Python 网络爬虫与信息提取。
文章目录
- Python 网络爬虫与信息提取。
- 工具。
- Requests 库。
- HTTP 协议及 Requests 库方法。
- robots.txt
- 实例~京东。
- 实例~亚马逊。
- 实例~百度、360。
- 实例~网络图片的爬取和存储。
- 实例~IP 地址归属地的自动查询。
- Beautiful Soup
- 实例~中国大学排名定向爬虫。
- Projects
- 正则表达式 Re~一行胜千言。
- Scrapy
The Website is the API…
掌握定向网络爬取和网页解析的基本能力。

工具。
IDLE
Sublime Text
PyCharm
Anaconda & Spyder
Wing
Visual Studio & PTVS
Eclipse + PyDev
PyCharm
- 科学计算、数据分析。
Canopy
Anaconda
Requests 库。
http://2.python-requests.org/zh_CN/latest/
自动爬取 HTML 页面。
自动网络提交提交。
安装。
pip install requests
使用。
>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code
200
>>> r.encoding
'ISO-8859-1'
>>> r.encoding = 'utf-8'
>>> r.text
...
Requests 库主要方法。
| 方法 | 说明 |
|---|---|
| requests.request() | 构造一个请求,支持以下基础方法。 |
| requests.get() | 获取 HTML 网页的主要方法,对应于 HTTP 的 GET。 |
| requests.head() | 获取 HTML 网页头信息,对应于 HTTP 的 HEAD。 |
| requests.post() | 向 HTML 网页提交 POST 请求,对应于 HTTP 的 POST。 |
| requests.put() | 向 HTML 网页提交 PUT 请求,对应于 HTTP 的 PUT。 |
| requests.patch() | 向 HTML 网页提交局部修改请求,对应于 HTTP 的 PATCH。 |
| requests.delete() | 向 HTML 网页提交删除请求,对应于 HTTP 的 DELETE。 |
requests.request()
下面 6 种都是对 requests.request() 方法的封装。
return request('get', url, params=params, **kwargs)
- requests.get() 方法完整参数。
url ——> 拟获取页面的 url 链接。
params ——> url 中的额外参数,字典或字节流格式。可选。
**kwargs ——> 12 个控制访问的参数。

>>> import requests
>>> r = requests.get("http://www.baidu.com")
>>> r.status_code
200
>>> r.encoding
'ISO-8859-1'
>>> r.encoding = 'utf-8'
>>> r.text
> ... 省略内容。。。
>>> type(r)
<class 'requests.models.Response'>
GET() 方法。

Requests 库两个重要对象。
对象属性。

r.encoding
从 HTTP 的 header 中猜测的。如果 header 中不存在 charset,则认为编码为 ISO-8859-1。
(不能解析中文)。
r.apparent_encoding
从 HTTP 的内容部分,而不是头部分,去分析可能的编码。(更准确)。

- 爬取一般流程。

>>> import requests
>>> r = requests.get('http://www.baidu.com')
>>> r.encoding
'ISO-8859-1'
# 默认编码。
>>> r.apparent_encoding
'utf-8'
爬取网页的通用代码框架。
网络连接有风险,异常处理很重要。
异常。

Requests 库很重要。
Response 对象。r.raise_for_status()。

通用代码。
import requests
def getHtmlText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态不是 200,引发 HTTPError 异常。
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常。'
if __name__ == '__main__':
url = "http://www.baidu.com"
print(getHtmlText(url))
HTTP 协议及 Requests 库方法。

HTTP, Hypertext Transfer Protocol,超文本传输协议。
HTTP 是一个基于“请求与响应”模式的、无状态的应用层协议。
HTTP 一般采用 URL 作为定位网络资源的标识。
URL 格式。
http://host[:port] [path]
- host
合法的 Internet 主机域名或 IP 地址。- port
端口号,缺省端口为 80。- path
请求资源的路径。
HTTP URL 的理解。
URL 是通过 HTTP 协议存取资源的 Internet 路径,一个 URL 对应一个数据资源。
HTTP 协议对资源的操作。


PATCH 和 PUT 的区别。
假设 URL 位置有一组数据 UserInfo,包括 UserID,UserName 等 20 个字段。
需求:用户修改了 UserName,其他不变。
- 采用 PATCH,仅向 URL 提交 UserName 的局部更新请求。
- 采用 PUT,必须将所有 20 个 字段一并提交到 URL,未提交字段被删除。
PATCH ——> 节省网络带宽。
HTTP 协议与 Requests 库。

>>> import requests
>>> r = requests.head('http://www.baidu.com')
>>> r.headers
{'Connection': 'keep-alive', 'Server': 'bfe/1.0.8.18', 'Last-Modified': 'Mon, 13 Jun 2016 02:50:08 GMT', 'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 15 Mar 2020 05:27:57 GMT', 'Pragma': 'no-cache'}
>>> r.text
''
>>>
# r.text 为空。
Requests 库的 post() 方法。
- 向 URL POST 一个字典,自动编码为 form(表单)。
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post('http://httpbin.org/post', data = payload)
>>> print(r.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.12.4",
"X-Amzn-Trace-Id": "Root=1-5e6dbe4a-093105e6e89bdcef261839bc"
},
"json": null,
"origin": "111.47.210.49",
"url": "http://httpbin.org/post"
}
>>>
- 向 URL POST 一个字符串,自动编码为 data。
>>> r = requests.post('http://httpbin.org/post', data = 'geek')
>>> print(r.text)
{
"args": {},
"data": "geek",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "4",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.12.4",
"X-Amzn-Trace-Id": "Root=1-5e6dc04d-b5788522e25af298ea06f366"
},
"json": null,
"origin": "111.47.210.49",
"url": "http://httpbin.org/post"
}
>>>
Requests 库的 put() 方法。
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.put('http://httpbin.org/put', data = payload)
>>> print(r.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.12.4",
"X-Amzn-Trace-Id": "Root=1-5e6dc16b-6bf16d909e60eba2379976b6"
},
"json": null,
"origin": "111.47.210.49",
"url": "http://httpbin.org/put"
}
>>>
Requests 库主要方法解析。13 个。
requests.request(method, url, **kwargs)
method ——> 请求方法,对应 get / put / post 等 7 种。
url ——> 拟获取页面的 url 链接。
**kwargs ——> 控制访问的参数,共 13 个。
- method ——> 请求方式。

- **kwargs ——> 控制访问的参数,共 13 个。
** 开头 ——> 可选参数。
params ——> 字典或字节序列,作为参数增加到 url 中。
>>> kv = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.request('GET', 'http://python123.io/ws', params=kv)
>>> print(r.url)
https://python123.io/ws?key1=value1&key2=value2
data ——> 字典、字节序列或文件对象,作为 Request 的内容。
>>> kv = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.request('POST', 'http://python123.io/ws', data=kv)
>>> body = '主体内容'
>>> r = requests.request('POST', 'http://python123.io/ws', data=body.encode('utf-8'))
json ——> JSON 格式的数据,作为 Request 的内容。
>>> kv = {'key1': 'value1'}
>>> r = requests.request('POST', 'http://python123.io/ws', json=kv)
headers ——> 字典,HTTP 定制头。
>>> kv = {'key1': 'value1'}
>>> r = requests.request('POST', 'http://python123.io/ws', headers=hd)
cookies ——> 字典或 CookieJar,Request 中的cookie。
auth ——> 元组,支持 HTTP 认证功能。
files ——> 字典类型,传输文件。
>>> fs = {'file': open('data.xls', 'rb')}
>>> r = requests.request('POST', 'http://python123.io/ws', files=fs)
timeout ——> 设定超时时间,单位:秒。
>>> r = requests.request('GET', 'http://www.baidu.com', timeout=10)
proxies ——> 字典类型,设定访问代理服务器,可以增加登录认证。(隐藏用户原 IP 信息,防止爬虫逆追踪)。
>>> pxs = {'http': 'http://user:[email protected]:1234', \
... 'https': 'https://10.10.10.1:4321'}
>>> r = requests.request('GET', 'http://www.baudi.com', proxies=pxs)
allow_redirects ——> True / False,默认为 True,重定向开关。
stream ——> True / False,默认为 True,获取内容立即下载开关。
verify ——> True / False,默认为 True,认证 SSL 证书开关。
cert ——> 本地 SSL 证书路径。
requests.get(url, params=None, **kwargs)
requests.head(url, **kwargs)
requests.post(url, data=None, json=None, **kwargs)
requests.put(url, data=None, **kwargs)
requests.patch(url, data=None, **kwargs)
requests.delete(url, **kwargs)
robots.txt
网络爬虫排队标准。
网络爬虫引发的问题。


- 网络爬虫的法律风险。
服务器上的数据有产权归属。
网络爬虫获取数据后牟利将带来法律风险。
- 网络爬虫泄露隐私。
网络爬虫可能具备突破简单访问控制的能力,获得被保护数据从而泄露个人隐私。
对网络爬虫采取限制。
检查来访 HTTP 协议头的 User-Agent 域,只响应浏览器或友好爬虫的访问。
告知所有爬虫网站的看爬取策略,要求爬虫遵守。
Robots 协议。

放在根目录下。
http://www.baudi.com/robots.txt
http://news.sina.com.cn/robots.txt
http://www.qq.com/robots.txt
http://news.qq.com/robots.txt
http://www.moe.edu.cn/robots.txt(无 robots 协议)。
https://www.jd.com/robots.txt
User-agent: *
Disallow: /?*
Disallow: /pop/*.html
Disallow: /pinpai/*.html?*
User-agent: EtaoSpider
Disallow: /
User-agent: HuihuiSpider
Disallow: /
User-agent: GwdangSpider
Disallow: /
User-agent: WochachaSpider
Disallow: /

Robots 协议的遵守方式。
Robots 协议的使用。
网络爬虫:自动或人工识别 robots.txt,再进行内容爬取。
- 约束性:Robots 协议是建议但非约束性,网络爬虫可以不遵守,但存在法律风险。

类人行为可以不参考 Robots 协议。
实例~京东。
https://item.jd.com/100004364088.html
>>> import requests
>>> r = requests.get('https://item.jd.com/100004364088.html')
>>> r.status_code
200
>>> r.encoding
'gbk'
# 可以从头部分解析编码。
>>> r.text[:1000]
'<!DOCTYPE HTML>\n<html lang="zh-CN">\n<head>\n <!-- shouji -->\n <meta http-equiv="Content-Type" content="text/html; charset=gbk" />\n <title>【小米Ruby】小米 (MI)Ruby 15.6英寸 网课 学习轻薄笔记本电脑(英特尔酷睿i5-8250U 8G 512G SSD 2G GDDR5独显 FHD 全键盘 Office Win10) 深空灰 电脑【行情 报价 价格 评测】-京东</title>\n <meta name="keywords" content="MIRuby,小米Ruby,小米Ruby报价,MIRuby报价"/>\n <meta name="description" content="【小米Ruby】京东JD.COM提供小米Ruby正品行货,并包括MIRuby网购指南,以及小米Ruby图片、Ruby参数、Ruby评论、Ruby心得、Ruby技巧等信息,网购小米Ruby上京东,放心又轻松" />\n <meta name="format-detection" content="telephone=no">\n <meta http-equiv="mobile-agent" content="format=xhtml; url=//item.m.jd.com/product/100004364088.html">\n <meta http-equiv="mobile-agent" content="format=html5; url=//item.m.jd.com/product/100004364088.html">\n <meta http-equiv="X-UA-Compatible" content="IE=Edge">\n <link rel="canonical" href="//item.jd.com/100004364088.html"/>\n <link rel="dns-prefetch" href="//misc.360buyimg.com"/>\n <link rel="dns-prefetch" href="//static.360bu'
import requests
def getHtmlText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 如果状态不是 200,引发 HTTPError 异常。
r.encoding = r.apparent_encoding
return r.text
except:
return '产生异常。'
if __name__ == '__main__':
url = "https://item.jd.com/100004364088.html"
print(getHtmlText(url))
实例~亚马逊。
https://www.amazon.cn/dp/B07STXYG5T/ref=lp_1454005071_1_13?s=pc&ie=UTF8&qid=1584258911&sr=1-13
>>> r = requests.get('https://www.amazon.cn/dp/B07STXYG5T/ref=lp_1454005071_1_13?s=pc&ie=UTF8&qid=1584258911&sr=1-13')
Python 忠实的告诉了服务器这是由 Python 的 Requests 库请求的。
>>> r.request.headers
{'Connection': 'keep-alive', 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'User-Agent': 'python-requests/2.12.4'}
修改 user-agent。
>>> kv = {'user-agent': 'Mozilla/5.0'}
>>> url = 'https://www.amazon.cn/dp/B07STXYG5T/ref=lp_1454005071_1_13?s=pc&ie=UTF8&qid=1584258911&sr=1-13'
>>> r = requests.get(url, headers = kv)
>>> r.status_code
200
>>> r.request.headers
{'Connection': 'keep-alive', 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'user-agent': 'Mozilla/5.0'}
实例~百度、360。
- 百度接口。
https://www.baidu.com/s?wd=
keyword
>>> import requests
>>> kv = {'wd': 'Python'}
>>> r = requests.get('https://www.baidu.com/s', params = kv)
>>> r.status_code
200
>>> r.request
r.request
>>> r.request.url
'https://wappass.baidu.com/static/captcha/tuxing.html?&ak=c27bbc89afca0463650ac9bde68ebe06&backurl=https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3DPython&logid=9150222916142828809&signature=0acac15173bcd5487e4b0837a6dbf568×tamp=1584259949'
>>> len(r.text)
1519
- 360 接口。
https://www.so.com/s?q=
keyword
实例~网络图片的爬取和存储。
- 网络图片链接格式。
http://www.example.com/
picture.jpg
- 国家地理中文网。
http://www.ngchina.com.cn/
每日一图。
http://www.ngchina.com.cn/photography/photo_of_the_day/6245.html
http://image.ngchina.com.cn/2020/0310/20200310021330655.jpg
>>> import requests
>>> path = '/home/geek/geek/crawler_demo/marry.jpg'
>>> url = 'http://image.ngchina.com.cn/2020/0310/20200310021330655.jpg'
>>> requests.get(url)
<Response [200]>
>>> r = requests.get(url)
>>> with open(path, 'wb') as f:
... f.write(r.content) # r.content 是二进制形式。
...
471941
>>> f.close
f.close( f.closed
>>> f.close()
>>>

完整代码。
import os
import requests
root = r'/home/geek/geek/crawler_demo/'
url = 'http://image.ngchina.com.cn/2020/0310/20200310021330655.jpg'
path = root + url.split('/')[-1]
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
with open(path, 'wb') as f:
r = requests.get(url)
f.write(r.content) # r.content 是二进制形式。
f.close()
print('文件保存成功。')
else:
print('文件已存在。')
except Exception as e:
print(e)
print('爬取失败。')
结果。
geek@geek-PC:~/geek/crawler_demo$ ls
marry.jpg
geek@geek-PC:~/geek/crawler_demo$ ls
20200310021330655.jpg marry.jpg
实例~IP 地址归属地的自动查询。
首先需要一个 IP 地址库。
www.ip138.com iP查询(搜索iP地址的地理位置)
接口。
http://www.ip138.com/iplookup.asp?ip=
IP 地址&action=2
>>> import requests
>>> url = 'http://www.ip138.com/iplookup.asp?ip=111.47.210.37&action=2'
>>> kv = {'user-agent': 'Mozilla/5.0'}
>>> r = requests.get(url, headers = kv)
>>> r.status_code
200
>>> r.encoding = r.apparent_encoding
>>> r.text
代码。
import requests
url = 'http://www.ip138.com/iplookup.asp?ip=111.47.210.37&action=2'
kv = {'user-agent': 'Mozilla/5.0'}
try:
r = requests.get(url, headers=kv)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[:1000])
except:
print('爬取失败。')
Beautiful Soup
解析 HTML 页面。
文档。
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
Beautiful Soup 库的安装。
geek@geek-PC:~$ pip install beautifulsoup4
测试页面。
https://python123.io/ws/demo.html
页面源码。
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
- Requests 获取源码。
>>> import requests
>>> r = requests.get('https://python123.io/ws/demo.html')
>>> r.text
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
>>> demo = r.text
>>> from bs4 import BeautifulSoup
# 从 bs4 库导入 BeautifulSoup 类。
>>> soup = BeautifulSoup(demo, 'html.parser')
# 用 'html.parser' 解析器解析 demo。
>>> print(soup.prettify())
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
>>>
Beautiful Soup 库的基本元素。

Beautiful Soup 库是解析、遍历、维护“标签树”的功能库。

Beautiful Soup 库的引用。
Beautiful Soup 库,也叫
beautifulsoup4或bs4。
from bs4 import BeautifulSoup
import bs4
使用时,可以认为他们等价。

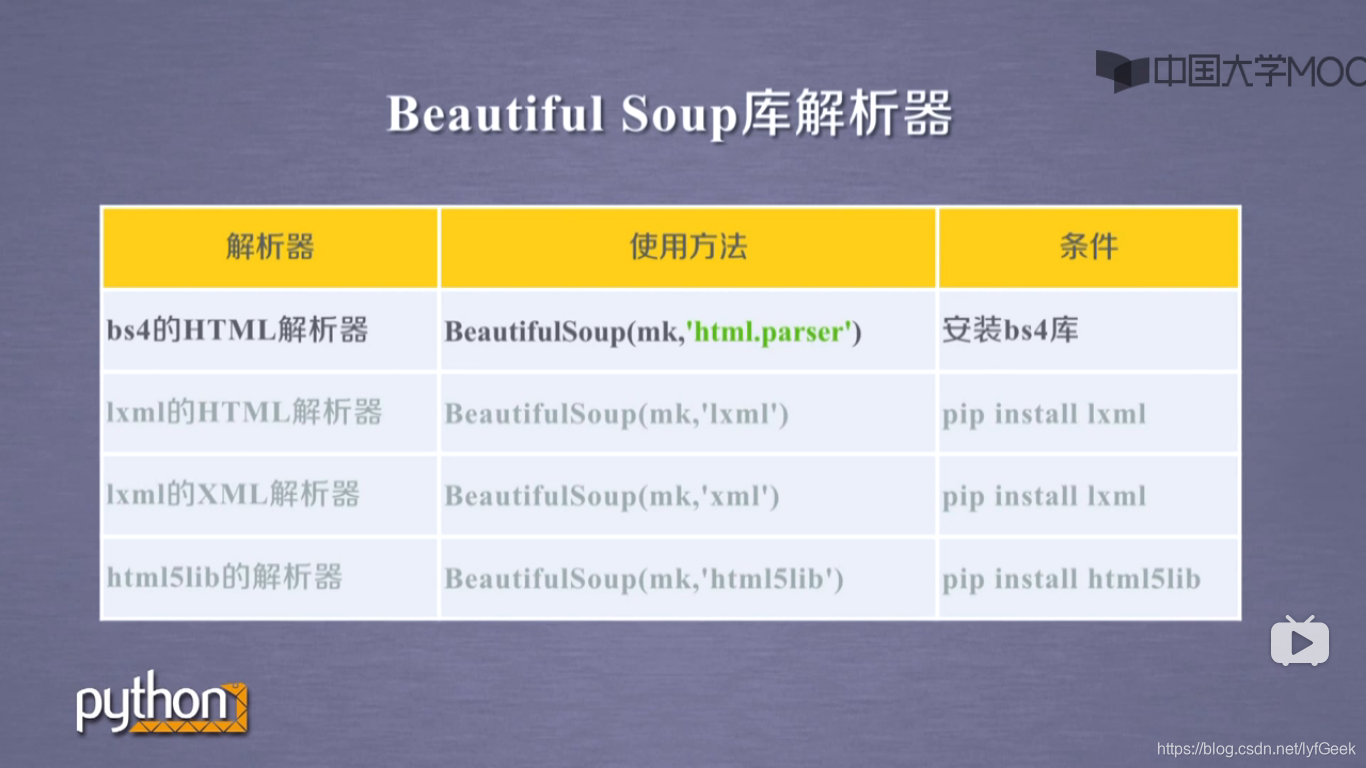
Beautiful Soup 库解析器。
Beautiful Soup 类的基本元素。

>>> import requests
>>> r = requests.get('https://python123.io/ws/demo.html')
>>> demo = r.text
>>> from bs4 import BeautifulSoup
>>> soup = B
BaseException( BlockingIOError( BufferError(
BeautifulSoup( BrokenPipeError( BytesWarning(
>>> soup = BeautifulSoup(demo, 'html.parser')
>>> soup.title
<title>This is a python demo page</title>
>>> tag = soup.a
>>> tag
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
>>> soup.a.name
'a'
>>> soup.a.parent.name
'p'
>>> soup.a.parent.parent.name
'body'
- 标签属性。——> 字典。
>>> tag = soup.a
>>> tag.attrs
{'class': ['py1'], 'id': 'link1', 'href': 'http://www.icourse163.org/course/BIT-268001'}
>>> tag.attrs['class']
['py1']
>>> type(tag.attrs['href'])
<class 'str'>
>>> type(tag.attrs)
<class 'dict'>
>>> type(tag)
<class 'bs4.element.Tag'>
- 标签的内容。NavigableString。
.string
>>> soup.a
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
>>> soup.a.string
'Basic Python'
>>> type(soup.a.string)
<class 'bs4.element.NavigableString'>
- Comment ——> 注释。
>>> newsoup = BeautifulSoup('<b><!--This is a comment.--></b><p>This is not a comment.</p>', 'html.parser')
>>> newsoup.b.string
'This is a comment.'
>>> type(newsoup.b.string)
<class 'bs4.element.Comment'>
>>> newsoup.p.string
'This is not a comment.'
>>> type(newsoup.p.string)
<class 'bs4.element.NavigableString'>
小结。

基于 bs4 库的 HTML 内容遍历方法。
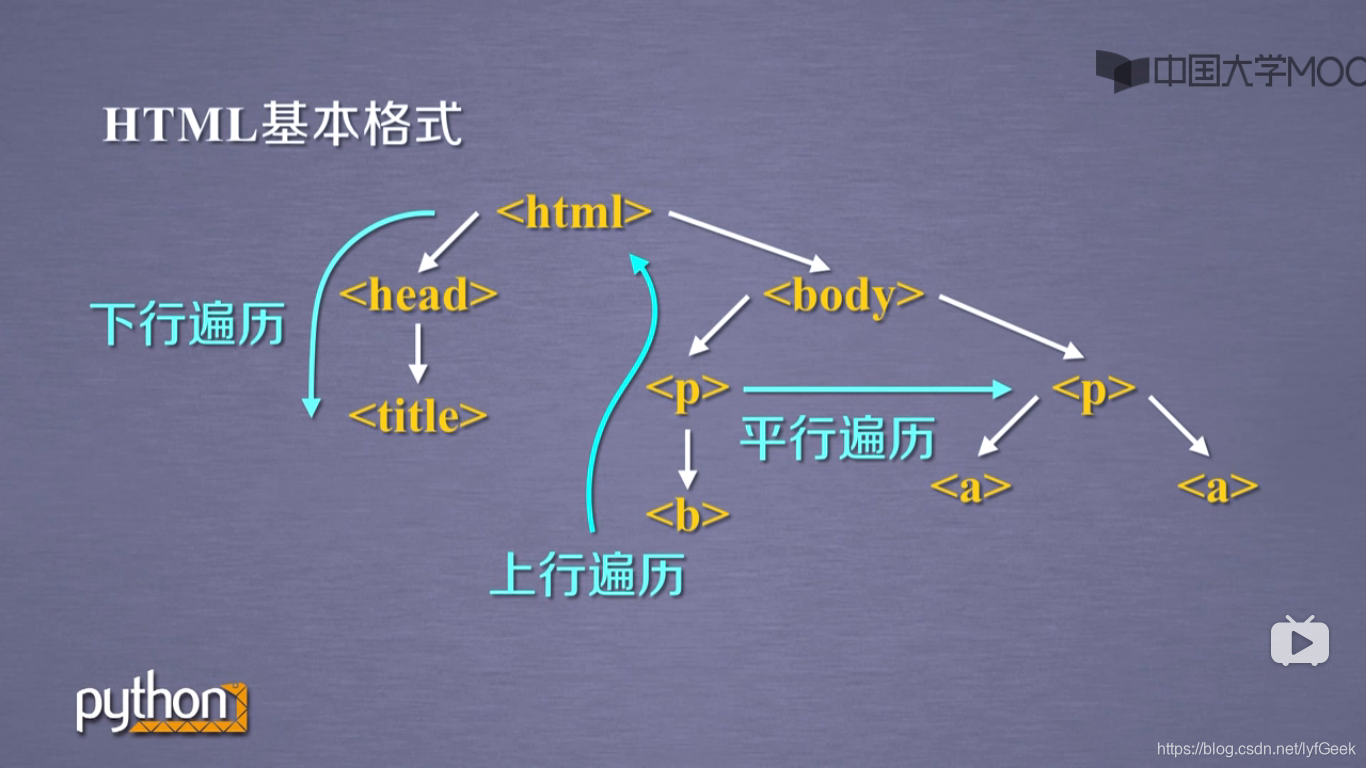
- HTML 基本格式。


遍历方式。
标签树的下行遍历。

>>> soup = BeautifulSoup(demo, 'html.parser')
>>> soup.head
<head><title>This is a python demo page</title></head>
>>> soup.head.contents
[<title>This is a python demo page</title>]
>>> soup.body.contents
['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
>>> len(soup.body.contents)
5
# 列表 list。('\n' 算一项)。
>> soup.body.contents[1]
<p class="title"><b>The demo python introduces several python courses.</b></p>

标签树的上行遍历。

>>> soup = BeautifulSoup(demo, 'html.parser')
>>> for parent in soup.a.parents:
... if parent is None:
... print(parent)
... else:
... print(parent.name)
...
p
body
html
[document]
标签树的平行遍历。



小结。

基于 bs4 库的 HTML 格式输出。
如何让 <html> 内容更加“友好”的显示。
>>> import requests
>>> r = requests.get("http://python123.io/ws/demo.html")
>>> demo = r.text
>>> demo
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo, 'html.parser')
>>> soup
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
>>> soup.prettify()
'<html>\n <head>\n <title>\n This is a python demo page\n </title>\n </head>\n <body>\n <p class="title">\n <b>\n The demo python introduces several python courses.\n </b>\n </p>\n <p class="course">\n Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\n <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">\n Basic Python\n </a>\n and\n <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">\n Advanced Python\n </a>\n .\n </p>\n </body>\n</html>'
// 在每一组标签后加了 \n。
>>> print(soup.prettify())
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
编码。Python3 默认使用 UTF-8。
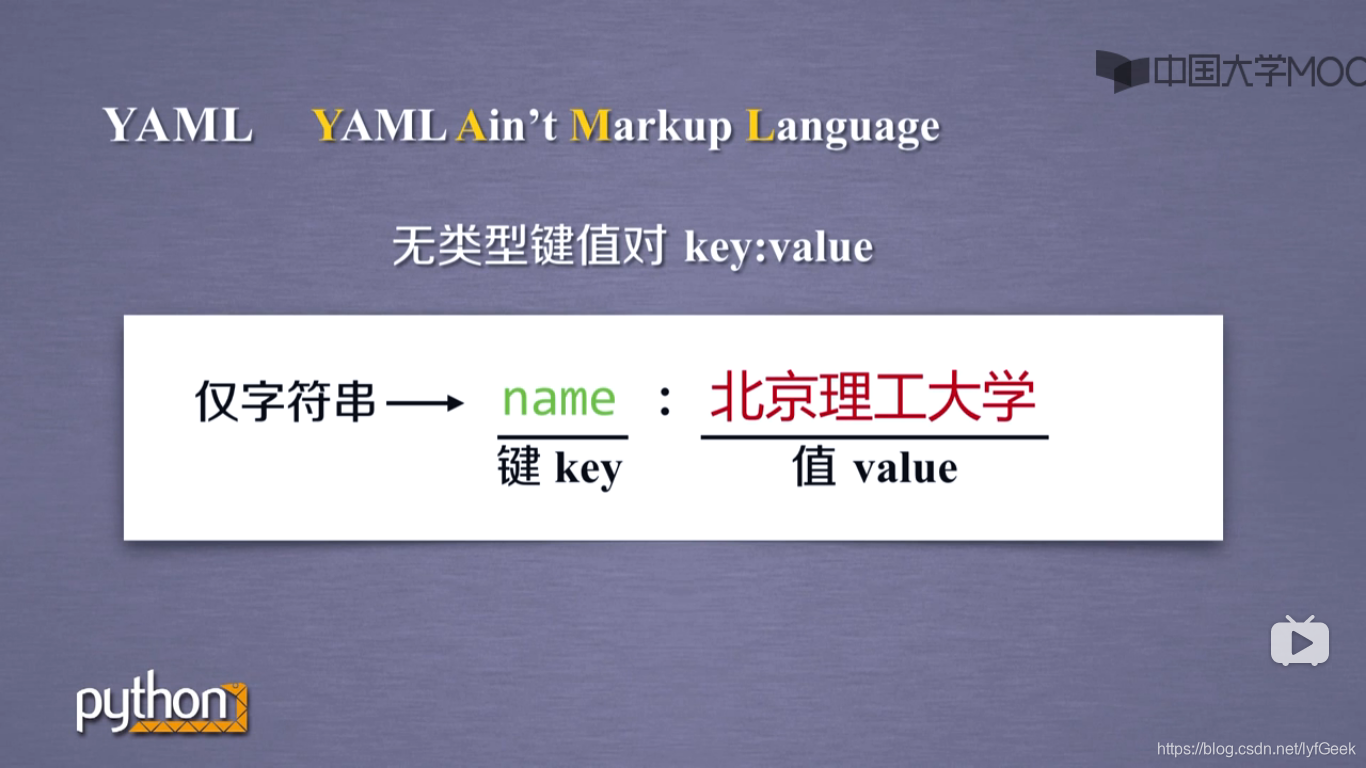
信息标记的三种形式。
- 标记后的信息可形成信息组织结构,增加了信息维度。
- 标记后的信息可用于通信、存储或展示。
- 标记的结构与信息一样具有重要价值。
- 标记后的信息更利于程序理解和运用。

- HTML 的信息标记。
HTML 通过预定义的 <>…</> 标签形式组织不同类型的信息。
+ XML。
e
XtensibleMarkupLanguage。


xml 是基于 html 发展的通用信息表达形式。
+ json。




+ yaml。



三种信息标记形式的比较。


信息提取的一般方法。
完整解析信息的标记形式,再提取关键信息。

无视标记形式,直接搜索关键信息。

融合方法。

实例。

>>> import requests
>>> r = requests.get('http://python123.io/ws/demo.html')
>>> type(r)
<class 'requests.models.Response'>
>>> r.status_code
200
>>> r.url
'https://python123.io/ws/demo.html'
>>> type(r.status_code)
<class 'int'>
>>> demo = r.text
>>> from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(demo, 'html.parser')
>>> for link in soup.find_all('a'):
... print(link.get('href'))
...
http://www.icourse163.org/course/BIT-268001
http://www.icourse163.org/course/BIT-1001870001
bs4.BeautifulSoup 的方法。
>>> type(soup)
<class 'bs4.BeautifulSoup'>

+ def find_all(self, name=None, attrs={}, recursive=True, text=None, limit=None, **kwargs):
返回一个列表类型,存储查找的结果。
>>> soup.find_all('a')
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
>>> soup.find_all(['a', 'b'])
[<b>The demo python introduces several python courses.</b>, <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
>>> for tag in soup.find_all(True):
... print(tag.name)
...
html
head
title
body
p
b
p
a
a
正则表达式库。
>>> for tag in soup.find_all(re.compile('b')):
... print(tag.name)
...
body
b
- name。
对标签名称的检索字符串。
- attrs。
对标签属性值的检索字符串,可标注属性检索。
带有 “course” 属性值的 <p> 标签。
>>> soup.find_all('p', 'course')
[<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]
id 域为 link1 的标签。
>>> soup.find_all(id='link1')
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>]
>>> soup.find_all(id='link')
[]
正则。
>>> soup.find_all(id=re.compile('link'))
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
- recursive。
是否对子孙全部检索。默认 True。
- string。
<>…</> 中字符串区域的检索字符串。
>>> soup.find_all(string = 'Basic Python')
['Basic Python']
>>> import re
>>> soup.find_all(string = re.compile('python'))
['This is a python demo page', 'The demo python introduces several python courses.']

扩展方法。

实例~中国大学排名定向爬虫。
http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html

- 程序分析。
使用二维数组。


import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ''
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[2].string])
def printUnivList(ulist, num):
print('{:^10}\t{:^6}\t{:^10}'.format('排名', '学校名称', '总分'))
for i in range(num):
u = ulist[i]
print('{:^10}\t{:^6}\t{:^10}'.format(u[0], u[1], u[2]))
print('Sum' + str(num))
def main():
unifo = []
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
fillUnivList(unifo, html)
printUnivList(unifo, 20)
main()


def printUnivList(ulist, num):
tplt = '{0:^10}\t{1:{3}^10}\t{2:^10}'
# 使用 tplt.format() 的第三个参数进行填充。
print(tplt.format('排名', '学校名称', '总分', chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], chr(12288)))
print('Sum' + str(num))
Projects
实战项目 A/B。
正则表达式 Re~一行胜千言。
正则表达式详解。
提取页面关键信息。





理解:编译(compile)之前 ta 仅仅是一个字符串。

正则表达式语法。



Scrapy
网络爬虫原理介绍。
专业爬虫框架介绍。
