一、数据库的多表连接查询,inner的不同用法
在pg数据库中建立两张表:
t_a和t_b如下所示:
t_a:
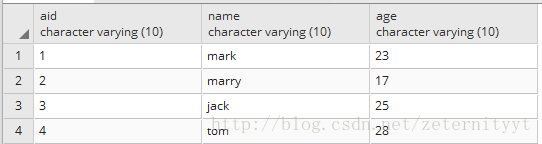
t_b:

1、inner join(内连接)
inner join就是根据on字段标示出来的条件,查询关联的表中符合条件的数据,并把他前部都显示出来,形成一个结果集。
执行如下语句:
select * from t_a inner join t_b on t_a.adi=t_b.bid
得到的结果为:
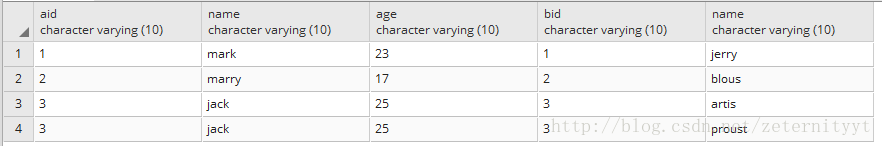
这样的查询会显示出所有的数据,如果我们仅仅需要一部分的数据(例如我们只想查出t_a中所有aid和t_b中的bid相同的数据),那么查询语句应该变成:
select t_a.* from t_a inner join t_b on t_a.aid=t_b.bid
那么得到的数据如下所示,就只显示了t_a表中的数据。如下:
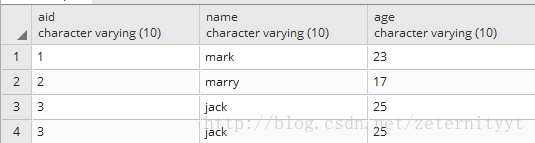
要排除重复的数据,在select后加distinct即可。
2、left join
left join 就是以表t_a为基础从右表t_b中查询出所有符合on条件的结果,在合并到表t_a中对应的部分,再作为一个结果集输出,在结果集中,会显示出表t_a中的所有数据。
执行如下查询语句:
select * from t_a left join t_b on t_a.aid=t_b.bid
得到如下结果:

可以看到,在查询的结果中,有一行关于表t_b的数据都为null,因为表t_b中没有符合on条件的数据。但是表t_a表显示出了全部的数据。那么在需要筛选的时候,应该着重于筛选表t_b中的数据,如果执行如下的语句:
select t_a.* from t_a left join t_b on t_a.aid=t_b.bid
那么得到的就是表t_a中的所有数据,那么这个查询就显得没有意义了。
3、right join
right join 就是以表t_b为基础从左表t_a中查询出所有符合on条件的结果,在合并到表t_b中对应的部分,再作为一个结果集输出,在结果集中,会显示出表t_b中的所有数据。
执行如下查询语句:
select * from t_a right join t_b on t_a.aid=t_b.bid
得到的结果为:

可以看到,查询的结果中,有两行数据在表t_a的对应部分都是null的,表示表t_a中没有符合on条件的数据,但是表t_b显示了全部的数据,那么需要做条件筛选的时候,我们就应该主要针对表t_a进行筛选。
二、查询一个父级的所有子级(包括子级的子级)
在pg数据库中建立一张表t_c如下:
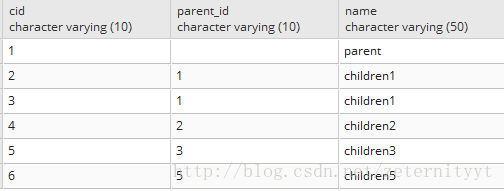
要查出cid为1的所有的子级、包括cid为2、3、5的子级的集合。执行以下sql语句
with recursive tb as(select * from t_c where parent_id='1' union all select t_c.* from t_c,tb where t_c.parent_id=tb.cid )select * from tb
得到如下的结果:

由查询出的结果集可以看到,我们查询出了除了父级(cid为1)以外的所有cid为父级的子级以及子级的子级。
我们来解析一下这个sql语句:
显而易见的,这是一个递归的查询方法。首先是with为查询语句提供了辅助功能,可以看做是查询语句中的临时表,其次recursive是sql中递归的关键字,只有有了这个关键字,pg才知道with这个语句需要做递归操作。union all是去重的,t_c.parent_id=tb.cid 表示了t_c的parent_id要等于临时表tb的cid要在整个with语句的外面查询建立的临时表tb,才能得到所有的子级的集合。