导图

本文介绍了mysqll数据库的基础语句,在命令行窗口进行演示。语句中[ ]里的内容表示可选项。
MySQL的SQL语句分类
- SQL:结构化查询语言
- DDL:数据定义语言:定义数据库、数据表的结构:create drop alter
- DML:数据操纵语言:主要是用来操作数据:insert update delete
- DCL:数据控制语言:定义访问权限,取消访问权限,安全设置:grant
- DQL:数据查询语言:select(查询),from子句,where子句
对数据库的CRUD操作
- 首先要登录数据库服务器:mysql -uroot -proot

创建数据库
常规创建
create database 数据库名字;
如:create database test1;
注意分号不能漏掉。
创建数据库时指定字符集
create database 数据库名字 character set 字符集;
例: create database test2 character set utf8;

创建数据库时指定校对规则
create database 数据库名字 character set 字符集 collate 校对规则;
例: create database test3 character set utf8 collate utf8_bin;

查看数据库
查看所有数据库
show databases;

其中的information_schema、performance_schema、mysql是默认库。
查看数据库定义的语句
show create database 数据库名;
例:show create database test3;

查看当前正在使用的数据库
select database();

修改数据库
修改数据库的字符集
alter database 数据库名字 character set 字符集;
例:alter database test3 character set gbk;

删除数据库
drop database 数据库名;
例:drop database test3;

其他数据库操作命令
切换(选中)数据库
use 数据库名:
例:use test2;
查看当前正在使用的数据库
select database();

对表的CRUD操作
创建表
create table 表名(
列名1 列的类型(长度) 约束,
列名2 列的类型(长度) 约束
);
列的类型
int
char:固定长度
varchar:可变长度
double
float
boolean
date: YY-MM-DD
time: hh:mm:ss
datetime: YY-MM-DD hh:mm:ss 默认值是null
timestamp: YY-MM-DD hh:mm:ss 默认值使用当前时间
text:主要用来存放文本
blob:存放二进制
列的约束
主键约束:primary key
唯一约束:unique
非空约束:not null
例:
创建一个表,先分析实体:学生
1.学生ID
2.姓名
3.性别
4.年龄
create table student(
sid int primary key,
sname varchar(31),
sex int,
age int
);
查看表
查看所有的表
show tables;

查看表的创建语句
show create table 表名;
例:查看刚才创建的学生表
show create table student;

查看表结构
desc 表名;
例:desc student;

修改表
添加列(add)
alter table 表名 add 列名 列的类型 列的约束;
例:alter table student add chengji int not null;

再次查看表结构,能看到已经成功添加了新列:

修改列(modify)
alter table 表名 modify 列名 列的类型 列的约束;
例:alter table student modify sex varchar(2);

修改列名(change)
alter table 表名 change 原列名 新列名 列的类型;
例:alter table student change sex gender varchar(2);

当然,通过change语句可以同时修改表名和表的类型。
删除列
alter table 表名 drop 列名;

修改表名
rename table 原表名 to 新表名;
例:rename table student to xuesheng;

修改表的字符集
alter table 表名 character set 字符集;
例:alter table xuesheng character set gbk;

删除表
drop table 表名;
例:drop table xuesheng;

对表中数据的CRUD操作
插入数据
完整写法
insert into 表名(列名1,列名2,列名3) values (值1,值2,值3);
例:insert into student(sid,sname,sex,age) values (1,“zhangsan”,1,23);

简单写法(省略列名)
前提是插入的数据必须是完整的(每个属性都必须赋值)
如果插入的是部分列,那么列名不能省略
insert into 表名 values (值1,值2,值3);
例1:insert into student values (2,“lisi”,1,23);

例2(省略列名且插入的不是完全列):insert into student values (3,“lisi”,1);
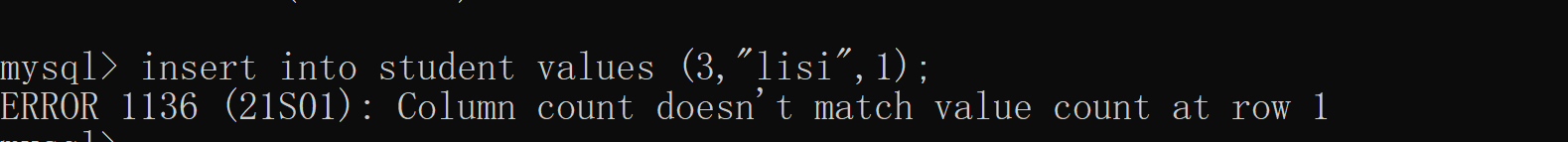
批量插入
insert into 表名 values (值1,值2,值3),(值1,值2,值3),(值1,值2,值3),(值1,值2,值3);
例:insert into student(sid,sname,sex,age) values (4,“zhangsan”,1,23),
(5,“zhangsan”,1,23),(6,“zhangsan”,1,23),(7,“zhangsan”,1,23),(8,“zhangsan”,1,23);

命令行下插入中文问题
- 临时解决方案
set names gbk;
相当于告诉mysql服务器软件,我们当前在命令行输入的内容是GBK编码,当命令窗口关闭后,它再输入中文就会有问题 - 永久解决方案
修改my.ini配置(在mysql软件安装路径里)

将编码改成GBK
删除记录
delete from 表名 [where 条件];
例:delete from student where sid=9;

注:若不写where条件,将会把表中记录全部删除
delete删除数据与truncate删除数据的区别
delete: DML 一条一条删除数据
truncate: DDL 先删除表再重建表
效率比较:若数据少,delete比较高效;若数据多,truncate比较高效
更新表记录
update 表名 set 列名=列值,列名2=列值2 [where 条件];
- 如果参数是字符串或日期,要加上单引号
- 如果不加where条件,那么整张表的记录都会被修改
例:将sid为5的记录的名字改成李四
update student set sname=‘李四’ where sid=5;

查询记录
select:选择显示哪些列的内容
distinct: 去除重复的数据
select [distinct] [*] [列名1,列名2] from 表名 [where 条件];
要测试查询语句,先建立一个案例表,并向其中插入测试数据
表1:商品分类
1.分类ID
2.分类名称
3.分类描述
create table category(
cid int primary key auto_increment,
cname varchar(10),
cdesc varchar(31)
);
insert into category values (null,'手机数码','电子产品,猪猪生产');
insert into category values (null,'鞋靴箱包','江南皮革厂生产');
insert into category values (null,'香烟酒水','茅台二锅头');
insert into category values (null,'酸奶饼干','蒙牛生产');
insert into category values (null,'馋嘴零食','花生瓜子八宝粥+辣条');

简单查询
查询所有列的信息:
select * from category;
查询指定列:
要查询指定的列,那么加*换成需要查询的列名:
select cname,cdesc from category;

表2:商品
1.商品ID
2.商品名称
3.商品的价格
4.生产日期
5.商品分类ID
商品和商品分类:所属关系
create table product(
pid int primary key auto_increment,
pname varchar(10),
price double,
pdate timestamp not null default CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
pno int
);
insert into product (pid,pname,price,pno)values(null,'华为p30',4999,1);
insert into product (pid,pname,price,pno)values(null,'红米note4',1999,1);
insert into product (pid,pname,price,pno)values(null,'耐克',499,2);
insert into product (pid,pname,price,pno)values(null,'老村长',88,3);
insert into product (pid,pname,price,pno)values(null,'劲酒',35,3);
insert into product (pid,pname,price,pno)values(null,'小熊饼干',4,4);
insert into product (pid,pname,price,pno)values(null,'卫龙辣条',2,5);
insert into product (pid,pname,price,pno)values(null,'旺旺雪饼',3,5);
(注1:建表时,关于timestamp类型的字段,定义时的属性可参考https://blog.csdn.net/fsp88927/article/details/80662369)
(注2:插入数据时,类型为timestamp的列不需要赋值)

- 查询所有的商品
select * from product;
- 查询商品名称和商品价格
select pname,price from product;

别名查询
别名查询用的是as关键字,关键字可以省略
- 表别名(主要用在多表查询)
select p.pname , p.price from product [as] p;

- 列别名(为了使查询结果更易读)
select pname [as] 商品名称 ,price [as] 商品价格 from product;
select pname as 商品名称 ,price as 商品价格 from product;
select pname 商品名称 ,price 商品价格 from product;
以上两句效果是一样的。

去掉重复的值
为了演示,向表中插入数据,使商品出现相同的价格
insert into product (pid,pname,price,pno)values(null,'士力架',3,5);
insert into product (pid,pname,price,pno)values(null,'牛肉干',3,5);
执行普通查询语句,查询商品的价格:
select price from product;

要达到去重的效果,需要在select之后加上distinct关键字。
select distinct price from product;

运算查询
仅仅在查询结果上做了运算
select *, price*0.9 as 折后价 from product;

条件查询
[where 关键字]
指定条件,确定要操作的记录
- 查询商品价格>60的所有商品信息
select * from product where price>60;

- where 后的条件写法
关系运算符:> ,< , >= ,<= ,!=,< >
< >:不等于 标准SQL语法
!=:不等于 非标准SQL语法
逻辑运算:and or not
- 查询商品价格在10到100之间所有商品信息
select * from product where price>10 and price <100;
select * from product where price between 10 and 100;
模糊查询
关键字:like
_ : 表示一个字符
%: 表示多个字符
- 例:查询出名字中带有“干”的所有商品(’%干%’)
select * from product where pname like '%干%';

- 例:查询出名字中第二个字为"力"的所有商品(’_力%’)
select * from product where pname like '_力%';

范围查询
关键字:in 用来限定列中的某个范围以查找范围中的值
- 例:查询出商品分类id在1,4,5中的所有商品
select * from product where pno in (1,4,5);

排序查询
关键字:order by
asc :ascend 升序(默认的排序方式)
desc :descend 降序
- 例:查询所有商品,按照价格进行排序
select * from product order by price;

从图中可以看出默认的排序方式是升序。
- 例:查询所有商品,按照价格进行降序排序
select * from product order by price desc;

- 例:查询名称中有“干”的商品并按照价格进行升序排序
select * from product where pname like '%干%' order by price asc;

聚合函数
sunm():求和
avg():求平均值
count():统计数量
max():最大值
min():最小值
- 获得所有商品价格的总和:
select sum(price) from product;

- 获得所有商品的平均价格:
select avg(price) from product;

- 获得所有商品的数量
select count(*) from product;

-
注意:where条件后不能写聚合函数
-
例:查出商品价格大于平均价格的所有商品
错误写法:
select * from product where price>avg(price);

正确写法是使用子查询:
select * from product where price >(select avg(price) from product);

分组与筛选
关键字:group by
- 例1:根据pno字段分组,分组后统计每组中的商品个数
select pno,count(*) from product group by pno;

- 例2:根据pno分组,分组统计每组商品的平均价格,平均价格需要大于60
select pno,avg(price) from product group by pno having avg(price) > 60;

值得注意的是,having (条件筛选)关键字是可以接聚合函数的
查询语句的编写与执行顺序
编写顺序
select...from...where...group by...having..order by
执行顺序
from...where...group by...having...select...order by
