为什么Redis能这么快?
- 完全基于内存,绝大部分请求是纯粹的内存操作,执行效率高
- 数据结构简单,对数据操作也简单
- 采用单线程,单线程也能处理高并发请求,像多核也可启动多实例
- 使用多路I/O复用模型,即非阻塞IO
说说你用过的Redis的数据类型
参考:Redis API
从海量Key里查询出某一固定前缀的Key
- 摸清数据规模,即问清边界
- Keys pattern?
- 一次性返回所有匹配的key
- 键的数量过大会使服务卡顿
- 可以使用
SCAN cusor [MATCH patten] [COUNT count],每次只返回少量元素- 基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程
- 以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历,记得
将上次返回的游标作为下次SCAN的游标 - 不保证每次执行都返回某个给定数量的元素,只能是大概率符合count参数,支持模糊查询
- 可能会
获取到重复key的问题,这个就需要代码层去进行一个去重了,比如用HashSet接收。 - 如:
scan 0 match k1* count 10,表示将键为 k1 开头的从0开始的游标数10个(10个以内,不一定是10个)返回
如何通过Redis实现分布式锁
- 分布式锁需要解决的问题
- 互斥性
- 安全性
- 死锁
- 容错
- SETNX key value:如果key不存在,则创建并赋值
- 如何解决SETNX长期有效的问题
- EXPIRE key seconds:设置key的生存时间,当key过期时(生存时间为0),会自动被删除
- 缺点:原子性得不到满足
- 上一问题替代方法:
SET key value [EX seconds] [PX milliseconds] [NX|XX]- Ex second:设置键的过期时间为 second 秒
- PX milliseconds:设置键的过期时间为 millisecond 毫秒
- NX:只在键不存在时,才对键进行设置操作
- XX:只在键已经存在时,才对键进行设置操作
- SET操作成功完成时,返回OK,否则返回nil
- 例如:
set lock 12345 ex 10 nx,表示设置了一个key为lock的锁,锁的过期时间为10秒
- 大量的key同时过期的注意事项
- 集中过期,由于清除大量的key很耗时,
会出现短暂的卡顿现象 - 解决方案:在设置key的过期时间的时候,
给每个key加上随机值
- 集中过期,由于清除大量的key很耗时,
如何使用Redis做异步队列
- 使用Redis的List作为队列,RPUSH生产消息,LPOP消费消息
- 缺点:没有等待队列里有值就直接消费
- 弥补:可以通过在应用层引入Sleep机制去调用LPOP重试
BLPOP key [key ...] timeout:阻塞直到队列有消息或者超时- 缺点:只能供一个消费者消费
pub/sub:主题订阅者模式- 发送者(pub)发送消息,如:
publish myTopic hello,表示向myTopic发布消息hello - 订阅者(sub)接收消息,如:
subscribe myTopic,表示订阅myTopic的消息 - 订阅者可以订阅任意数量的频道
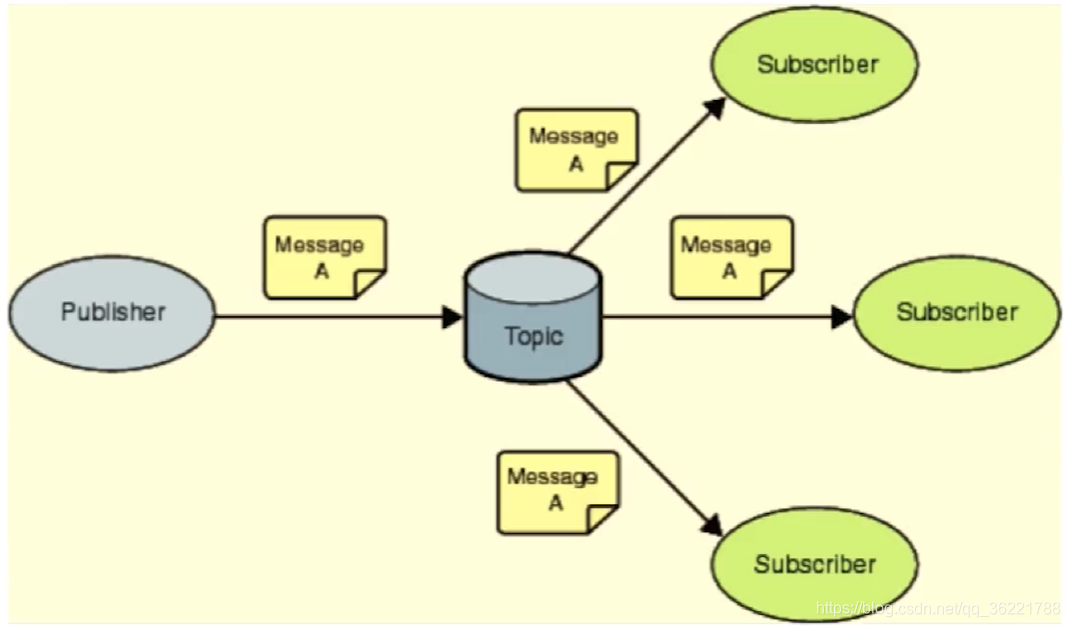
- 发送者(pub)发送消息,如:
- 缺点:
消息的发布是无状态的,无法保证可达,消息还是即发即失的
Redis如何做持久化
参考:RDB和AOF数据持久化
使用Pipeline的好处
Redis的集群原理
- 如何从海量数据里快速找到所需?
- 分片:按照某种规则去划分数据,分散存储在多个节点上
- 常规的按照哈希划分无法实现节点的动态增减
- 一致性hash算法:对 2的32次方 取模,将哈希值空间组织成虚拟的圆环
