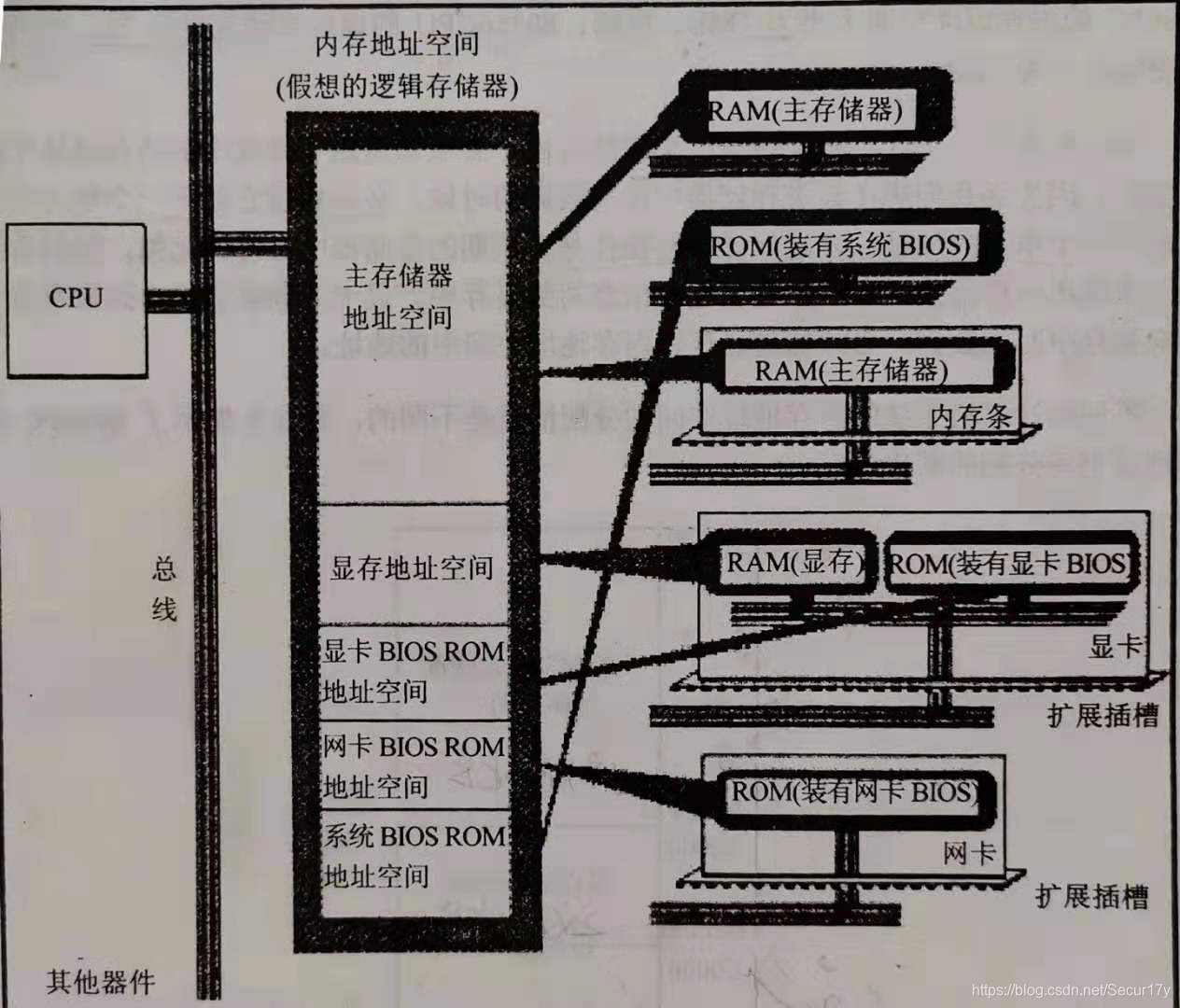
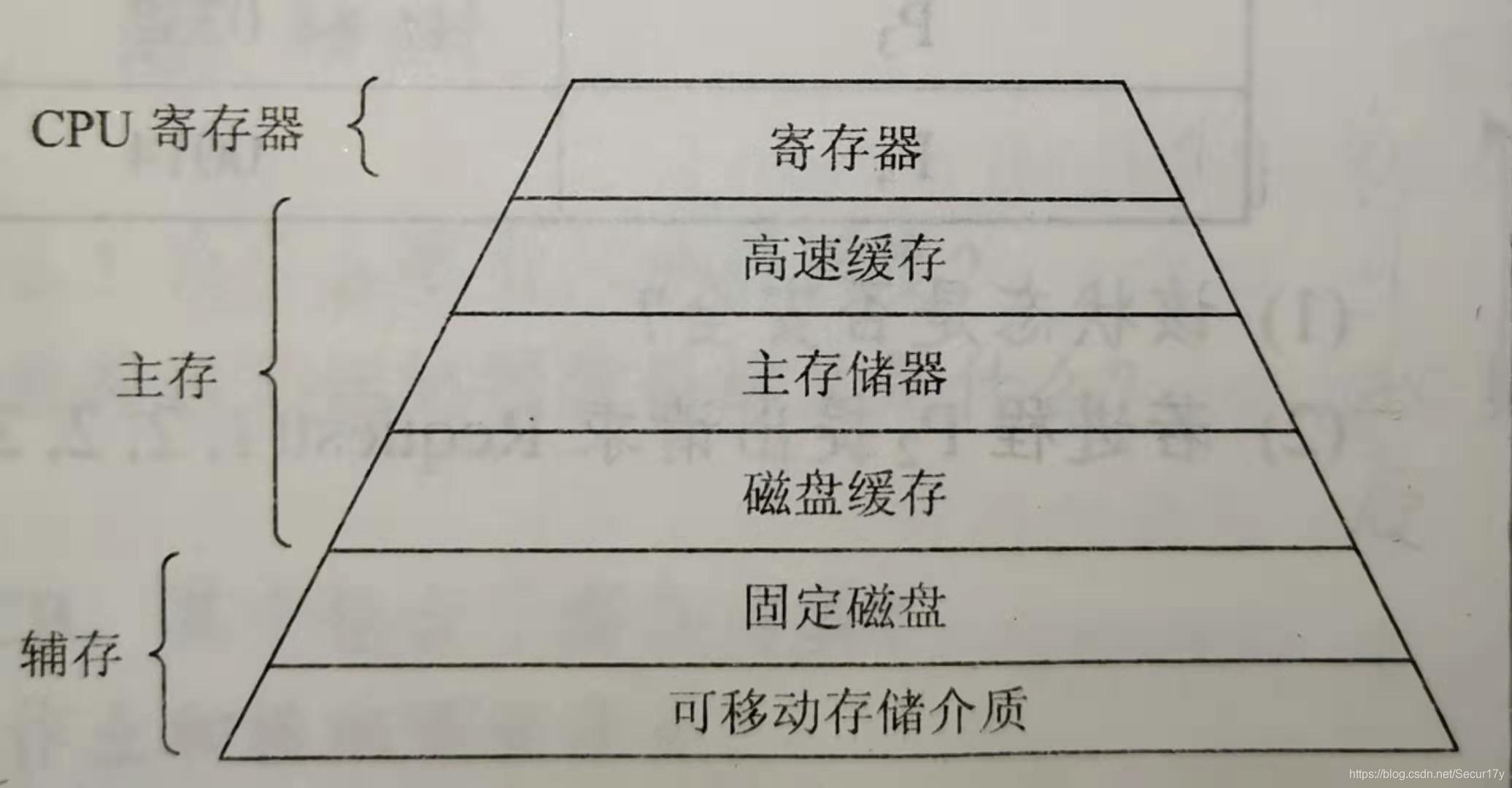
对通用计算机而言,存储层次至少应该具有三个层级:最高层为CPU寄存器,中间为主存,最底层是辅存。在较高档的计算机中们还可以根据具体的功能细分为寄存器、高速缓存、主存储器、磁盘缓存、固定磁盘、可移动存储介质等6层。
内存分配策略包括连续分配、分页、分段、段页式。
网络知识
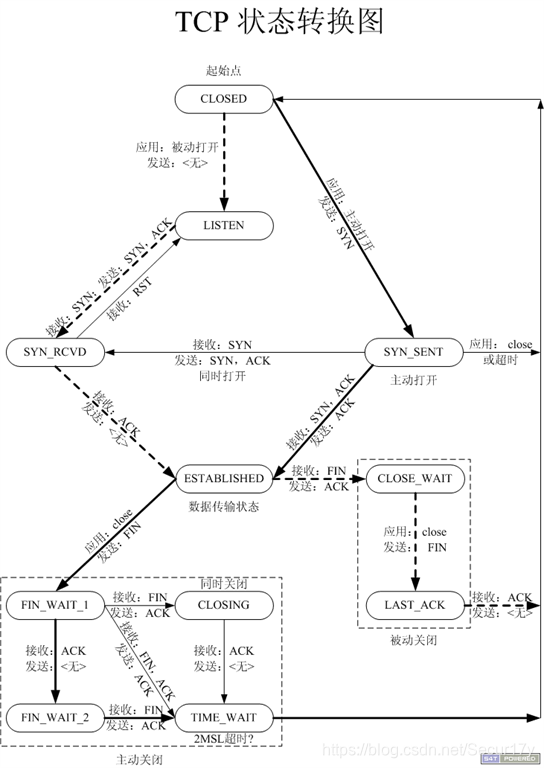
1. TCP有限状态机
握手
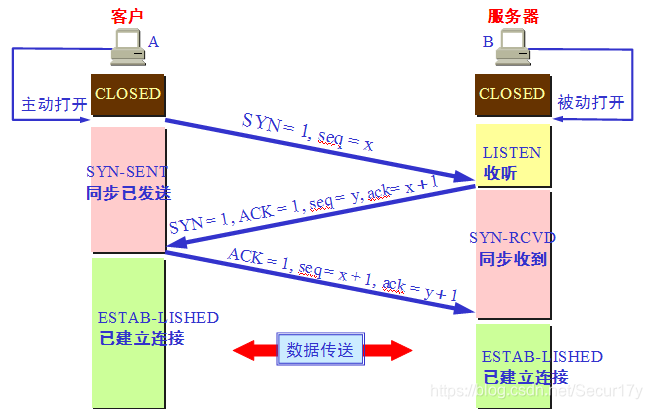
挥手
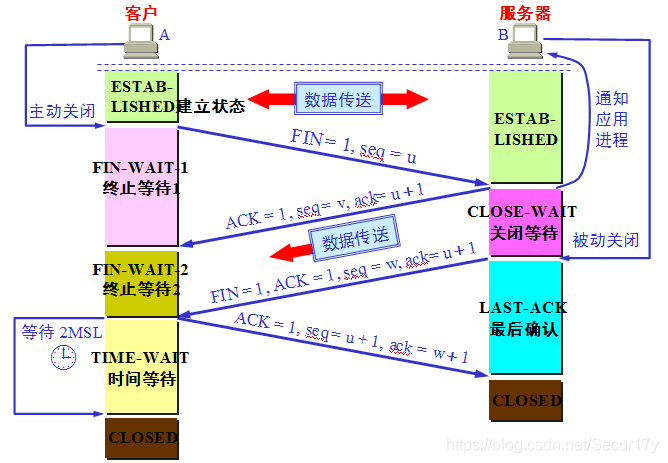
有限状态机
为什么需要三次握手(四次挥手后为什么还要等待2MSL)
为什么A还要发送一次确认呢?这主要是为了防止已失效的连接请求报文段突然又传送到了B,因而产生错误。
所谓已失效的连接请求报文段是这样产生的。A发送连接请求,但因连接请求报文丢失而未收到确认,于是A重发一次连接请求,成功后建立了连接。数据传输完毕后就释放了连接。现在假定A发出的第一个请求报文段并未丢失,而是在某个网络节点长时间滞留了,以致延误到连接释放以后的某个时间才到达B。本来这是一个早已失效的报文段。但B收到此失效的连接请求报文段后,就误以为A又发了一次新的连接请求,于是向A发出确认报文段,同意建立连接。假如不采用三次握手,那么只要B发出确认,新的连接就建立了。
由于A并未发出建立连接的请求,因此不会理睬B的确认,也不会向B发送数据。但B却以为新的运输连接已经建立了,并一直等待A发来数据,因此白白浪费了许多资源。
采用TCP三次握手的方法可以防止上述现象发生。例如在刚才的情况下,由于A不会向B的确认发出确认,连接就不会建立。
参考
《计算机网络》
https://blog.csdn.net/xy010902100449/article/details/48274635
