转载一(IO流常用API):https://blog.csdn.net/eternal1d/article/details/77189482
【I/O流】
Input/Output:输入输出机制
输入机制:允许java程序获取外部设备的数据(磁盘,光盘,网络等)。
输出机制:保留java程序中的数据,输出到外部设备上(磁盘,光盘等)。
【可以看出,IO的入出是以java程序为第一人称的】
IO各种之间的关系
先看张图:
流的分类:
通过不同的方法,可以对于进行分类。
1.按照功能来划分:
输入流:只能从中读取数据,而不能向其写入数据。
输出流:只能向其写入数据,而不能从中读取数据。
2.按照处理单元来划分
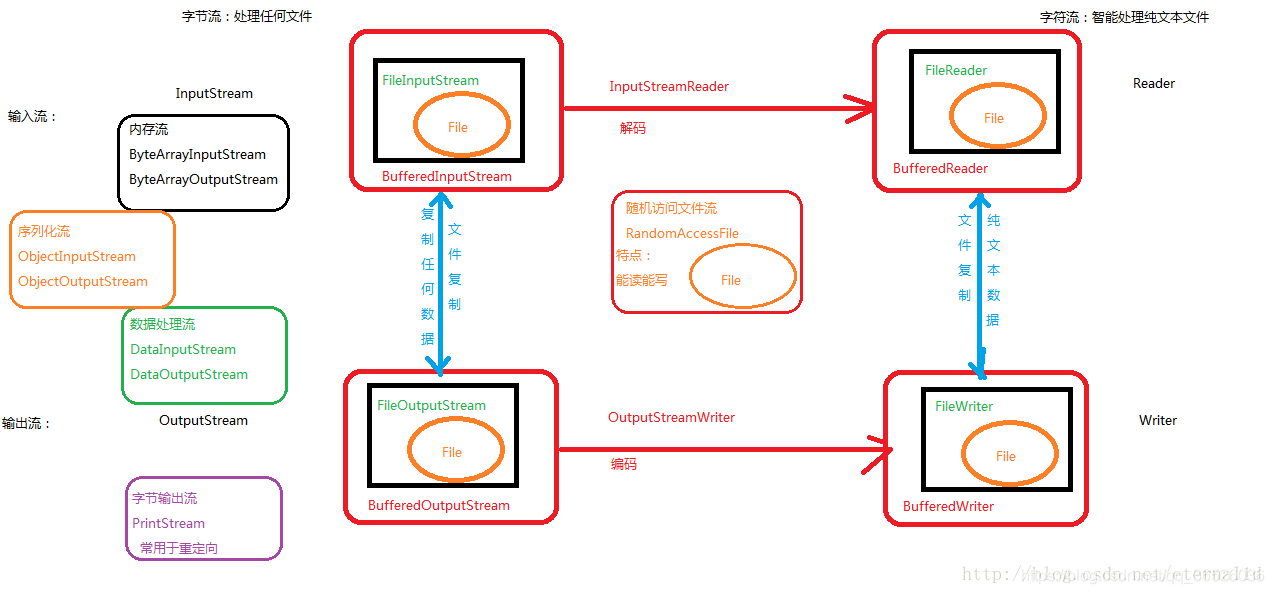
字节流和字符流操作的方式基本上完全相同。操作的数据单元不同
字节流:操作的是8位的字节 InputStream/OutputStream 作为字节流的基类
字符流:操作的是16位的字符 Reader/Writer 作为字符流的基类
3.按照角色进行划分
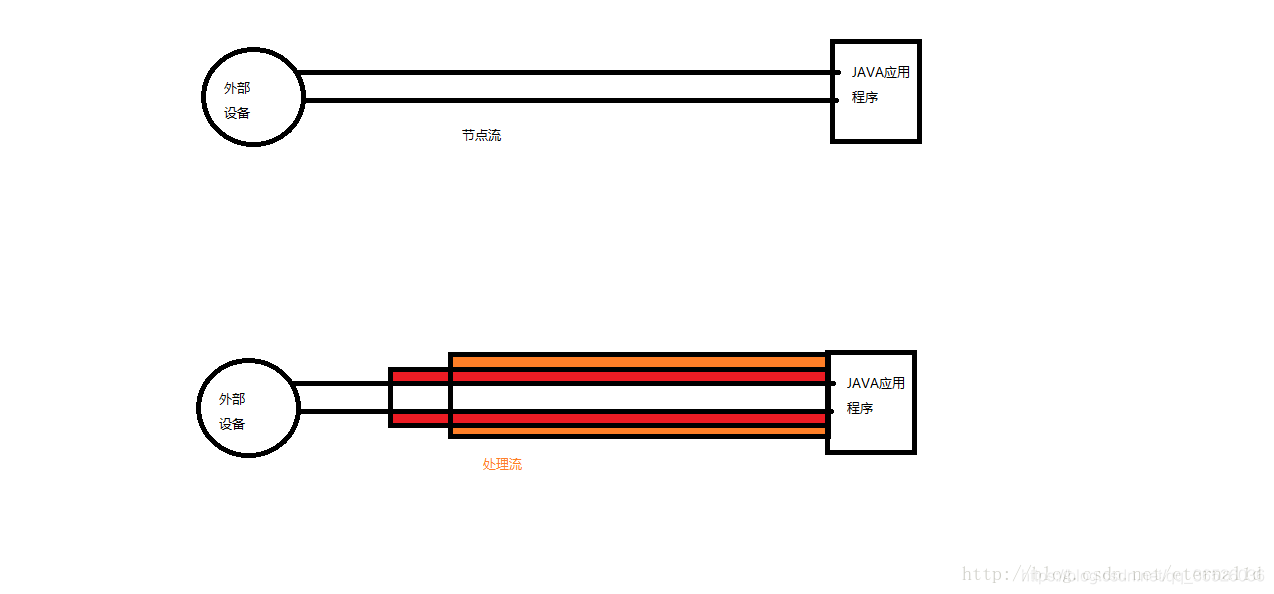
节点流:可以直接从/向外部设备读取/写入数据的流,称之为节点流,节点流也被称之为低级流。
处理流:对于已经存在的流进行了连接和封装,扩展了原来的读/写的功能。处理流也被称之为高级流。
java的io包当中包括40多个流,他们都有紧密的联系,和使用的规律,这些流都源于4个抽象基类。
InputStream / Reader :所有的输入流的基类,前者是字节输入流,后者是字符输入流。
OutputStream/Writer :所有输出流的基本,前者是字节输出流,后者是字符输出流。
流的操作步骤:
文件字节输入流读取文件内容的步骤:
- 1.创建流对象
- 2.创建一个缓存字节的容器数组
- 3.定义一个变量,保存实际读取的字节数
- 4.循环读取数据
- 5.操作保存数据的数组
- 6.关闭流
public class FileInputStreamDemo01 {
public static void main(String[] args) {
File file = new File("C:\\Users\\Administrator\\Desktop\\2017-08-16\\2017-08-16.java");
// 1.创建流对象
FileInputStream fis = null;
try {
fis = new FileInputStream(file);
// 2.创建一个缓存字节的容器数组
byte[]buf = new byte[1024];
// 3.定义一个变量,保存实际读取的字节数
int hasRead = 0;
// 4.循环读取数据
// while (true) {
// hasRead = fis.read(buf);
// if (hasRead==-1) {
// break;
// }
//// 5.操作保存数据的数组
// String msg = new String(buf, 0,hasRead);
// System.out.print(msg);
// }
while ((hasRead = fis.read(buf))!=-1) {
String str = new String(buf,0,hasRead);
System.out.print(str);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
// 6.关闭流
if (fis!=null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
文件字节输出流写入文件内容的步骤:
- 1.选择流:创建流对象
- 2.准备数据源,把数据源转换成字节数组类型
- 3.通过流向文件当中写入数据
- 4.刷新流
- 5.关闭流
public class FileOutputStreamDemo01 {
public static void main(String[] args) {
// 1.选择流:创建流对象
FileOutputStream fos =null;
try {
fos = new FileOutputStream(new File("c:\\read.txt"),true);
// 2.准备数据源,把数据源转换成字节数组类型
// String msg = "春夜喜雨\n好雨知时节,当春乃发生。\n随风潜入夜,润物细无声。";
String msg = "\n野径云俱黑,江船火独明。\n晓看红湿处,花丛锦官城。";
byte[] data = msg.getBytes();
// 3.通过流向文件当中写入数据
fos.write(data, 0, data.length);
// 4.刷新流
fos.flush();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (fos!=null) {
// 5.关闭流
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
处理流的好处:
处理流必须在节点流的基础之上,增加了效率,提高了性能,扩大的功能。
如图:
1.缓冲流
缓冲字节流
BufferedInputStream
BufferedOutputStream
缓冲字符流
BufferedReader
BufferedWriter
处理流内部包含了节点流,节点流决定了与其沟通的外部设备,而处理流则增加了其功能。
缓冲流的好处:
缓冲流内部包含一个缓冲区域,默认8kb,每一次程序调用read方法其实都是从缓冲区域当中读取内容,如果读取失败
就说明缓冲区域当中没有内容,那么就从数据源当中读取内容,然后会尽可能读取更多的字节放入到缓冲区域当中,
最后缓冲区域当中的内容,会全部返回给程序。
从缓冲区读取数据会比直接从数据源读取数据的速度快,效率也更高,性能更好。
简单说:
没有缓存区,那么每read一次,就会发送一次IO操作;有缓存区,第一次read时,会一下读取x个字节放入缓存区,
然后后续的read都会从缓存中读取,当read到缓存区末尾时,会再次读取x个字节放入缓存区。
处理流处理数据和节点流处理数据的方法基本上完全相同。
2,转换流:
转换流作用:把字节流转换成字符流,可以解决出现的因为编码集和解码集造成的乱码问题。
- InputStreamReader:
- OutputStreamWriter:
- 编码:字符—–编码字符集——–》二进制
- 解码:二进制—解码字符集———》字符
- 在处理文件时,如果文件的字符格式和编译器处理格式不一样时,会出现乱码问题。比如文件字符格式GBK,
- 而编译器是UTF-8格式,那么就会产生该问题。
- 出现乱码问题的原因:
- 1.编码和解码字符集不一致造成了乱码
- 2.字节的缺失,长度的丢失
- 大部分情况下,出现乱码问题是因为中国汉字,因为中国汉字在不同的字符编码当中占据的字节数不相同,但是都占据多个字节。
- 而英文字母没有这个问题,因为英文字母在所有的字符编码当中都占据一个字节。
InputStreamReader :转换输入流–》将字节输入流转换成字符输入流
作用:为了防止文件使用字符输入流处理时出现乱码问题。
节点流:
字节数组流(内存流)
ByteArrayInputStream
ByteArrayOutputStream
因为内存输出流当中又新增的方法,不能使用多态,不能够让父类的引用指向之类的对象。
作用:可以在循环当中把所有的数据存放到统一的容器当中,然后在循环结束之后可以把容器当中所有的内容一起取出来。
注意事项:
内存流属于内存当中的资源,所以数据量不要过大,如果太大,会造成内存溢出的错误。
数据处理流:
DataOutputStream
DataInputStream
特点: 既能够保存数据本身,又能够保存数据类型(基本数据类型+String)
序列化流:
将对象转换成字节序列的过程,就是对象序列化过程。
- 将字节序列恢复为对象的过程称之为对象的反序列化。
- 作用:保留对象(引用数据类型数据的)类型+数据。
- 序列化流 :输出流 ObjectOutputStream writeObject()
- 反序列化流: 输入流 ObjectInputStream readObject()
- 注意事项:
- 1。先序列化然后在反序列化,而且反序列化的顺序必须和序列化的顺序保持一致。
- 2.并不是所有的对象都能够被序列化。只有实现了Serializable接口的类的对象才能够被序列化。
- 对象当中并不是所有的属性都能够被序列化。
- 对象序列化的主要用途:
- 1.把对象转换成字节序列,保存到硬盘当中,持久化存储,通常保存为文件。
- 2.在网络上传递的是对象的字节序列
- 对象序列化的步骤:
- 1.创建对象输出流,在构造方法当中可以包含其他输出节点流,如文件输出流。
- 2.把对象通过writeObject的方式写入。
- 对象反序列化的步骤:
- 1.创建对象输入流,在构造方法当中可以包含其他的输入节点流,如文件输入流
- 2.通过readObject()方法读取对象。
serialVersionUID :序列化版本id
- 作用:从字面角度看,就是序列化版本号。凡是实现了Serializable接口的类,
- 都会有一个默认的静态的序列化标识。
- 1.类在不同的版本之间,可以解决序列化兼容问题,如果之前版本当中在文件中保存对象,
- 那么版本升级后,如果序列化id一致,我们可以认为文件中的对象依然是此类的对象。
- 2.如果类在不同的版本之间不希望兼容,但是还希望类的对象能够序列,那么就在不同版本中
- 使用不同的序列化id。
- transient :当类中有属性不想被序列化,那么就使用这个修饰符修饰。
File类:
File类的由来:File类的出现弥补了IO流的不足,IO只能够操作数据,但是不能够对文件的信息做操作,操作文件必须使用File类。
-功能:
可以将文件或者文件夹在程序当中分装成对象。
方便对于文件或者文件夹当中的属性信息进行操作。
File类通常通过构造函数作为参数传递到流的对象当中。
File类的常用方法介绍:
1.构造方法:
File(String pathname):这个构造可以将已存在的或者不存在的文件或者文件夹封装成File的对象,pathname即文件的的路径。
File(File parent,String child):parent为child文件所在的路径。
File(String parent,String child) :
【code】
File f6 = new File (“c:\java”,”jre7”);
//file的toString方法重写了,封装的地址是什么就打印什么
//’/’和’\’都是目录分隔符,在其他系统当中目录分割符可能发生变化,这个写法不利于跨平台操作
//最好使用File当中提供的字段separator进行分割。
2.创建文件相关函数:
createNewFile():创建相关文件。并返回布尔值
createTemFile():在默认临时文件目录当中创建一个空文件,程序运行结束后就不存在了。
mkdirs():创建目录,如果你写的目录的父目录不存在。他会帮你创建好。
3,删除文件相关函数:
delete():删除空目录或文件(ps只能是空目录)
deleteOnExit():在虚拟机终止时删除文件。
4.判断:
exists() :判断文件或者文件夹是否存在。
canExecute() :判断文件是否可执行,和操作系统相关。
canRead() :判断文件是否可读
canWrite() :判断文件是否可写
equals(Object obj) :测试此抽象路径名与给定对象是否相等。
isAbsolute() :测试此抽象路径名是否为绝对路径名。
isDirectory() :判断file对象是否表示文件夹。
isFile() :判断file对象是否表示文件
isHidden() :判断file对象是否是隐藏文件
5.获取file对象属性信息的方法:
getAbsoluteFile() :返回此抽象路径名的绝对路径名形式。
getAbsolutePath() :返回此抽象路径名的绝对路径名字符串。
getCanonicalFile() : 返回此抽象路径名的规范形式。
getCanonicalPath() :返回此抽象路径名的规范路径名字符串。
getPath() : 将此抽象路径名转换为一个路径名字符串。
getName() : 返回由此抽象路径名表示的文件或目录的名称。
getParent() :返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。
getParentFile() :返回此抽象路径名父目录的抽象路径名;如果此路径名没有指定父目录,则返回 null。
getTotalSpace() :返回指定路径的全部空间的字节数
getFreeSpace() :返回此抽象路径名指定的分区中未分配的字节数。
getUsableSpace() : 返回此抽象路径名指定的分区上可用于此虚拟机的字节数。
renameTo(File dest) :重新命名此抽象路径名表示的文件。剪切
6.设置文件信息的方法:
setExecutable(boolean executable) :设置文件可执行的方法
setLastModified(long time) :设置此抽象路径名指定的文件或目录的最后一次修改时间。
setReadable(boolean readable) :设置文件是否可读
setReadOnly() :设置文件是否只读
setWritable(boolean writable) :设置文件是否可写
7.获取文件的常规信息的方法:
lastModified() :获取文件最后一次被修改的时间
length() : 返回由此抽象路径名表示的文件的长度。
8.操作文件夹的相关方法
list(): 把文件夹当中包含的目录和文件都存放到字符串数组当中。
listFiles():列举文件夹当中包含的目录和文件,存放到File数组当中。
listRoots():列出可用的文件系统根。
9.文件过滤器: fleater
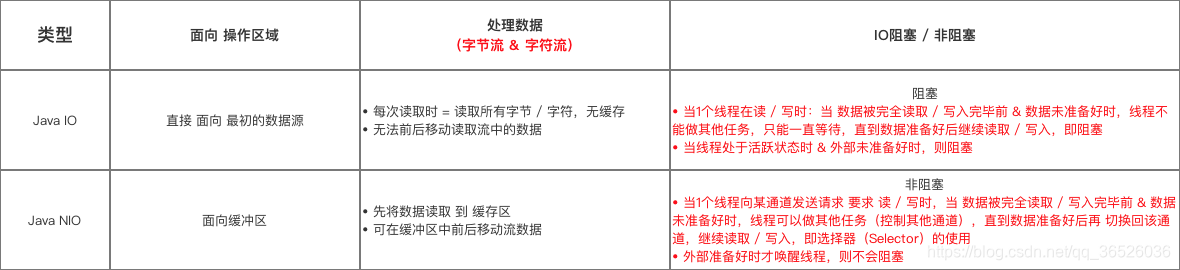
转载二(NIO):https://blog.csdn.net/carson_ho/article/details/84227675
JDK 1.4后,Java提供了一个全新的IO API,即 Java New IO
本文 全面 & 详细解析Java New IO,希望你们会喜欢
储备知识:Java IO
-
定义
即 Java New IO
是1个全新的、 JDK 1.4后提供的 IO API -
作用
提供了与标准IO不同的IO工作方式
可替代 标准Java IO 的IO API -
新特性
对比于 Java IO,NIO具备的新特性如下 -
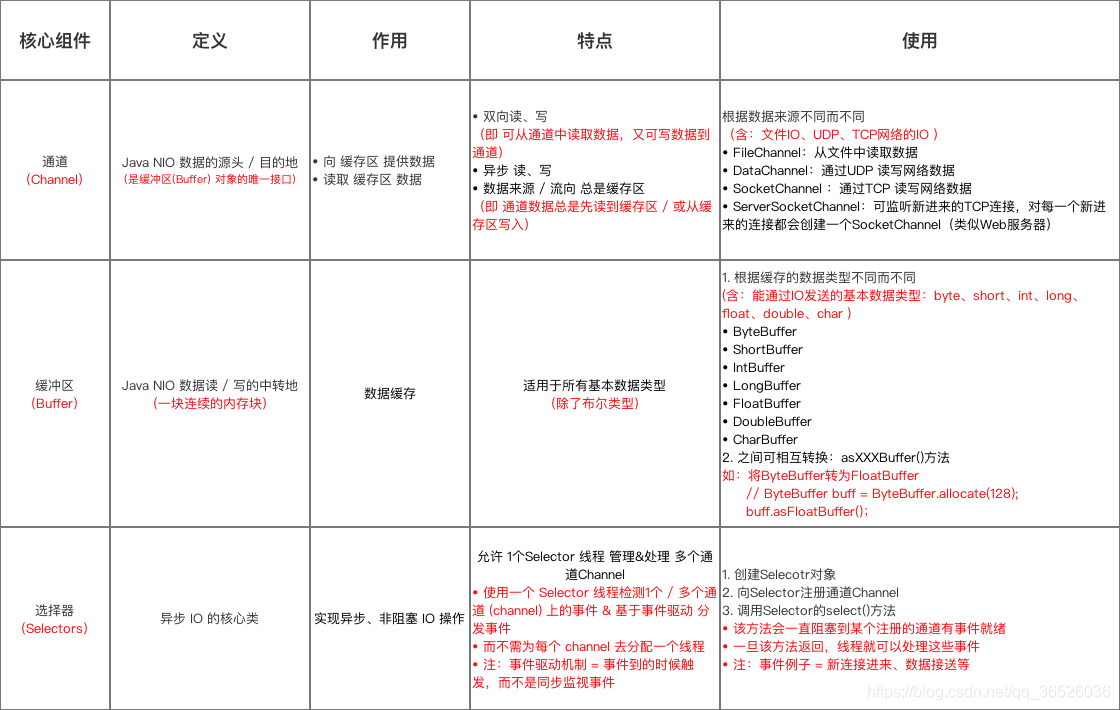
核心组件
Java NIO的核心组件 包括:
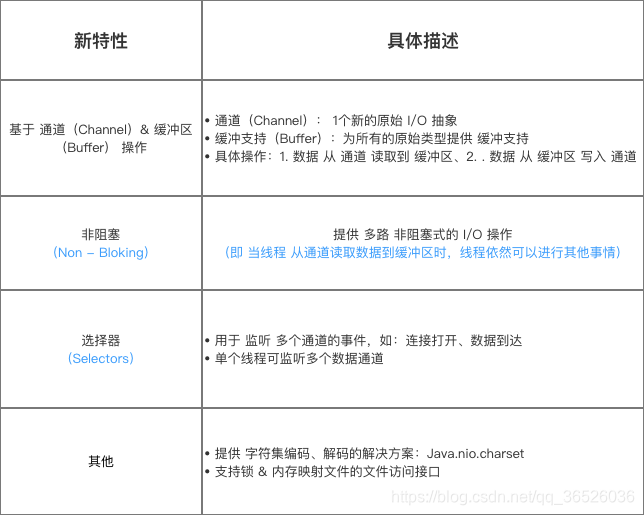
通道(Channel)
缓冲区(Buffer)
选择器(Selectors)
下面将详细介绍:
-
具体使用
5.1 基于通道 & 缓冲数据
具体步骤如下:// 1. 获取数据源 和 目标传输地的输入输出流(此处以数据源 = 文件为例)
FileInputStream fin = new FileInputStream(infile);
FileOutputStream fout = new FileOutputStream(outfile);// 2. 获取数据源的输入输出通道
FileChannel fcin = fin.getChannel();
FileChannel fcout = fout.getChannel();// 3. 创建 缓冲区 对象:Buffer(共有2种方法)
// 方法1:使用allocate()静态方法
ByteBuffer buff = ByteBuffer.allocate(256);
// 上述方法创建1个容量为256字节的ByteBuffer
// 注:若发现创建的缓冲区容量太小,则重新创建一个大小合适的缓冲区// 方法2:通过包装一个已有的数组来创建
// 注:通过包装的方法创建的缓冲区保留了被包装数组内保存的数据
ByteBuffer buff = ByteBuffer.wrap(byteArray);// 额外:若需将1个字符串存入ByteBuffer,则如下
String sendString="你好,服务器. ";
ByteBuffer sendBuff = ByteBuffer.wrap(sendString.getBytes(“UTF-16”));// 4. 从通道读取数据 & 写入到缓冲区
// 注:若 以读取到该通道数据的末尾,则返回-1
fcin.read(buff);// 5. 传出数据准备:将缓存区的写模式 转换->> 读模式
buff.flip();// 6. 从 Buffer 中读取数据 & 传出数据到通道
fcout.write(buff);// 7. 重置缓冲区
// 目的:重用现在的缓冲区,即 不必为了每次读写都创建新的缓冲区,在再次读取之前要重置缓冲区
// 注:不会改变缓冲区的数据,只是重置缓冲区的主要索引值
buff.clear();
5.2 基于选择器(Selecter)
具体步骤如下:
// 1. 创建Selector对象
Selector sel = Selector.open();
// 2. 向Selector对象绑定通道
// a. 创建可选择通道,并配置为非阻塞模式
ServerSocketChannel server = ServerSocketChannel.open();
server.configureBlocking(false);
// b. 绑定通道到指定端口
ServerSocket socket = server.socket();
InetSocketAddress address = new InetSocketAddress(port);
socket.bind(address);
// c. 向Selector中注册感兴趣的事件
server.register(sel, SelectionKey.OP_ACCEPT);
return sel;
// 3. 处理事件
try {
while(true) {
// 该调用会阻塞,直到至少有一个事件就绪、准备发生
selector.select();
// 一旦上述方法返回,线程就可以处理这些事件
Set keys = selector.selectedKeys();
Iterator iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = (SelectionKey) iter.next();
iter.remove();
process(key);
}
}
} catch (IOException e) {
e.printStackTrace();
}
- 实例讲解
实例说明:实现文件复制功能
实现方式:通道FileChannel、 缓冲区ByteBuffer
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class Test {
public static void main(String[] args) throws IOException {
// 设置输入源 & 输出地 = 文件
String infile = "C:\\copy.sql";
String outfile = "C:\\copy.txt";
// 1. 获取数据源 和 目标传输地的输入输出流(此处以数据源 = 文件为例)
FileInputStream fin = new FileInputStream(infile);
FileOutputStream fout = new FileOutputStream(outfile);
// 2. 获取数据源的输入输出通道
FileChannel fcin = fin.getChannel();
FileChannel fcout = fout.getChannel();
// 3. 创建缓冲区对象
ByteBuffer buff = ByteBuffer.allocate(1024);
while (true) {
// 4. 从通道读取数据 & 写入到缓冲区
// 注:若 以读取到该通道数据的末尾,则返回-1
int r = fcin.read(buff);
if (r == -1) {
break;
}
// 5. 传出数据准备:调用flip()方法
buff.flip();
// 6. 从 Buffer 中读取数据 & 传出数据到通道
fcout.write(buff);
// 7. 重置缓冲区
buff.clear();
}
}
}
- 与Java IO的区别