趁今天有点时间,整理下oj题型C/C++的一些标准库函数的使用!
1、快排
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
int a[]={2,3,6,9,10,2,0};
int i;
int len=sizeof(a)/sizeof(int);
sort(a,a+len) ;
printf("%d\n",len);
for(i=0;i<len;i++)
printf("%d,",a[i]);
return 0;
} 2、去重(注意unique返回的是去重后的最后一个元素地址,必须先排序)
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
int a[]={2,2,3,3,6,5,7};
int len=sizeof(a)/sizeof(int);
sort(a,a+len);
int count=unique(a,a+len)-a;
printf("不重复有%d个\n",count);
for(int i=0;i<count;i++)
printf("%d,",a[i]);
return 0;
} 
3、最大公约数
int gcd(int a,int b){ return b?gcd(b,a%b):a;}
4、最下公倍数
lcm = a * b / gcd(a,b)
5、字符数组转换为整型(注意:只能是char[],如果用string的话,会出错的)
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
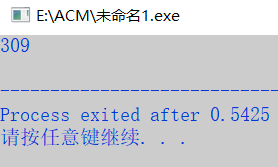
char a[]={'3','0','9'};
int n;
sscanf(a,"%d",&n);
printf("%d\n",n);
return 0;
} 
char s[100];
int x=atoi(s);
上面两行代码也可以将s转为数字。
6、求n!的位数
for(int i=2;i<=n;i++)
Len+=log10(i*1.0);
ans=(int)len+1;
斯特林公式:这里求到的数和原本的实际值相差不大,故求位数不影响
len=0.5*log10(2*3.1415927*n)+n*log10(n/2.718281828459);
ans=(int)len+1;
7、Log与自然对数e
Log(x)表示ln(x)
其他例如:log10(x) ,log2(x),
用exp(x)来表示e^x
8、素数(N以内有大概num=N/ln(x)个素数,N越大越准)
简单素数打表:O(n*sqrt(n))
void prim(){
int num = 0;
for (int i = 2; i < maxn; i++){
int k = 1;
for (int j = 2; j <= (int)sqrt(i);j++)
if (i%j == 0) { k = 0; break; }
if (k) pri[num++] = i;
}
}
高效素数打表:O(n)
(线性筛选法——欧拉筛法)
/*
|埃式筛法|
|快速筛选素数|
*/
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
int prime[100];
bool is_prime[100];
int sieve(int n){
int p = 0;
for(int i = 0; i <= n; ++i)
is_prime[i] = true;
is_prime[0] = is_prime[1] = false;
for (int i = 2; i <= n; ++i){ // 注意数组大小是n
if(is_prime[i]){
prime[p++] = i;
for(int j = i + i; j <= n; j += i) // 轻剪枝,j必定是i的倍数
is_prime[j] = false;
}
}
return p; // 返回素数个数
}
int main()
{
int len=sieve(50);
for(int i=0;i<len;i++)
{
printf("%d,",prime[i]);
}
return 0;
}9、分解质因数
首先理解什么叫做合数:除了能被1与本身整除外还能被其他非0数整除,最下合数是4。与之对应的是素数也就是质数。
每个合数都可以写成几个质数(素数)相乘的形式,其中每个质数都是这个合数的因数,把一个合数用质因数相乘的形式表示出来,叫做分解质因数。如30=2×3×5 。分解质因数只针对合数。
要用到容器,所以参考https://blog.csdn.net/u013719339/article/details/80615217
向量基本操作
//初始化
vector<int> vec //默认初始化,空
vector<int> vec2(vec); //使用vec初始化vec2
vector<int> vec3(3); //初始化3个值为0的元素
vector<int> vec4(4, 1); //初始化4个值为1的元素
vector<string> vec5(5,"null"); //初始化5个值为null的元素
vector<string> vec6(6,"hello"); //初始化6个值为hello的元素
//常用的操作方法
vec.push_back(3) //向末尾添加元素3
vec.end(); //返回指向末尾下一位置的迭代器
int size = vec.size() //一共的元素个数
bool isEmpty = vec.empty(); //判断是否为空
cout<<vec[0]<<endl; //取得第一个元素
vec.insert(vec.end(),5,3); //从末尾下一位置插入5个值为3的元素
vec.pop_back(); //删除末尾元素
vec.erase(vec.begin(),vec.end());//删除之间的元素,其他元素前移
cout<<(vec==vec2)?true:false; //判断是否相等==、!=、>=、<=...
vector<int>::iterator iter = vec.begin(); //获取迭代器首地址
vector<int>::const_iterator c_iter = vec.begin(); //获取const类型迭代器
vec.clear(); //清空元素
//遍历方法
//下标法(vector的特有访问方法,一般容器只能通过迭代器访问)
int length = vec1.size();
for(int i=0;i<length;i++)
{
cout<<vec1[i];
}
cout<<endl<<endl;
//迭代器法
vector<int>::const_iterator iterator = vec1.begin();
for(; iterator != vec1.end(); iterator++)
{
cout<<*iterator;
}
//赋值与swap
vector<string> vs1(3); // vs1有3个元素
vector<string> vs(5); // vs2有5个元素
vs1.swap(vs2); //执行后,vs1中5个元素,而vs2则存3个元素列表基本操作:
//初始化
list<int> lst1; //创建空list
list<int> lst2(3); //创建含有三个元素的list
list<int> lst3(3,2); //创建含有三个元素的值为2的list
list<int> lst4(lst2); //使用lst2初始化lst4
//常用的操作方法
lst1.assign(lst2.begin(),lst2.end()); //分配值
lst1.push_back(10); //添加值
lst1.pop_back(); //删除末尾值
lst1.begin(); //返回首值的迭代器
lst1.end(); //返回末尾位置下一位的迭代器
lst1.clear();//清空值
bool isEmpty1 = lst1.empty(); //判断为空
lst1.erase(lst1.begin(),lst1.end()); //删除元素
lst1.front(); //返回第一个元素的引用
lst1.back(); //返回最后一个元素的引用
lst1.insert(lst1.begin(),3,2); //从指定位置插入3个值为2的元素
lst1.rbegin(); //返回第一个元素的前向指针
lst1.remove(2); //相同的元素全部删除
lst1.reverse(); //反转
lst1.size(); //含有元素个数
lst1.sort(); //排序
lst1.unique(); //删除相邻重复元素
//遍历方法
//迭代器法
for(list<int>::const_iterator iter = lst1.begin();iter != lst1.end();iter++)
{
cout<<*iter;
}
cout<<endl;
//赋值与swap
list<string> sl1,sl2;
for(int i=0;i<10;i++)sl2.push_back("a");
sl1.assign(10, "A"); //s1被重新赋值,拥有十个元素,都为A分解质因数

#include<iostream>
#include<algorithm>
#include<cstring> //memset() 初始化与字符串操作
#include<cmath> //数学库
#include<vector> //向量
using namespace std;
vector<int> p;
void fun(long long x) {//得到的是所有质因数 eg:24=》 2,2,2,3
p.clear();
for (long long i = 2; i <=sqrt(x); i++){
while (x%i == 0){
p.push_back(i);
x /= i;
}
}
if (x != 1) p.push_back(x);
}
int main()
{
fun(24);
for(int i=0;i<p.size();i++)
printf("%d,",p[i]);
return 0;
}10、吉姆拉尔森公式
1.用途:给你年月日,计算今天星期几
2.公式:Week = (d+2*m+3*(m+1)/5+y+y/4-y/100+y/400+1) mod 7;
其中: d为几号,m为月份,y为年份
3.注:把一月和二月看为是上一年的十三月和十四月!!
int CaculateWeekDay(int y,int m, int d)
{
if(m==1||m==2){//一二月换算
m+=12;
y--;
}
int week = (d + 2*m +3*(m+1)/5 + y + y/4 - y/100 + y/400 + 1)%7;
return week;//其中1~7表示周一到周日
}
int main()
{
printf("%d,",CaculateWeekDay(2019,4,20));
return 0;
}11、高精度计算n!;
#include<iostream>
#include<algorithm>
#include<cstring>
#include<cmath>
using namespace std;
int factorial(int n)
{
long a[10000];
int i,j,l,c,m=0,w;
a[0]=1;
for(i=1;i<=n;i++)
{
c=0;
for(j=0;j<=m;j++)
{
a[j]=a[j]*i+c;
c=a[j]/10000;
a[j]=a[j]%10000;
}
if(c>0)
{
m++;
a[m]=c;
}
}
w=m*4+log10(a[m])+1;
printf("%ld",a[m]) ;
for(i=m-1;i>=0;i--)
printf("%4.4ld",a[i]);
return w;
}
int main()
{
printf("\n一共%d位!\n",factorial(10));
return 0;
} 12、高精度计算乘法
13、高精度计算加法
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
/*
|大数模拟加法|
|用string模拟|
*/
string add(string s1, string s2)
{
if (s1 == "" && s2 == "") return "0";
if (s1 == "") return s2;
if (s2 == "") return s1;
string maxx = s1, minn = s2;
if (s1.length() < s2.length()){
maxx = s2;
minn = s1;
}
int a = maxx.length() - 1, b = minn.length() - 1;
for (int i = b; i >= 0; --i){
maxx[a--] += minn[i] - '0'; // a一直在减 , 额外还要减个'0'
}
for (int i = maxx.length()-1; i > 0;--i){
if (maxx[i] > '9'){
maxx[i] -= 10;//注意这个是减10
maxx[i - 1]++;
}
}
if (maxx[0] > '9'){
maxx[0] -= 10;
maxx = '1' + maxx;
}
return maxx;
}
int main()
{
string result;
result=add("11111111","22222222");
printf("%s\n",result.c_str());
printf("len=%d",strlen(result.c_str()));
return 0;
}14、高精度计算减法
15、快速幂(计算a^b mod m)
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
/*
|快速幂|
*/
typedef long long LL; // 视数据大小的情况而定
LL powerMod(LL x, LL n, LL m)
{
LL res = 1;
while (n > 0){
if (n & 1) // 判断是否为奇数,若是则true
res = (res * x) % m;
x = (x * x) % m;
n >>= 1; // 相当于n /= 2;
}
return res;
}
int main()
{
// 计算x^n mod m
int x=powerMod(3,2,5);
printf("%lld",x);
return 0;
}16、全排列
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
int list[]={1,2,3,4,5,6};
void Pern(int list[], int k, int n) { // k表示前k个数不动仅移动后面n-k位数
if (k == n - 1) {
for (int i = 0; i < n; i++) {
printf("%d", list[i]);
}
printf("\n");
}else {
for (int i = k; i < n; i++) { // 输出的是满足移动条件所有全排列
swap(list[k], list[i]);
Pern(list, k + 1, n);
swap(list[k], list[i]);
}
}
}
int main()
{
Pern(list,3,6);
return 0;
}17、二分搜索
// 1.求最小的i,使得a[i] = key,若不存在,则返回-1
int ans = std::lower_bound(a, a + n, key) - a;
ans = (ans == n || a[ans] != key) ? -1 : ans;
// 2.求最大的i,使得a[i] = key,若不存在,则返回-1
int ans = std::upper_bound(a, a + n, key) - a;
ans = (ans == 0 || a[ans - 1] != key) ? -1 : ans - 1;
// 3.求最小的i,使得a[i] > key,若不存在,则返回-1
int ans = std::upper_bound(a, a + n, key) - a;
ans = (ans == n) ? -1 : ans;
// 4.求最大的i,使得a[i] < key,若不存在,则返回-1
int ans = std::lower_bound(a, a + n, key) - a;
ans = (ans == 0) ? -1 : ans - 1;
18、
=============图====论===============
MST
最小生成树
Kruskal(克鲁斯卡尔算法)
/*
|Kruskal算法|
|适用于 稀疏图 求最小生成树|
|16/11/05ztx thanks to wangqiqi|
*/
/*
第一步:点、边、加入vector,把所有边按从小到大排序
第二步:并查集部分 + 下面的code
*/
void Kruskal() {
ans = 0;
for (int i = 0; i<len; i++) {
if (Find(edge[i].a) != Find(edge[i].b)) {
Union(edge[i].a, edge[i].b);
ans += edge[i].len;
}
}
} 19、
Prim:普里姆算法
/*
|Prim算法|
|适用于 稠密图 求最小生成树|
|堆优化版,时间复杂度:O(elgn)|
|16/11/05ztx, thanks to chaixiaojun|
*/
struct node {
int v, len;
node(int v = 0, int len = 0) :v(v), len(len) {}
bool operator < (const node &a)const { // 加入队列的元素自动按距离从小到大排序
return len> a.len;
}
};
vector<node> G[maxn];
int vis[maxn];
int dis[maxn];
void init() {
for (int i = 0; i<maxn; i++) {
G[i].clear();
dis[i] = INF;
vis[i] = false;
}
}
int Prim(int s) {
priority_queue<node>Q; // 定义优先队列
int ans = 0;
Q.push(node(s,0)); // 起点加入队列
while (!Q.empty()) {
node now = Q.top(); Q.pop(); // 取出距离最小的点
int v = now.v;
if (vis[v]) continue; // 同一个节点,可能会推入2次或2次以上队列,这样第一个被标记后,剩下的需要直接跳过。
vis[v] = true; // 标记一下
ans += now.len;
for (int i = 0; i<G[v].size(); i++) { // 开始更新
int v2 = G[v][i].v;
int len = G[v][i].len;
if (!vis[v2] && dis[v2] > len) {
dis[v2] = len;
Q.push(node(v2, dis[v2])); // 更新的点加入队列并排序
}
}
}
return ans;
} 20、
Bellman-Ford
单源最短路
Dijkstra:迪杰斯特拉算法
/*
|Dijkstra算法|
|适用于边权为正的有向图或者无向图|
|求从单个源点出发,到所有节点的最短路|
|优化版:时间复杂度 O(elbn)|
|16/11/05ztx, thanks to chaixiaojun|
*/
struct node {
int v, len;
node(int v = 0, int len = 0) :v(v), len(len) {}
bool operator < (const node &a)const { // 距离从小到大排序
return len > a.len;
}
};
vector<node>G[maxn];
bool vis[maxn];
int dis[maxn];
void init() {
for (int i = 0; i<maxn; i++) {
G[i].clear();
vis[i] = false;
dis[i] = INF;
}
}
int dijkstra(int s, int e) {
priority_queue<node>Q;
Q.push(node(s, 0)); // 加入队列并排序
dis[s] = 0;
while (!Q.empty()) {
node now = Q.top(); // 取出当前最小的
Q.pop();
int v = now.v;
if (vis[v]) continue; // 如果标记过了, 直接continue
vis[v] = true;
for (int i = 0; i<G[v].size(); i++) { // 更新
int v2 = G[v][i].v;
int len = G[v][i].len;
if (!vis[v2] && dis[v2] > dis[v] + len) {
dis[v2] = dis[v] + len;
Q.push(node(v2, dis[v2]));
}
}
}
return dis[e];
} 21、
SPFA.最短路径快速算法(Shortest Path Faster Algorithm)
/*
|SPFA算法|
|队列优化|
|可处理负环|
*/
vector<node> G[maxn];
bool inqueue[maxn];
int dist[maxn];
void Init()
{
for(int i = 0 ; i < maxn ; ++i){
G[i].clear();
dist[i] = INF;
}
}
int SPFA(int s,int e)
{
int v1,v2,weight;
queue<int> Q;
memset(inqueue,false,sizeof(inqueue)); // 标记是否在队列中
memset(cnt,0,sizeof(cnt)); // 加入队列的次数
dist[s] = 0;
Q.push(s); // 起点加入队列
inqueue[s] = true; // 标记
while(!Q.empty()){
v1 = Q.front();
Q.pop();
inqueue[v1] = false; // 取消标记
for(int i = 0 ; i < G[v1].size() ; ++i){ // 搜索v1的链表
v2 = G[v1][i].vex;
weight = G[v1][i].weight;
if(dist[v2] > dist[v1] + weight){ // 松弛操作
dist[v2] = dist[v1] + weight;
if(inqueue[v2] == false){ // 再次加入队列
inqueue[v2] = true;
//cnt[v2]++; // 判负环
//if(cnt[v2] > n) return -1;
Q.push(v2);
} } }
}
return dist[e];
}
/*
不断的将s的邻接点加入队列,取出不断的进行松弛操作,直到队列为空
如果一个结点被加入队列超过n-1次,那么显然图中有负环
*/22、
Floyd-Warshall:弗洛伊德算法
/*
|Floyd算法|
|任意点对最短路算法|
|求图中任意两点的最短距离的算法|
*/
for (int i = 0; i < n; i++) { // 初始化为0
for (int j = 0; j < n; j++)
scanf("%lf", &dis[i][j]);
}
for (int k = 0; k < n; k++) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
dis[i][j] = min(dis[i][j], dis[i][k] + dis[k][j]);
}
}
}23、===========二分图==============
24、染色法
/*
|交叉染色法判断二分图|
|16/11/05ztx|
*/
int bipartite(int s) {
int u, v;
queue<int>Q;
color[s] = 1;
Q.push(s);
while (!Q.empty()) {
u = Q.front();
Q.pop();
for (int i = 0; i < G[u].size(); i++) {
v = G[u][i];
if (color[v] == 0) {
color[v] = -color[u];
Q.push(v);
}
else if (color[v] == color[u])
return 0;
}
}
return 1;
} 25、匈牙利算法
/*
|求解最大匹配问题|
|递归实现|
|16/11/05ztx|
*/
vector<int>G[maxn];
bool inpath[maxn]; // 标记
int match[maxn]; // 记录匹配对象
void init()
{
memset(match, -1, sizeof(match));
for (int i = 0; i < maxn; ++i) {
G[i].clear();
}
}
bool findpath(int k) {
for (int i = 0; i < G[k].size(); ++i) {
int v = G[k][i];
if (!inpath[v]) {
inpath[v] = true;
if (match[v] == -1 || findpath(match[v])) { // 递归
match[v] = k; // 即匹配对象是“k妹子”的
return true;
}
}
}
return false;
}
void hungary() {
int cnt = 0;
for (int i = 1; i <= m; i++) { // m为需要匹配的“妹子”数
memset(inpath, false, sizeof(inpath)); // 每次都要初始化
if (findpath(i)) cnt++;
}
cout << cnt << endl;
} 26、求解最大匹配问题
/*
|求解最大匹配问题|
|dfs实现|
|16/11/05ztx|
*/
int v1, v2;
bool Map[501][501];
bool visit[501];
int link[501];
int result;
bool dfs(int x) {
for (int y = 1; y <= v2; ++y) {
if (Map[x][y] && !visit[y]) {
visit[y] = true;
if (link[y] == 0 || dfs(link[y])) {
link[y] = x;
return true;
} } }
return false;
}
void Search() {
for (int x = 1; x <= v1; x++) {
memset(visit,false,sizeof(visit));
if (dfs(x))
result++;
}
}27、
28、
29、
扫描二维码关注公众号,回复:
10015663 查看本文章

30、
声明:我是大自然的搬运工,请叫我农夫山泉。上文很多内容搬运以下两位博主,详情参考原创!
https://blog.csdn.net/qq_32265245/article/details/53046750
https://blog.csdn.net/weixin_41156591/article/details/81809496
