文章目录
- 上传hadoop压缩包到opt下,解压
- 进入以下路径,做一些配置修改 ./hadoop-2.7.2/etc/hadoop/
- 编辑hadoop-env.sh 配置自己jdk路径
- 编辑core-site.xml ,配置ip,端口,读取文件缓冲大小
- 编辑hdfs-site.xml,配置副本数等。看图
- 复制并修改一个配置名字
- 编辑mapred-site.xml,配置框架名字,历史记录组件等
- 编辑yarn-site.xml ,配置resourcemanager的相关信息
- 编辑slaves
- 配置映射信息
- 假如是多台虚拟机,可将配置好的hadoop目录发送给其他虚拟机
- 每台机器 都配置环境变量
- 配置ssh免登陆,生成ssh免登陆密钥
- 格式化hadoop的namenode服务
- 启动服务查看
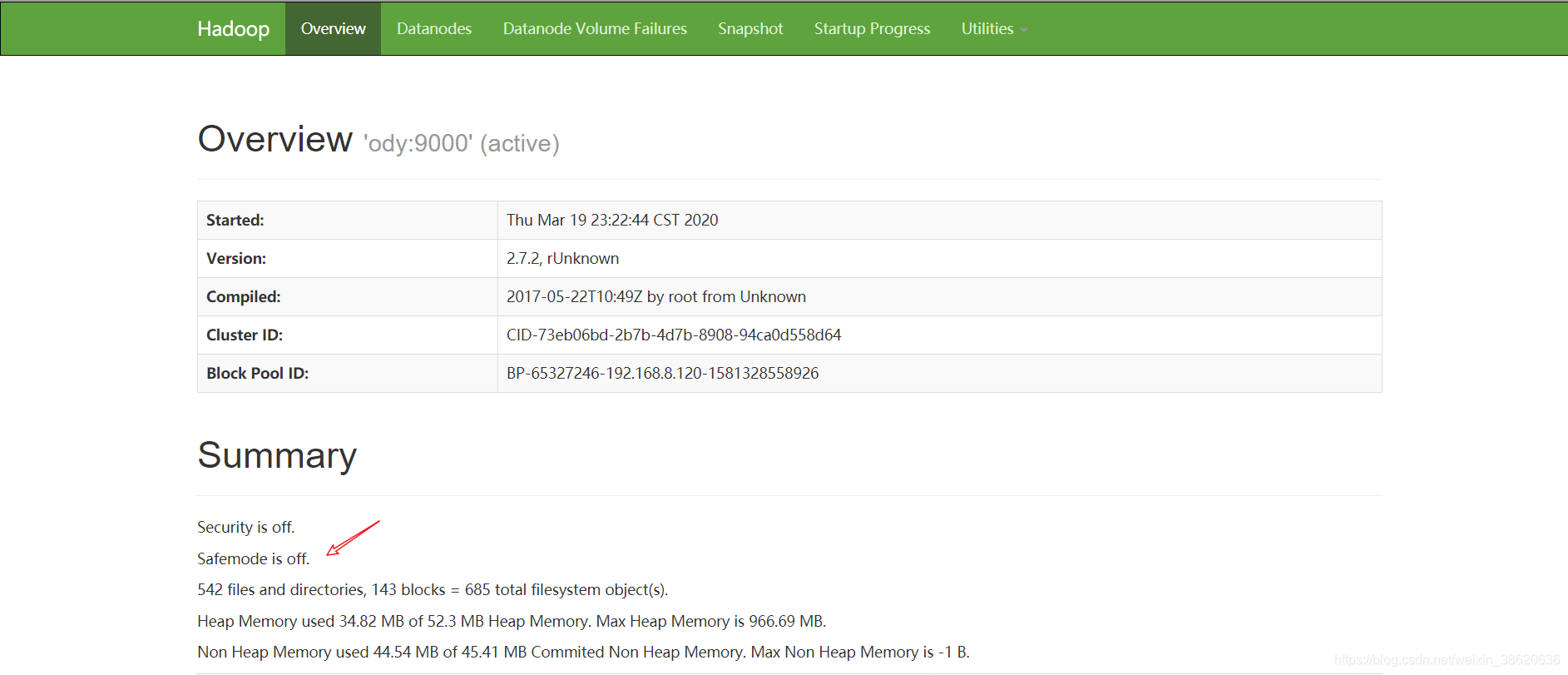
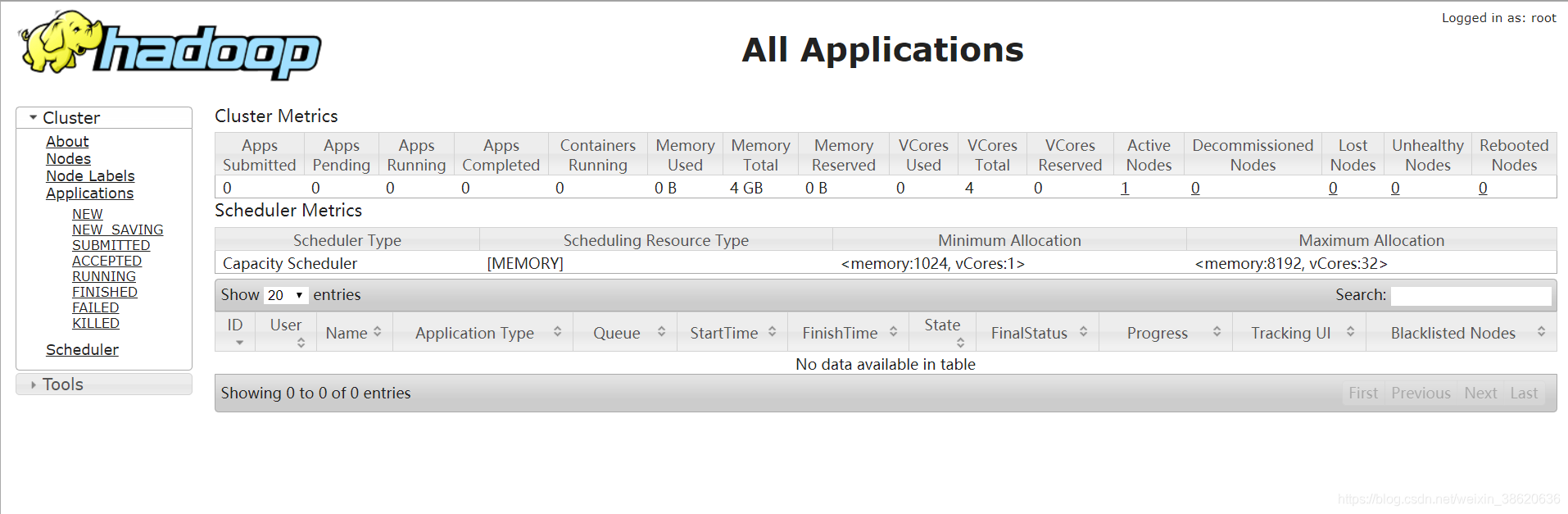
- 通过web UI查看HDFS和yarn集群是否正常
温馨建议:可以将所有组件安装到固定目录,如:我这边放到了opt目录下。
/opt
上传hadoop压缩包到opt下,解压
tar -zxvf /software/hadoop-2.7.2.tar.gz -C /opt/
进入以下路径,做一些配置修改 ./hadoop-2.7.2/etc/hadoop/
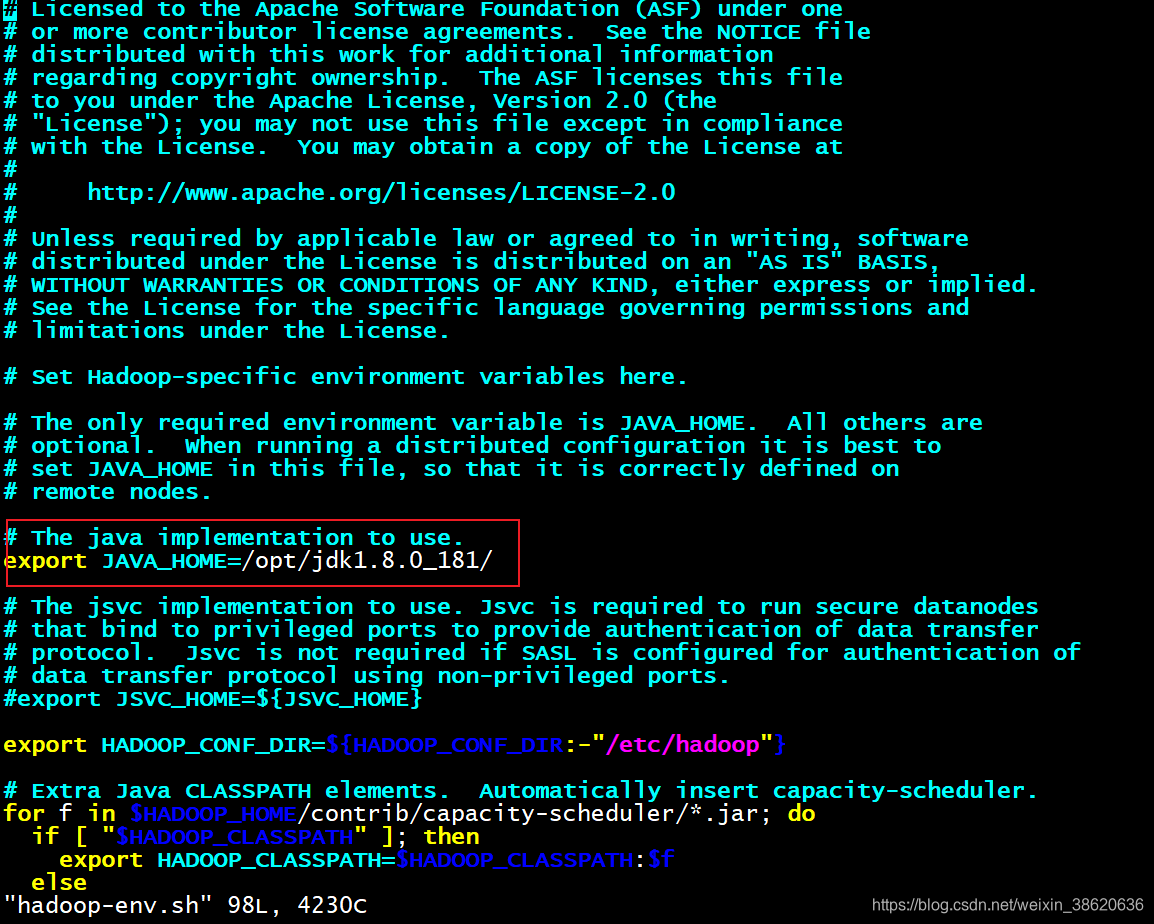
编辑hadoop-env.sh 配置自己jdk路径
编辑core-site.xml ,配置ip,端口,读取文件缓冲大小
<!--配置HDFS文件系统的命名空间-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://houda这里写自己的ip或者用户名:9000</value>
</property>
<!--HDFS读取文件的缓冲大小-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
编辑hdfs-site.xml,配置副本数等。看图
将里面的用户名改为自己的即可
<!--配置hdfs文件系统的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定hdfs文件系统的元数据存放目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoopdata/dfs/name</value>
</property>
<!--指定hdfs文件系统的数据块存放目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoopdata/dfs/data</value>
</property>
<!--配置HDFS的web管理地址-->
<property>
<name>dfs.http.address</name>
<value>houda:50070</value>
</property>
<!--配置secondaryNamenode的web管理地址-->
<property>
<name>dfs.secondary.http.address</name>
<value>houda02:50090</value>
</property>
<!--配置是否打开web管理-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--指定hdfs文件系统权限是否开启-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
复制并修改一个配置名字
cp mapred-site.xml.template mapred-site.xml
编辑mapred-site.xml,配置框架名字,历史记录组件等
<!--指定mapreduce运行的框架名-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<final>true</final>
</property>
<!--配置mapreduce的历史记录组件的内部通信地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>houda:10020</value>
</property>
<!--配置mapreduce的历史记录服务的web管理地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>houda:19888</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
编辑yarn-site.xml ,配置resourcemanager的相关信息
<!-- Site specific YARN configuration properties -->
<!--指定resourcemanager所启动服务的主机名/ip-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>houda</value>
</property>
<!--指定mapreduce的shuffle处理数据方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置resourcemanager内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>houda:8032</value>
</property>
<!--配置resourcemanager的scheduler组件的内部通信地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>houda:8030</value>
</property>
<!--配置resource-tracker组件的内部通信地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>houda:8031</value>
</property>
<!--配置resourcemanager的admin的内部通信地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>houda:8033</value>
</property>
<!--配置yarn的web管理地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>houda:8088</value>
</property>
<!--yarn的聚合日志是否开启-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--聚合日志报错hdfs上的时间-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!--聚合日志的检查时间段-->
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>3600</value>
</property>
<!---->
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
</property>
<!--当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效)-->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/opt/hadoopdata/logs</value>
</property>
编辑slaves
slaves中写虚拟机的主机名字,有几台虚拟机,就写几个虚拟机的主机名
我这边一个测试

配置映射信息
vim /etc/hosts

假如是多台虚拟机,可将配置好的hadoop目录发送给其他虚拟机
scp /opt/hadoop-2.7.2/ root@192.168.8.121 /opt/
每台机器 都配置环境变量
vim /etc/profile

配置ssh免登陆,生成ssh免登陆密钥
ssh-keygen -t rsa (无脑敲四个回车)
//执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
//将公钥拷贝到要免登陆的机器上
这边需要说明:多台虚拟机,就需要多发几次
ssh-copy-id ody
格式化hadoop的namenode服务
hadoop namenode -format
启动服务查看
start-all.sh
通过web UI查看HDFS和yarn集群是否正常