1、tf.multiply():两个矩阵中对应元素各自相乘
格式: tf.multiply(x, y, name=None)
参数:
x: 一个类型为:half, float32, float64, uint8, int8, uint16, int16, int32, int64, complex64, complex128的张量。
y: 一个类型跟张量x相同的张量。
返回值: x * y element-wise.
注意:
- (1)multiply这个函数实现的是元素级别的相乘,也就是两个相乘的数元素各自相乘,而不是矩阵乘法,注意和tf.matmul区别。
- (2)两个相乘的数必须有相同的数据类型,不然就会报错。
2、tf.matmul():将矩阵a乘以矩阵b,生成a * b。
格式: tf.matmul(a, b, transpose_a=False, transpose_b=False, adjoint_a=False, adjoint_b=False, a_is_sparse=False, b_is_sparse=False, name=None)
参数:
- a: 一个类型为 float16, float32, float64, int32, complex64, complex128 且张量秩 > 1 的张量。
- b: 一个类型跟张量a相同的张量。
- transpose_a: 如果为真, a则在进行乘法计算前进行转置。
- transpose_b: 如果为真, b则在进行乘法计算前进行转置。
- adjoint_a: 如果为真, a则在进行乘法计算前进行共轭和转置。
- adjoint_b: 如果为真, b则在进行乘法计算前进行共轭和转置。
- a_is_sparse: 如果为真, a会被处理为稀疏矩阵。
- b_is_sparse: 如果为真, b会被处理为稀疏矩阵。
name: 操作的名字(可选参数)
返回值: 一个跟张量a和张量b类型一样的张量且最内部矩阵是a和b中的相应矩阵的乘积。
注意:
- (1)输入必须是矩阵(或者是张量秩 >2的张量,表示成批的矩阵),并且其在转置之后有相匹配的矩阵尺寸。
- (2)两个矩阵必须都是同样的类型,支持的类型如下:float16, float32, float64, int32, complex64, complex128。
示例代码
import tensorflow as tf
#两个矩阵的对应元素各自相乘!!
x=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
y=tf.constant([[0,0,1.0],[0,0,1.0],[0,0,1.0]])
#注意这里这里x,y要有相同的数据类型,不然就会因为数据类型不匹配而出错
z=tf.multiply(x,y)
#两个数相乘
x1=tf.constant(1)
y1=tf.constant(2)
#注意这里这里x1,y1要有相同的数据类型,不然就会因为数据类型不匹配而出错
z1=tf.multiply(x1,y1)
#数和矩阵相乘
x2=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
y2=tf.constant(2.0)
#注意这里这里x1,y1要有相同的数据类型,不然就会因为数据类型不匹配而出错
z2=tf.multiply(x2,y2)
#两个矩阵相乘
x3=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
y3=tf.constant([[0,0,1.0],[0,0,1.0],[0,0,1.0]])
#注意这里这里x,y要满足矩阵相乘的格式要求。
z3=tf.matmul(x,y)
with tf.Session() as sess:
print(sess.run(z))
print(sess.run(z1))
print(sess.run(z2))
print(sess.run(z3))
输出结果
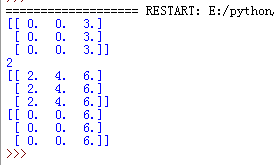
3、 tf.reduce_sum(): 求和
具体见:https://www.jianshu.com/p/30b40b504bae
4、 tf.pow(x, y, name=None):幂值计算操作,即 x^y
具体见:https://blog.csdn.net/qq_36512295/article/details/100600813
5、tf.train.GradientDescentOptimizer 优化器
tf.train.GradientDescentOptimizer(learning_rate, use_locking=False,name=’GradientDescent’)
参数:
- learning_rate: A Tensor or a floating point value. 要使用的学习率
- use_locking: 要是True的话,就对于更新操作(update -operations.)使用锁
- name: 名字,可选,默认是”GradientDescent”
minimize() 函数处理了梯度计算和参数更新两个操作
compute_gradients() 函数用于获取梯度
apply_gradients() 用于更新参数
6、tensorflow的tf.nn.relu()函数
tf.nn.relu()函数是将大于0的数保持不变,小于0的数置为0
import tensorflow as tf
a = tf.constant([-2,-1,0,2,3])
with tf.Session() as sess:
print(sess.run(tf.nn.relu(a)))
结果是
[0 0 0 2 3]
又如
import tensorflow as tf
a = tf.constant([[-2,-4],[4,-2]])
with tf.Session() as sess:
print(sess.run(tf.nn.relu(a)))
输出结果为
扫描二维码关注公众号,回复:
10043456 查看本文章

[[0 0]
[4 0]]
relu的图像是这样的
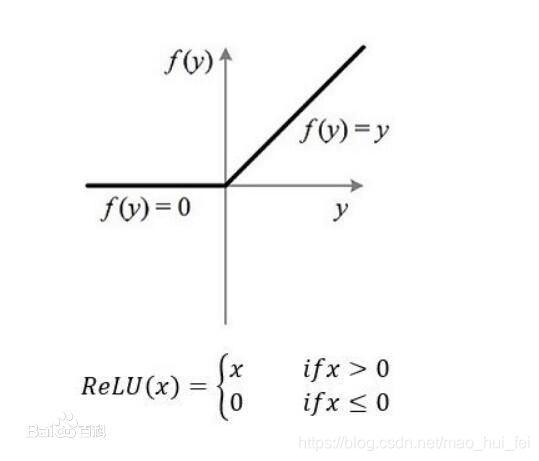
该函数就是常见的非线性激励函数,详细见我另一篇博客:深度学习中常用的非线性激励函数 https://blog.csdn.net/mao_hui_fei/article/details/104174801
