目录
1.基于度量分析自己的程序结构
(1)第一次作业
UML
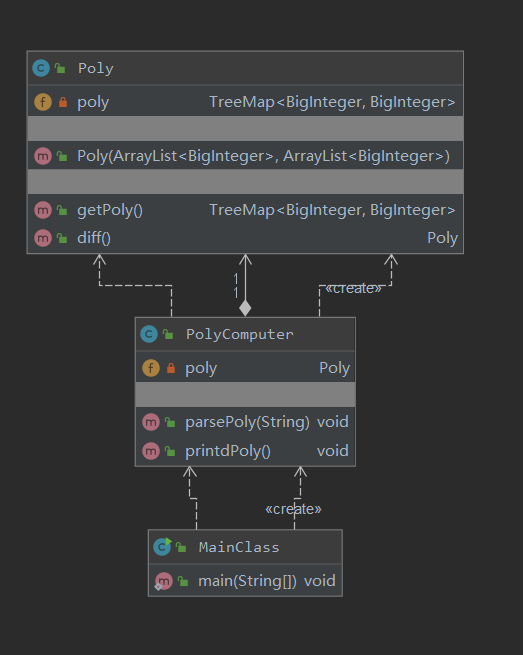
第一次作业结构非常简单,除了MainCLass外,只用PolyComputer类负责解析表达式生成Poly类的实例。
代码分析
对于类,有OCavg和WMC两个项目,分别代表类的方法的平均循环复杂度和总循环复杂度。

可以见得:第一次作业主要是PolyComputer类的复杂度比较高,因为笔者第一次作业是直接在parsePoly方法里直接使用一个大正则来解析表达式。在printPoly方法里直接使用了多个逻辑关系复杂的if分支来输出表达式。
(2)第二次作业
UML

由上图可见,第二次作业比第一次作业复杂了很多很多。这是因为笔者在第二次作业中进行了重构,并为第三次作业的括号嵌套留下所有将来需要用到的接口。
笔者知道有一些同学是把判断表达式是否合法和解析表达式放在一起的;将表达式求导和输出表达式放在一起。
但笔者并不赞同这样的设计思路,这样容易导致:
- 方法或类的内部逻辑复杂,容易出bug;
- 程序可读性差;
- 难以维护和扩展;
- 难以进行白盒测试
笔者坚持不因为效率而牺牲程序可读性的设计思想,将整个复杂过程分解为四个部分。
- 判断表达式是否合法
- 解析表达式并生成对应类
- 表达式求导
- 输出表达式
实际上笔者的类设计逻辑自认为还是非常清晰的,笔者并没有采用同学们常用的二叉树。而是使用多叉树。多叉树只有三层,第一层是一个根结点Exp类,第二层是n个Term类,每个Term类下面又有m个Factor类。
另外第二次作业为了简化合并的过程,采用了Triple类表示一个Term类中常数项以及sin和cos的指数。
采用多叉树而不是二叉树的原因如下:
- 从数学角度,一个表达式中的Term之间具有交换律,他们之间地位平等;一个Term的Factor之间也具有交换律,他们之间地位平等。
- 从类设计角度,树的同一层的所有实例都来自于同样一个(抽象)类层次更清晰。
- 从表达式的求导和化简角度,多叉树比二叉树更容易求导和化简,且化简效果更好。
代码分析

由此可见,虽然第二次作业的代码量虽然是第一次作业的四五倍,但是由于合理的分层和解耦合的类设计,方法的复杂度反而大大降低了。
(3)第三次作业
UML
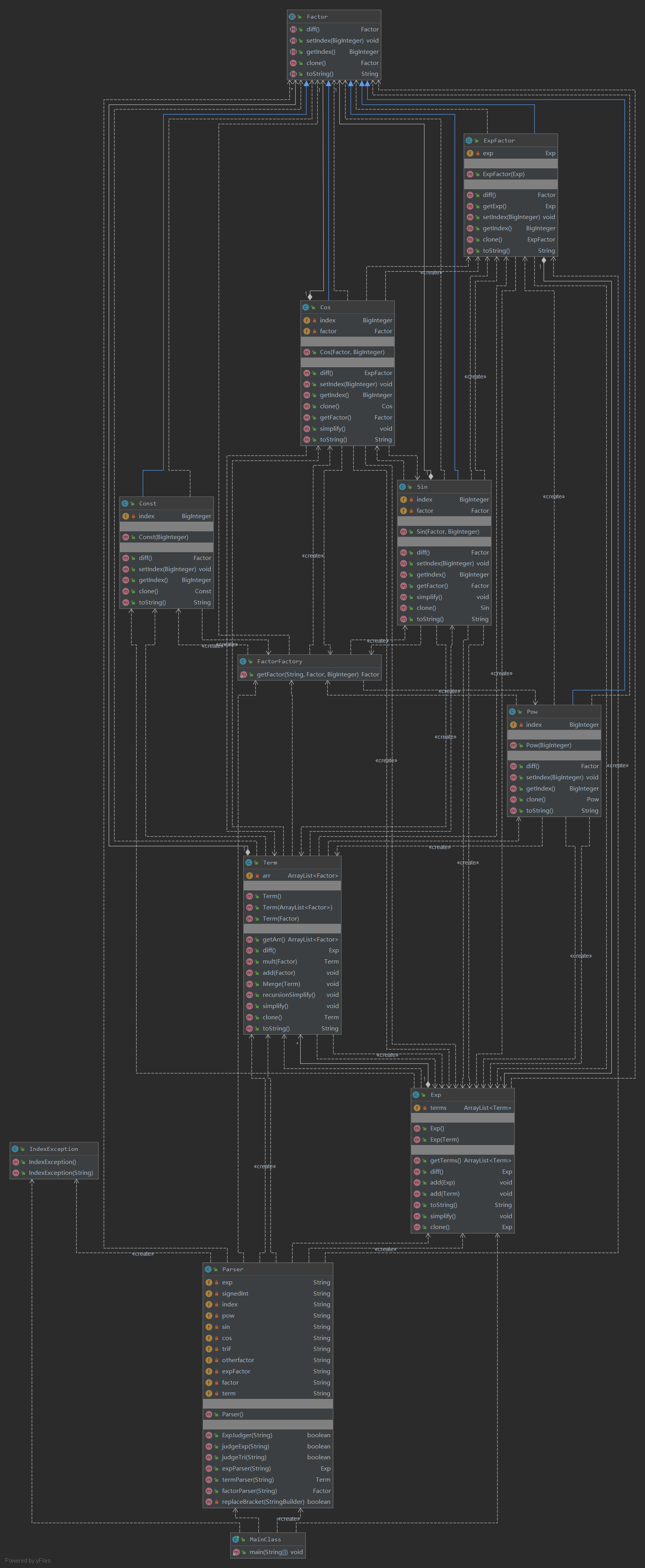
第三次作业相对于第二次作业几乎没有架构上的修改,仍然采用三层的多叉树结构。只是将Term类中的Triple类换为更一般的ArrayList
代码分析
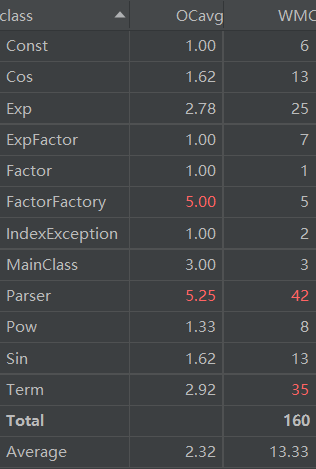
虽然第三次作业比第二次作业的难度更大,实现更复杂。但是由于笔者良好的分层设计和第二次留下的充足的扩展接口,第三次作业的方法复杂度相较于第二次作业几乎没有变化,甚至降低了一点。
2.分析自己程序的bug
三次作业中,我只在第三次作业中存在bug,bug出现的原因是我为了缩短输出长度,将输出中所有的x**2换成了x*x,而当幂函数因子x**2作为三角函数的内嵌因子时,将其换为表达式x*x后得到的表达式是非法的。
仔细分析这次出错的原因:
设计结构方面:正如文章第一部分所说,我的第二三次作业的架构是十分清晰的,将整个过程解耦合为判断表达式的合法性、解析表达式生成Exp|Item|Factor类、表达式求导、表达式输出四部分。bug只与第四部分表达式输出有关,具体问题出在了Pow类的String方法。只需注释掉将x**2换成x*x的那一行代码即可。
测试方面:三次作业中本人都写了自动对拍机。但为何自动对拍机没能监测出第三次作业的bug呢?因为我的对拍机直接使用Sympy求导核对数值,并没有检验输出的表达式的合法性。这是一个教训,仔细阅读指导书时我本应该读到“输出表达式也要求符合形式化表述”,就应该对输出表达式也进行形式化检验。
3.分析自己发现别人程序bug所采用的策略
我发现别人bug的策略是以自己构造的有针对性的测试数据和自动测试机两者并行。
自己构造的测试数据笔者留待第五部分再详述。自动测试机一开始是随机生成表达式;之后也会通过对正则的调整生成很多有针对性的数据。
4.应用对象创建模式
第一次作业十分简单,笔者为了省事没用采用任何模式。然后第二次作业笔者设计了三层多叉树,在第三层中全是Factor类,因此笔者也采用工厂方法模式来创建和管理Factor类。定义了Factory接口,各个因子的工厂类并实现接口。但在处理Factor类时,笔者并未采用接口而是采用抽象类Factor,子类Sin、Pow等继承抽象类。
5.对比与心得体会
(1)通过合理的类设计解耦合
正如在第一部分分析的,笔者通过对合理的类设计实现对过程的分层和分解。这就是作者目前理解到的面向对象程序设计(可能还过于浅薄)。笔者感觉通过类设计实现过程分层和分解的思路十分好用,很容易设计出逻辑清晰,可读性强,便于维护的代码。
(2)如何构造数据和测试
分为以下步骤:
在动手写代码前先依照指导书构造有针对性的测试数据集;在coding前就构造数据集有助于理解程序易出错的地方,减少写代码时的bug。
在写代码时可能还会额外想到其他针对性数据,增加到数据集里面。
白盒测试。笔者每写完一个功能独立的模块,都会对此模块进行白盒测试。
通过Python实现自动测试。
其实还可以采用小黄鸭测试法等等......
(3)递归
本次作业极大地加深了笔者对递归的理解...特别是笔者此次设计了一个相互递归调用的逻辑:解析表达式时调用三角函数的因子的解析方法,解析三角函数的因子时调用表达式的解析方法。具体如下图。
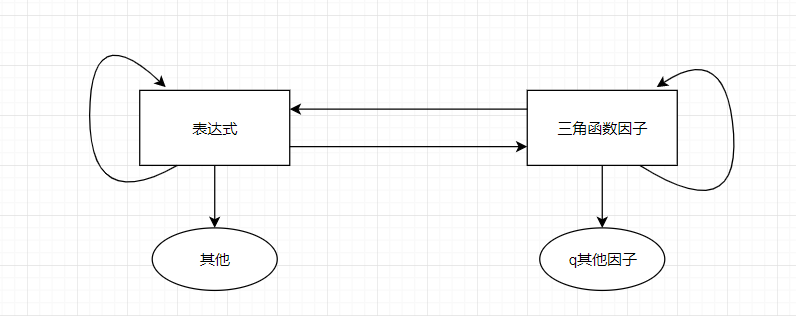
求导过程亦是如上所述的相互递归调用;甚至化简过程也是相互递归调用。
本次对递归的理解:
1.递归需要形成一个调用环:自己调用自己,或者自己调用别人,别人再调用自己。
2.递归需要有一个出口,如上图的圆圈。
以后使用递归时,只需要画出如上所示的递归调用图,就可以思路清晰地完成。