写在前面:
系统环境:Windows 10
软件环境:360急速浏览器11.0,内核版本69(基于Chromium)
URL在浏览器中编码
在使用爬虫过程中,我们常常要对URL地址进行处理:在发包时对字符串进行编码;在接收数据时,对参数进行解码。由于现在常见的浏览器已经都对URL中的字符进行了解码,因此在使用浏览器时,地址栏中已经做到了正常中文字符

通过浏览器的调试工具,能够查看到在网络上编码传输的地址
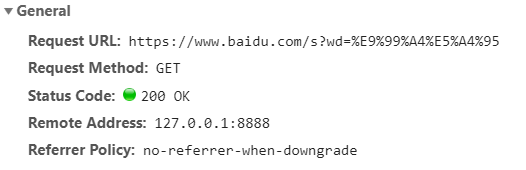
由此可以发现:
| 中文字符 | 编码字符 |
|---|---|
| 除 | %E9%99%A4 |
| 夕 | %E5%A4%95 |
正常显示的中文字符,编码后转换为一串由 %+字母/数字 的字符串,在这个字符串中的 百分号(%) 是浏览器作为字符边界的一个标志,字符/数字 的组合是UTF-8格式下的汉字对应的编码。
Unicode字符集与UTF-8编码规则
在查找对应码表之前,需要先明确一下,Unicode与UTF-8这个两个常见名词的关系。
- Unicode:统一码、万国码。是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
- UTF-8:是针对Unicode的一种可变长度字符编码。它可以用来表示Unicode标准中的任何字符,而且其编码中的第一个字节仍与ASCII相容。
以上定义来自百度百科,有这两条定义可以发现二者的联系特别的紧密:UTF-8是Unicode字符集的一种计算机编码实现方案。Unicode解决的问题时在数学上为每一个字符提供 统一且唯一 的二进制编码,而UTF-8是将Unicode的二进制编码让计算机能存储的理解和处理的一种实现方案。
UTF-8转换表
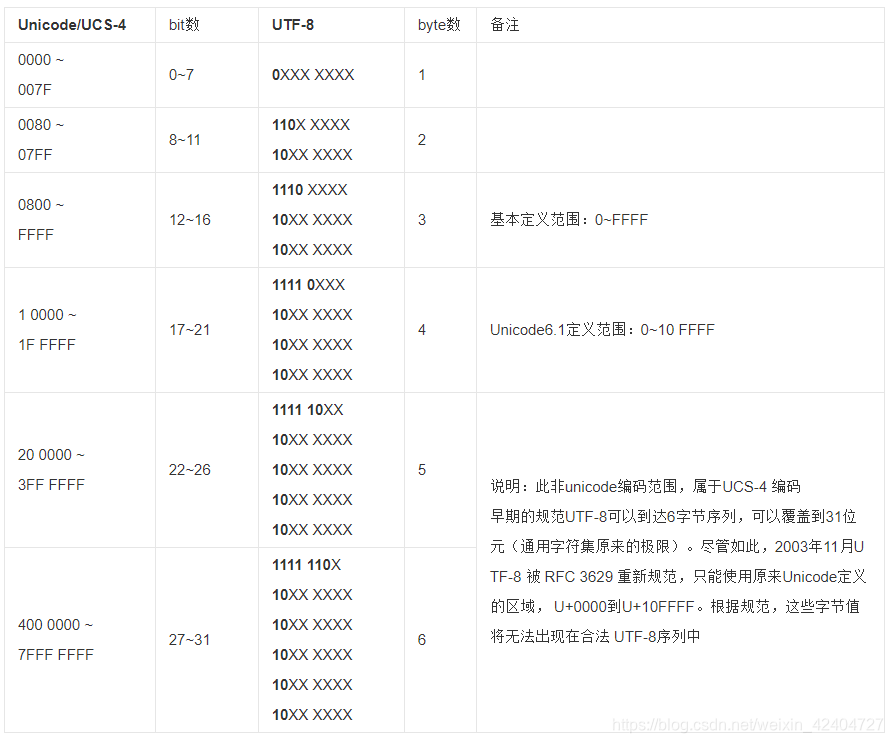
从百度百科找到上表,我们能够查找到Unicode编码与UTF-8的对应关系。在借用一些第三方的查询工具,很容易的出一下表格:通过Unicode编码16进制找到对行,在用Unicode编码的二进制带入,则可以得到UTF-8的16进制编码。
| 字符 | UTF-8编码10进制 | UTF-8编码16进制 | Unicode编码10进制 | Unicode编码16进制 |
| 除 | 15309220 | E9 99 A4 | 38500 | 9664 |
| 夕 | 15049877 | E5 A4 95 | 22805 | 5915 |
转换规则
接下来,探究一下带入的方式,首先由Unicode编码16进制表示得出Unicode编码二进制表示
| Unicode编码16进制 | Unicode编码2进制 |
|---|---|
| 9664 | 1001 0110 0110 0100 |
| 5915 | 0101 1001 0001 0101 |
结合关系表查找到对应行:

将Unicode编码二进制表示带入可得:

最终,在URL中显示的编码
| 字符 | 编码 |
|---|---|
| 除 | %E9%99%A4 |
| 夕 | %E5%A4%95 |
写在最后
在Python中处理url时,常调用urllib库的unquote类处理含有中文URL时,匹配中文字符串常常就会遇到处理编码的问题,此处也是在解码和使用正则表达式进行文本过滤时发现的问题,解决URL中中文文本筛选的问题可以尝试一下思路:
- 调用unquote类,按照UTF-8方式解码
- 使用正则表达式匹配所有中文字符,匹配串为:[\u4e00-\u9fa5]
通过这样的方式,将原有的由百分号(%)作为分隔符作为边界标志的特殊字符,转换成一般的文本字符UTF-8,即\uxxxx格式,便能够很容易找到对应的正则表达式将其中中文字符找到。
补充:
URL编码遵循下列规则: 每对name/value由&;符分开;每对来自表单的name/value由=符分开。如果用户没有输入值给这个name,那么这个name还是出现,只是无值。任何特殊的字符(就是那些不是简单的七位ASCII,如汉字)将以百分符%用十六进制编码,当然也包括象 =,&;,和 % 这些特殊的字符。其实url编码就是一个字符ascii码的十六进制。不过稍微有些变动,需要在前面加上“%”。比如“\”,它的ascii码是92,92的十六进制是5c,所以“\”的url编码就是%5c。
